・大規模言語モデルの微調整で新しい知識を導入すると、事前知識に基づかない幻覚的な応答が増加する可能性がある。
・研究では、未知の例から学習することは幻覚傾向と相関し、既知の例から学習することは事前知識の活用と相関することが分かった。
・適切な微調整には、HighlyKnownカテゴリーの例だけでなくMaybeKnownの例も取り入れることが重要であり、LLMの知識獲得と活用メカニズムの理解が必要。
大規模言語モデル(LLM)は事前学習によって膨大な知識を獲得しています。しかし、指示に従うタスクで教師あり微調整する際、事前学習で得られなかった新しい事実情報に遭遇することがあります。LLMが微調整で新しい事実を学ぶと、事前知識に基づかない事実を生成するよう訓練されるため、事実と異なる幻覚的な応答を促す可能性があると考えられています。
本研究の目的と手法
この研究では、微調整時の新しい知識への曝露が、微調整後のモデルの事前知識の活用能力にどのような影響を与えるかを調査しました。
著者らは以下のような手法で研究を行いました。
- 質問応答タスクに焦点を当て、新しい知識を導入する微調整例の割合を変化させる統制された実験設定を設計
- SliCKという4つの知識カテゴリーの階層を提案し、モデル生成答えとラベルの一致度を定量化
- 線形回帰モデルを用いて、学習済みの既知/未知の訓練例がテスト精度に与える影響を評価
主な発見
- 微調整で未知の例から学習することは、モデルの事前知識に対する幻覚傾向と線形に相関
- 既知の例から学習することは、事前知識のより良い活用と相関
- LLMは未知の微調整例を既知の例よりもかなり遅く適合させる。事前学習で知識を獲得し、微調整ではその知識を効率的に使用することを学ぶ
- モデルが未知の例を最終的に学習すると、事前知識に対する幻覚が直線的に増加
- 未知の微調整例はニュートラルまたは有害な影響を与える可能性がある
- 知識の程度が最も高いHighlyKnownカテゴリーの例だけでは最良の結果が得られない。MaybeKnownの例を組み込むことが重要
微調整における新しい知識の影響
図3は未知の例の割合とテスト性能の関係を示しています。未知の例の割合が高いほどテスト性能が低下し、過学習のリスクが高まることがわかります。
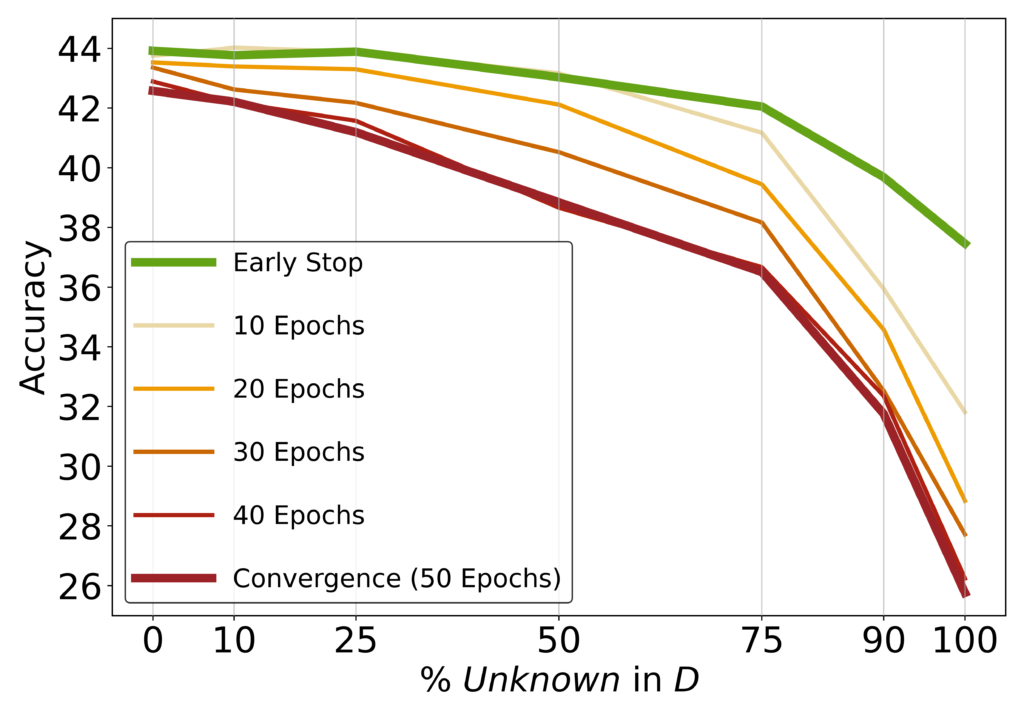
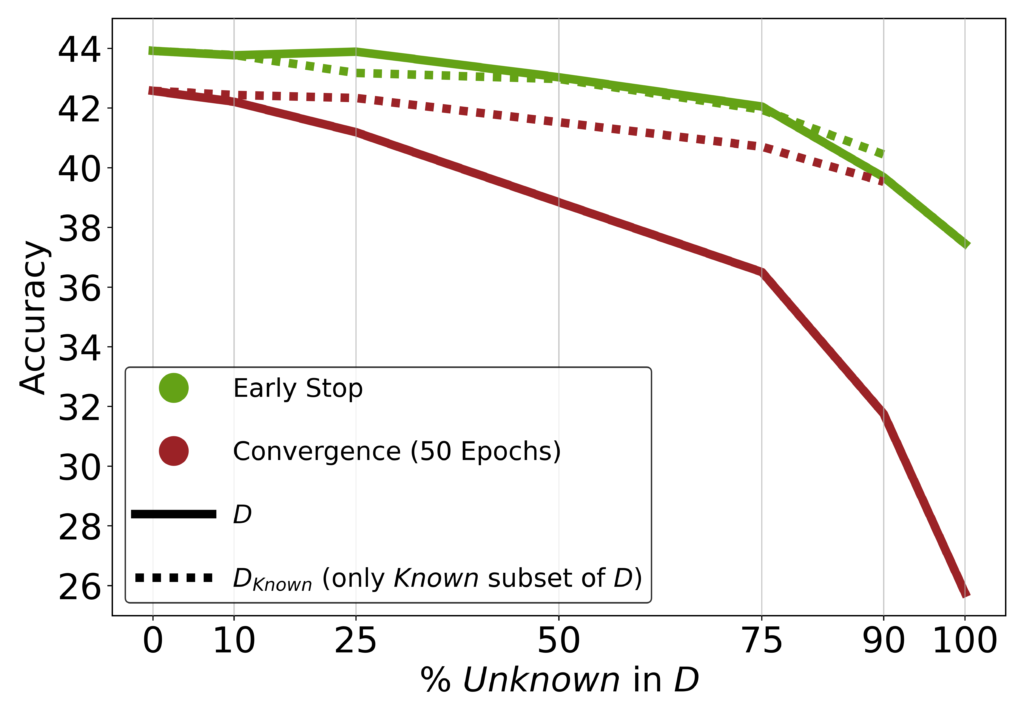
この研究から、教師あり微調整を通じて新しい事実知識を更新することのリスクが浮き彫りになりました。LLMは微調整によって新しい知識を統合するのに苦労しており、事前学習によって知識を獲得し、微調整によってその知識をより効率的に使用することを学ぶという見方を支持する結果となっています。
微調整における新しい知識の影響
知識カテゴリー別の微調整例がテスト性能に与える影響を調査しました。
驚くべきことに、知識度が最も高いHighlyKnownカテゴリーの例だけでは最良の結果が得られず、MaybeKnownの例を取り入れることが重要であることがわかりました。これは、MaybeKnownの微調整例がテスト時にそのような例を適切に処理するために不可欠であることを示唆しています。
まとめ
本研究は、LLMの知識獲得と活用における微調整の役割について重要な洞察を提供しています。微調整時の新しい知識の導入は幻覚のリスクをはらんでおり、LLMは事前学習で知識を獲得し、微調整ではその知識の活用を強化するメカニズムとしてより有用である可能性を示唆しています。
