今回の記事では、時系列分析が簡単に実装できるDartsについて紹介します。
Google colabを使用して、簡単にモデルを実装することができますので、ぜひ最後までご覧ください。
今回の内容
・時系列分析とは
・Dartsとは
・Dartsの導入
・モデルの実装
・未来予測の実装
時系列分析とは
時系列分析とは、時間の経過とともに変化する時系列データを分析することをいいます。
時系列データの具体例として、気温や降水状況などの気象情報、交通機関の乗客の推移、株価のチャートなど身近な場所に多く存在しています。
時系列分析において、データの変動の原因は以下のように分類されます。
| 1 | 長期的な上昇/下降の傾向性を指す「トレンド」 |
| 2 | 1年の間で一定期間ごとに周期的に変化する「季節変動」 |
| 3 | 複数年にまたがって周期的に変化する「循環変動」 |
| 4 | 周期性や規則的な傾向性が見られない「不規則変動」 |
次系列分析は、日々の株価の変動や将来の市場規模の変化、売上実績の予想などに多くの場面で役立てられています。
Dartsとは
Dartsは時系列分析の実装を簡単に行えるPython ライブラリです。
ARIMAをはじめとした古典的なモデルからディープラーニングによる最新手法までさまざまなモデルに対応しており、学習から推論までを簡単に実装することができます。
単変量と多変量の両方の時系列とモデルをサポートしています。
詳細は以下のリンクからご確認ください。
公式実装:https://github.com/unit8co/darts
サポート:https://unit8co.github.io/darts/quickstart/00-quickstart.html
前回の記事ではDartsの基本的な使い方を紹介しています。
ぜひ合わせてご覧ください。
🔰Dartsではじめる時系列分析入門
今回の記事では、時系列分析が簡単に実装できるDartsについて紹介します。 Google colabを使用して、簡単にモデルを実装することができますので、ぜひ最後までご覧くださ…

Dartsの導入
ここからはGoogle colabを使用して、次系列分析を実装していきます。
今回紹介するコードは以下のボタンからコピーして使用していただくことも可能です。
![]()
Google colabによる導入
まずはGoogleドライブをマウントして、作業フォルダを作成します。
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive公式からクローンします。
!git clone https://github.com/unit8co/darts
%cd darts必要なライブラリをインストールします。
!pip install dartsインストールが終わったら、再起動します。
以上で導入が終わりました。
※pipのみで使用することができますが、サンプル用のCSVデータセットを使用するため、公式からクローンしています。
データセットを準備する
データセットの読み込み
まずは飛行機の乗客の推移を表すデータを読み込みます。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from darts import TimeSeries
# CSVファイルからデータセットをダウンロードする
df = pd.read_csv("datasets/AirPassengers.csv", delimiter=",")
series = TimeSeries.from_dataframe(df, "Month", "#Passengers")
series.plot()実行すると以下のようなグラフが表示されます。
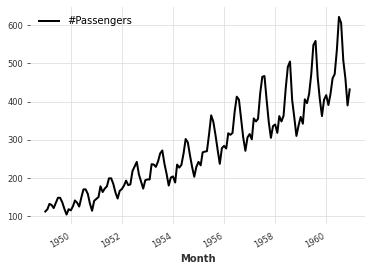
データの内容は以下の通りとなっています。
| index | Month | #Passengers |
|---|---|---|
| 0 | 1949-01 | 112 |
| 1 | 1949-02 | 118 |
| 2 | 1949-03 | 132 |
| 3 | 1949-04 | 129 |
| 4 | 1949-05 | 121 |
| 140 | 1960-09 | 508 |
| 141 | 1960-10 | 461 |
| 142 | 1960-11 | 390 |
| 143 | 1960-12 | 432 |
学習データと検証データに分割
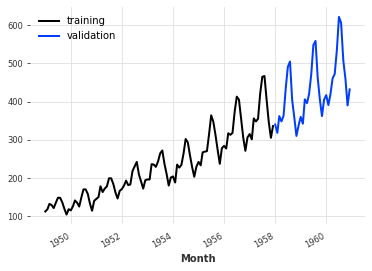
学習データと検証データに分割します。
以下の例では、全体を1958年1月で分割します。
train, val = series.split_before(pd.Timestamp("19580101"))
train.plot(label="training")
val.plot(label="validation")実行すると、以下のようなグラフが出力されます。
モデルの実装
ここからはいくつかのモデルを実装してみます。
Dartsを使うと、1つのデータセットに対して複数のモデルを簡単に実装することができます。
以下の例では「ExponentialSmoothing」、「TBATS」、「AutoARIMA」、「Theta」の4つのモデルの結果を出力します。
from darts.models import ExponentialSmoothing, TBATS, AutoARIMA, Theta
from darts.metrics import mape
def eval_model(model):
model.fit(train)
forecast = model.predict(len(val))
print("model {} obtains MAPE: {:.2f}%".format(model, mape(val, forecast)))
eval_model(ExponentialSmoothing())
eval_model(TBATS())
eval_model(AutoARIMA())
eval_model(Theta())実行すると以下のような結果が出力されます。
model ExponentialSmoothing(trend=ModelMode.ADDITIVE, damped=False, seasonal=SeasonalityMode.ADDITIVE, seasonal_periods=12 obtains MAPE: 5.11%
model (T)BATS obtains MAPE: 5.87%
model Auto-ARIMA obtains MAPE: 11.65%
model Theta(2) obtains MAPE: 8.15%4つのモデルの精度を簡単に比較することができました。
ここからは、それぞれのモデルについて詳細な結果を見ていくことにします。
ExponentialSmoothing(指数平滑法)
ExponentialSmoothing(指数平滑法)は時系列データを平滑化する代表的な時系列分析手法の一つです。
観測値の中でより新しいデータに大きな重みを設定し、過去になるほど指数関数的に重みを減少させた期待値 (移動平均) を算出します。
直近の観測値の変動に従属させたいような比較的短期間の期待値を決めるのに適した手法です。
from darts.models import ExponentialSmoothing
from darts.metrics import mape
def eval_model(model):
model.fit(train)
forecast = model.predict(len(val))
print("model {} obtains MAPE: {:.2f}%".format(model, mape(val, forecast)))
series.plot()
forecast.plot(label='forecast')
return TimeSeries.pd_dataframe(forecast)
eval_model(ExponentialSmoothing())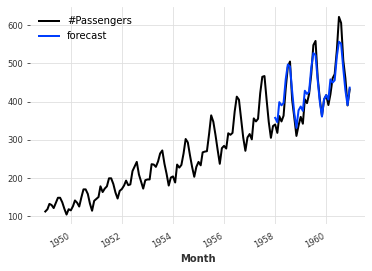
トレンド、季節性などのハイパーパラメータを設定することができます。
詳細はこちらのドキュメントをご覧ください。
from darts.utils.utils import ModelMode
from darts.utils.utils import SeasonalityMode
eval_model(ExponentialSmoothing(trend=ModelMode.ADDITIVE, damped=False, seasonal=SeasonalityMode.ADDITIVE, seasonal_periods=None, random_state=0))TBATS
TBATSは指数平滑法をもとにした、複数の季節性をもつ時系列モデルです。
①三角関数による季節性表現(Trigonometric seasonality)、②Box-Cox変換(Box-Cox transformation)、③ARIMA誤差(ARMA error)、④トレンド成分(Trend component)、⑤季節成分(Seasonal component)の5つの頭文字を取った名前になっています。
複数の季節期間、高頻度の季節性、非整数の季節性、二重カレンダー効果などの複雑な季節時系列に用いられます。
from darts.models import TBATS
from darts.metrics import mape
def eval_model(model):
model.fit(train)
forecast = model.predict(len(val))
print("model {} obtains MAPE: {:.2f}%".format(model, mape(val, forecast)))
series.plot()
forecast.plot(label='forecast')
return TimeSeries.pd_dataframe(forecast)
eval_model(TBATS())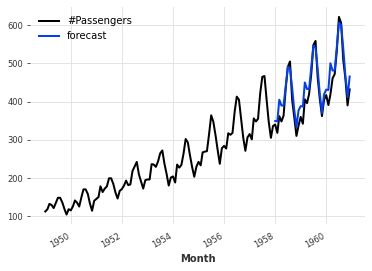
トレンド、季節性などのハイパーパラメータを設定することができます。
詳細はこちらのドキュメントをご覧ください。
AutoARIMA
ARIMAはAuto-Regressive Integrated Moving Average Modelの頭文字をとったものです。
①AR (Auto-Regressive) component:自己回帰成分、②I (Integrated) component:和分成分、③MA (Moving Average) component:移動平均成分の3つの成分から構成されます。
AutoARIMAでは、AIC・AICc・BICのいずれかの値に従って、最適なARIMAモデルを返します。
from darts.models import AutoARIMA
from darts.metrics import mape
def eval_model(model):
model.fit(train)
forecast = model.predict(len(val))
print("model {} obtains MAPE: {:.2f}%".format(model, mape(val, forecast)))
series.plot()
forecast.plot(label='forecast')
return TimeSeries.pd_dataframe(forecast)
eval_model(AutoARIMA())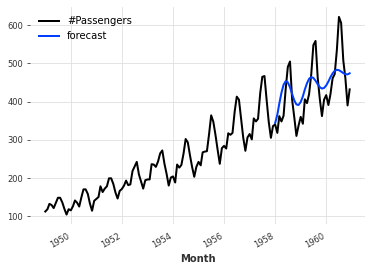
AutoARIMAでは様々なハイパーパラメータを設定することができます。
詳細はこちらのドキュメントをご覧ください。
Theta法
Theta法はドリフト付きの単純指数平滑化法のモデルといえます。
from darts.models import Theta
from darts.metrics import mape
def eval_model(model):
model.fit(train)
forecast = model.predict(len(val))
print("model {} obtains MAPE: {:.2f}%".format(model, mape(val, forecast)))
series.plot()
forecast.plot(label='forecast')
return TimeSeries.pd_dataframe(forecast)
eval_model(Theta())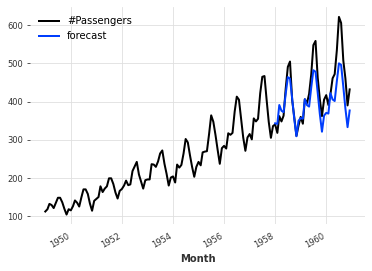
Theta法におけるハイパーパラメータの探索
Theta法におけるハイパーパラメータの調整を自動で行うことができます。
適切な値を見つけてみましょう。
thetas = 2 - np.linspace(-10, 10, 50)
best_mape = float("inf")
best_theta = 0
for theta in thetas:
model = Theta(theta)
model.fit(train)
pred_theta = model.predict(len(val))
res = mape(val, pred_theta)
if res < best_mape:
best_mape = res
best_theta = theta最適な値によるモデルの実装を行います。
best_theta_model = Theta(best_theta)
best_theta_model.fit(train)
pred_best_theta = best_theta_model.predict(len(val))
print(
"The MAPE is: {:.2f}, with theta = {}.".format(
mape(val, pred_best_theta), best_theta
)
)実行すると、以下のような結果が出力されます。
The MAPE is: 4.40, with theta = -3.5102040816326543.結果を図示します。
train.plot(label="train")
val.plot(label="true")
pred_best_theta.plot(label="prediction")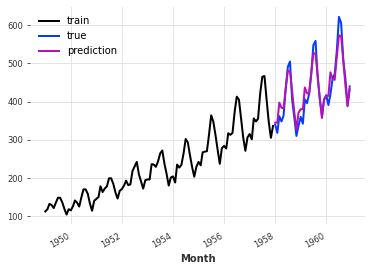
未来予測の実装
最後に未来予測を実装してみましょう。
ExponentialSmoothing(指数平滑法)
まずは指数平滑法による予測です。
予測期間をforecast = model.predict(n=48)で指定します。
以下の例では、48ヶ月先までの予測を行います。
from darts.models import ExponentialSmoothing
from darts.metrics import mape
def eval_model(model):
model.fit(train)
forecast = model.predict(n=48)
print("model {} obtains MAPE: {:.2f}%".format(model, mape(val, forecast)))
series.plot()
forecast.plot(label='forecast')
return TimeSeries.pd_dataframe(forecast)
eval_model(ExponentialSmoothing())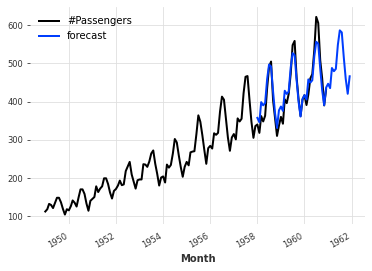
モデルを変えることで、同様に未来予測を実装することができます。
まとめ
最後までご覧いただきありがとうございました。
今回の記事では時系列分析が簡単に実装できるDartsについて紹介しました。

