・Retrieval-Augmented Language Model (RALM)は、大規模な言語モデル(LLM)に外部知識を取り込むことで性能向上を図る技術。
・RALMは、Retriever(検索器)とLanguage Model(言語モデル)の2つのコンポーネントから構成され、それらの連携方法には3通りある。
・Retrieverには4つの種類があり、Language Modelには3つのタイプがある。それぞれの特徴や利点・欠点が比較されている。
・RALMの性能をさらに高めるための改善手法も多数提案されており、自然言語生成(NLG)と自然言語理解(NLU)の両方のタスクに適用可能。
・RALMの研究はまだ発展途上だが、そのポテンシャルは高く、自然言語処理の分野に革新をもたらす可能性がある。今後のさらなる発展が期待される。
近年の自然言語処理(NLP)の分野では、大規模な言語モデル(Large Language Models: LLMs)の登場により、飛躍的な性能向上が見られています。しかし、LLMsにも「幻覚」と呼ばれる誤った知識の生成や、ドメイン固有の知識不足などの課題があることが指摘されています。
そこで注目を集めているのが、Retrieval-Augmented Language Model(RALM)と呼ばれる技術です。RALMとは、LLMsに外部の知識を取り込むことで、性能向上を図るアプローチのことを指します。最近発表された論文「RAG and RAU: A Survey on Retrieval-Augmented Language Model in Natural Language Processing」では、RALMの全体像が丁寧に解説されています。
RALMの基本アーキテクチャ
RALMは大きく分けて、Retriever(検索器)とLanguage Model(言語モデル)の2つのコンポーネントから構成されます。Retrieverは外部知識を検索し、Language Modelはそれを利用して言語生成や理解のタスクを行います。
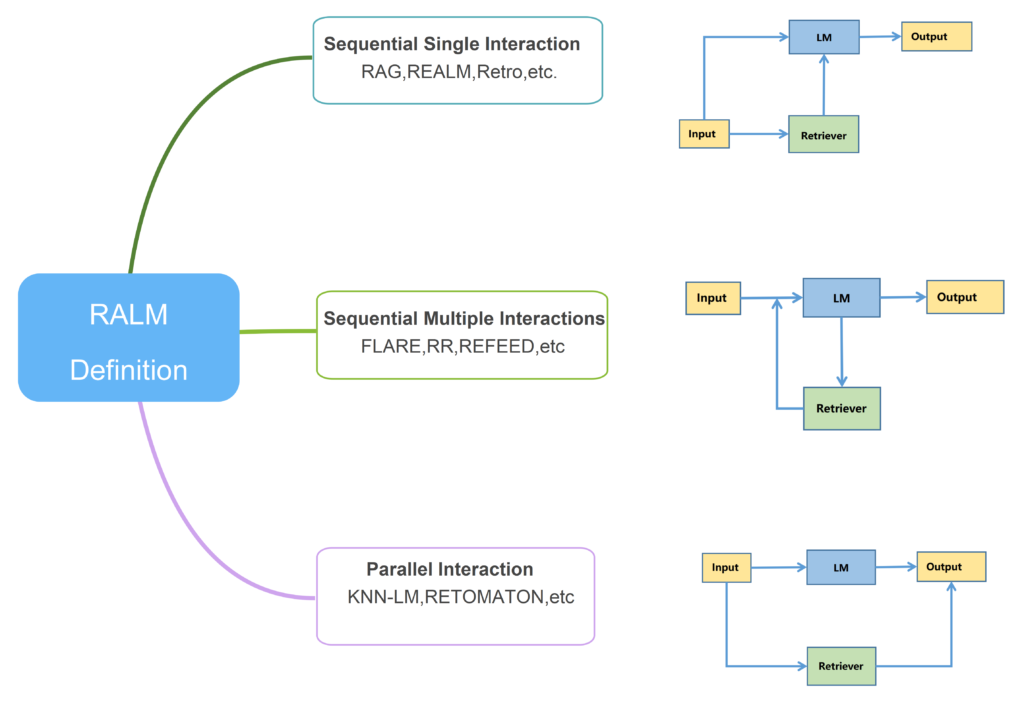
この2つのコンポーネントの連携方法には、次の3通りがあるとのことです。
- Sequential Single Interaction(逐次的単一インタラクション): Retrieverで検索した情報をLanguage Modelに渡す
- Sequential Multiple Interactions(逐次的複数インタラクション): Retrieverで検索した情報を何度もLanguage Modelに渡す
- Parallel Interaction(並列的インタラクション): RetrieverとLanguage Modelを並列に動作させる
どの方式を採用するかは、タスクやドメインに応じて適切に選択する必要があります。
Retrieverの種類
Retrieverには大きく分けて4つの種類があります。
- Sparse Retriever(スパース検索): TF-IDFやBM25などの古典的な検索手法
- Dense Retriever(デンス検索): 深層学習を用いた検索手法
- Internet Retrieval(Web検索): インターネット上の情報を検索
- Hybrid Retrieval(ハイブリッド検索): 上記の手法を組み合わせる
論文では、それぞれの手法の特徴や利点・欠点が詳しく比較されています。用途に応じた使い分けが重要だと言えるでしょう。
Language Modelの種類
RALMで用いられるLanguage Modelには主に3つのタイプがあります。
- AutoEncoder Language Model(自己符号化言語モデル): BERTに代表される双方向のTransformerモデル
- AutoRegressive Language Model(自己回帰言語モデル): GPTに代表される単方向のTransformerモデル
- Encoder-Decoder Language Model(エンコーダ・デコーダ言語モデル): T5やBARTに代表される、エンコーダとデコーダを組み合わせたモデル
論文では各モデルの特徴や適した用途などが丁寧に解説されています。
RALMの性能改善手法
RALMの性能をさらに高めるための改善手法も数多く提案されています。例えば、
- Retrieverの検索品質を向上させる
- Retrieverの検索タイミングを最適化する
- 事前学習済みのLanguage Modelを活用する
- Language Modelの構造を工夫する
- 生成されたテキストを後処理する
などが挙げられます。論文ではそれぞれの具体的な手法や効果が紹介されています。
RALMのアプリケーション
RALMは自然言語生成(NLG)と自然言語理解(NLU)の両方のタスクに適用可能です。
NLGのタスクでは、
- 機械翻訳
- 対話生成
- 数学の問題作成
などが挙げられます。一方、NLUのタスクでは、
- スロットフィリング
- 画像生成
- ファクトチェック
- ナレッジグラフ補完
- 常識推論
などへの応用が期待されています。
また、要約やQA、コード生成など、NLGとNLUの両方の要素を含むタスクもあります。RALMの活用シーンは非常に幅広いと言えるでしょう。
RALMの課題と今後の展望
RALMの研究はまだ発展途上の段階で、多くの課題が残されています。例えば、
- Retrieverの検索品質をさらに高める
- 計算コストを削減する
- 実用的なアプリケーションを開発する
などが必要とされています。
また、RALMの頑健性やロバスト性を評価するための新しい指標やベンチマークの確立も求められています。
とはいえ、RALMのポテンシャルは非常に高く、今後のさらなる発展が大いに期待されます。自然言語処理の分野に革新をもたらす技術となるかもしれません。
