今回の記事では、時系列分析が簡単に実装できるDartsについて紹介します。
Google colabを使用して、簡単にモデルを実装することができますので、ぜひ最後までご覧ください。
今回の内容
・時系列分析とは
・Dartsとは
・Dartsの導入
・データセットを準備する
・データセットの前処理
・モデルの実装例
時系列分析とは
時系列分析とは、時間の経過とともに変化する時系列データを分析することをいいます。
時系列データの具体例として、気温や降水状況などの気象情報、交通機関の乗客の推移、株価のチャートなど身近な場所に多く存在しています。
時系列分析において、データの変動の原因は以下のように分類されます。
| 1 | 長期的な上昇/下降の傾向性を指す「トレンド」 |
| 2 | 1年の間で一定期間ごとに周期的に変化する「季節変動」 |
| 3 | 複数年にまたがって周期的に変化する「循環変動」 |
| 4 | 周期性や規則的な傾向性が見られない「不規則変動」 |
次系列分析は、日々の株価の変動や将来の市場規模の変化、売上実績の予想などに多くの場面で役立てられています。
Dartsとは
Dartsは時系列分析の実装を簡単に行えるPython ライブラリです。
ARIMAをはじめとした古典的なモデルからディープラーニングによる最新手法までさまざまなモデルに対応しており、学習から推論までを簡単に実装することができます。
単変量と多変量の両方の時系列とモデルをサポートしています。
詳細は以下のリンクからご確認ください。
公式実装:https://github.com/unit8co/darts
サポート:https://unit8co.github.io/darts/quickstart/00-quickstart.html
Dartsの導入
ここからはGoogle colabを使用して、次系列分析を実装していきます。
今回紹介するコードは以下のボタンからコピーして使用していただくことも可能です。
![]()
Google colabによる導入
まずはGoogleドライブをマウントして、作業フォルダを作成します。
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive公式からクローンします。
!git clone https://github.com/unit8co/darts
%cd darts必要なライブラリをインストールします。
!pip install dartsインストールが終わったら、再起動します。
以上で導入が終わりました。
※pipのみで使用することができますが、サンプル用のCSVデータセットを使用するため、公式からクローンしています。
データセットを準備する
時系列データを読み込む方法は以下の通りです。
darts.datasetsからデータを読み込む
Dartsのデータセットから直接読み込むことができます。
まずは飛行機の乗客の推移を表すデータを読み込みます。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from darts import TimeSeries
from darts.datasets import AirPassengersDataset
# dartsから直接データセットをダウンロードする
series = AirPassengersDataset().load()
series.plot()実行すると以下のようなグラフが表示されます。
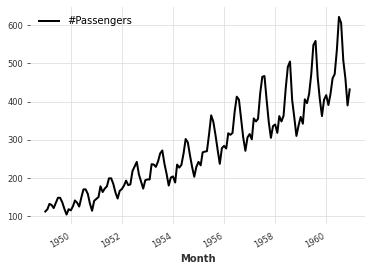
CSVファイルからデータを読み込む
次にCSVファイルからデータセットを読み込む方法を紹介します。
先ほど読み込んだDartsのデータセットである、飛行機の乗客の推移を表す「AirPassengers.csv」というファイルを読み込み、内容を表示してみます。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from darts import TimeSeries
# CSVファイルからデータセットをダウンロードする
df = pd.read_csv("datasets/AirPassengers.csv", delimiter=",")
df実行すると、以下のように表示されます。
| index | Month | #Passengers |
|---|---|---|
| 0 | 1949-01 | 112 |
| 1 | 1949-02 | 118 |
| 2 | 1949-03 | 132 |
| 3 | 1949-04 | 129 |
| 4 | 1949-05 | 121 |
| 140 | 1960-09 | 508 |
| 141 | 1960-10 | 461 |
| 142 | 1960-11 | 390 |
| 143 | 1960-12 | 432 |
1ヶ月ごとの乗客数のデータセットであることがわかりました。
同様にグラフで表してみます。
series = TimeSeries.from_dataframe(df, "Month", "#Passengers")
series.plot()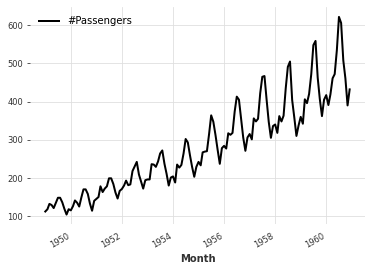
先ほど同じグラフになっていることがわかります。
時系列データから表形式データへ変換
ここまで表形式データから時系列データに変換する方法を紹介しましたが、逆にもとに戻すこともできます。
TimeSeries.pd_dataframe()メソッドにより、時系列データから表形式データへ変換することができます。
TimeSeries.pd_dataframe(series)データセットの前処理
ここからは前処理の方法を紹介します。
比率でデータを分割
時系列データを分割することができます。
以下の例では、全体を0.75の位置で分割します。
series1, series2 = series.split_before(0.75)
series1.plot()
series2.plot()実行すると、以下のようなグラフが出力されます。
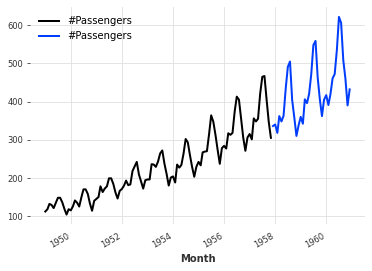
グラフが0.75の位置で分割され、前半が黒色、後半が青色になっていることがわかります。
分割したデータを表示することもできます。
TimeSeries.pd_dataframe(series1).tail()実行すると、分割したデータを表形式で出力することができます。
| Month | #Passengers |
|---|---|
| 1957-07-01 00:00:00 | 465.0 |
| 1957-08-01 00:00:00 | 467.0 |
| 1957-09-01 00:00:00 | 404.0 |
| 1957-10-01 00:00:00 | 347.0 |
| 1957-11-01 00:00:00 | 305.0 |
分割位置を指定してデータを分割
次に分割位置を指定してデータを分割する方法を紹介します。
以下の例では、全体を後ろから36番目の位置で分割します。
series1, series2 = series[:-36], series[-36:]
series1.plot()
series2.plot()実行すると、以下のようなグラフが出力されます。
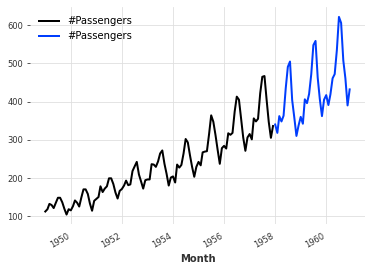
グラフが全体を後ろから36番目の位置で分割され、前半が黒色、後半が青色になっていることがわかります。
学習データと検証データに分割
学習データと検証データに分割します。
以下の例では、全体を1958年1月で分割します。
train, val = series.split_before(pd.Timestamp("19580101"))
train.plot(label="training")
val.plot(label="validation")実行すると、以下のようなグラフが出力されます。
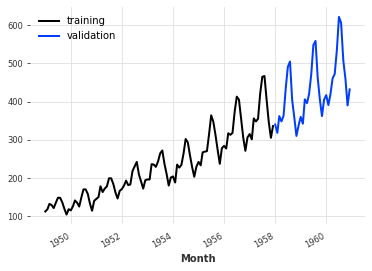
季節変動性を確認する
データの特徴を掴むため、季節変動性の確認を行います。
for m in range(2, 25):
is_seasonal, period = check_seasonality(train, m=m, alpha=0.05)
if is_seasonal:
print("There is seasonality of order {}.".format(period))実行すると、以下のように表示されます。
There is seasonality of order 12.12次の季節変動性があることがわかりました。
自己相関関数 (ACF) のラグも表示することができます。
from darts.utils.statistics import plot_acf, check_seasonality
plot_acf(train,alpha=0.05)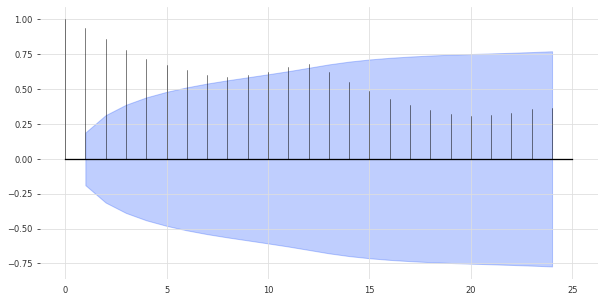
モデルの実装例
ここからは指数平滑法予測を例に、モデルの実装例を紹介していきます。
先ほど分割した学習データと検証データを用いて、予測を行います。
from darts.models import ExponentialSmoothing
from darts.metrics import mape
def eval_model(model):
model.fit(train)
forecast = model.predict(len(val))
print("model {} obtains MAPE: {:.2f}%".format(model, mape(val, forecast)))
series.plot()
forecast.plot(label='forecast')
return TimeSeries.pd_dataframe(forecast)
eval_model(ExponentialSmoothing())実行すると以下のような結果とグラフおよび表が出力されます。
model ExponentialSmoothing(
trend=ModelMode.ADDITIVE,
damped=False,
seasonal=SeasonalityMode.ADDITIVE,
seasonal_periods=12 obtains MAPE: 5.11%グラフ
黒色が元のデータ、青色が予測のデータになっています。
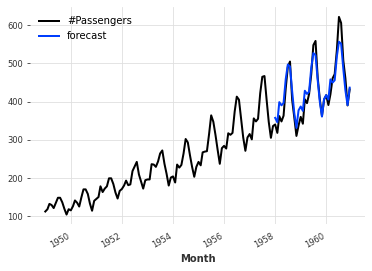
表
それぞれの予測の値を確認することができます。
| Month | #Passengers |
|---|---|
| 1958-11-01 00:00:00 | 331.07829886018783 |
| 1958-02-01 00:00:00 | 345.8201686361798 |
| 1958-01-01 00:00:00 | 357.3323525767953 |
| 1959-11-01 00:00:00 | 360.88592543149036 |
| 1958-10-01 00:00:00 | 370.2797224292205 |
| 1959-02-01 00:00:00 | 375.62779520748234 |
| 1958-12-01 00:00:00 | 376.95827329776637 |
| 1959-01-01 00:00:00 | 387.1399791480979 |
| 1958-04-01 00:00:00 | 390.1919947229418 |
| 1960-11-01 00:00:00 | 390.6935520027929 |
MAPE
MAPE(Mean Absolute Percentage Error)は平均絶対パーセント誤差のことです。
各データに対して「予測値と正解値との差を、正解値で割った値(=パーセント誤差)」の絶対値を計算し、その総和をデータ数で割った値(=平均値)を出力します。
時系列予測の評価関数として用いられます。
上記の結果では、MAPEは5.11%でした。
まとめ
最後までご覧いただきありがとうございました。
今回の記事では時系列分析が簡単に実装できるDartsについて紹介しました。

