このシリーズでは、自然言語処理において主流であるTransformerを中心に、環境構築から学習の方法までまとめます。
今回の記事ではHuggingface Transformersの入門として、livedoor ニュース記事のデータセットによる文章分類モデルの評価と推論の方法を紹介します。
Google colabを使用して、簡単に最新の自然言語処理モデルを実装することができますので、ぜひ最後までご覧ください。
【前回】
【🔰Huggingface Transformers入門⑦】文章分類モデルを作成する(2) 〜Trainerクラスとファインチューニング〜
このシリーズでは、自然言語処理において主流であるTransformerを中心に、環境構築から学習の方法までまとめます。 今回の記事ではHuggingface Transformersの入門として…
今回の内容
・Huggingface Transformersとは
・学習データの準備(前々回)
・Transformerのファインチューニング(前回)
・学習済みモデルの読み込み
・評価指標(混同行列、適合率(precision)、再現率(recall)、F1スコア、正解率(accuracy))
- 1. Huggingface Transformersとは
- 1.1. Transformerの概要
- 1.2. Huggingface Transformersの概要
- 2. 学習データの準備(前々回)
- 3. Transformerのファインチューニング(前回)
- 4. 学習済みモデルの読み込み
- 4.1. 準備
- 4.2. 前回学習したモデルの読み込み
- 4.3. テストデータの読み込み
- 5. 推論
- 5.1. 結果(ラベル)を表示する
- 5.2. スコアを表示する
- 5.3. 全てのデータに対して推論
- 6. 評価指標(混同行列、適合率(precision),再現率(recall),F1スコア,正解率(accuracy))
- 6.1. 混同行列
- 6.2. 評価指標を出力する
- 7. まとめ
Huggingface Transformersとは
Transformerの概要
「Transformer」は2017年にGoogleが「Attention is all you need」で発表した深層学習モデルです。
現在では、自然言語処理に利用する深層学習モデルの主流になっています。
これまでの自然言語処理分野で多く使われていた「RNN」(Recurrent Neural Network)や「CNN」(Convolutional Neural Network)を利用せず、Attentionのみを用いたEncoder-Decoder型のモデルとなっています。
「Transformer」が登場して以降、多くの自然言語処理モデルが再構築され、過去を上回る成果を上げています。
最近では自然言語処理だけでなく、ViTやDETRなどといった画像認識にも応用されています。
Huggingface Transformersの概要
「Hugging Face」とは米国のHugging Face社が提供している、自然言語処理に特化したディープラーニングのフレームワークです。
「Huggingface Transformers」は、先ほど紹介したTransformerを実装するためのフレームワークであり、「自然言語理解」と「自然言語生成」の最先端の汎用アーキテクチャ(BERT、GPT-2など)と、何千もの事前学習済みモデルを提供しています。
ソースコードは全てGitHub上で公開されており、誰でも無料で使うことができます。
学習データの準備(前々回)
文章分類問題のデータセットとして有名なlivedoor ニュース記事による分類モデルの作成を行いました。
(livedoor ニュースコーパス(https://www.rondhuit.com/download.html)より引用)
それぞれのニュース記事のタイトルから分類の学習を行います。
詳細は前回の記事で紹介していますので、合わせてご覧ください。
【🔰Huggingface Transformers入門⑥】文章分類モデルを作成する(1) 〜CSVからデータセットを作成する〜
このシリーズでは、自然言語処理において主流であるTransformerを中心に、環境構築から学習の方法までまとめます。 今回の記事ではHuggingface Transformersの入門として…

Transformerのファインチューニング(前回)
用意したデータセットをもとにファインチューニングを実装し、モデルを保存しました。
【🔰Huggingface Transformers入門⑦】文章分類モデルを作成する(2) 〜Trainerクラスとファインチューニング〜
このシリーズでは、自然言語処理において主流であるTransformerを中心に、環境構築から学習の方法までまとめます。 今回の記事ではHuggingface Transformersの入門として…
学習済みモデルの読み込み
準備
ここからはGoogle colabを使用して実装していきます。
今回紹介するコードは以下のボタンからコピーして使用していただくことも可能です。
![]()
Googleドライブをマウントして、作業フォルダを作成します。
from google.colab import drive
drive.mount('/content/drive')
!mkdir -p '/content/drive/My Drive/huggingface_transformers_demo/'
%cd '/content/drive/My Drive/huggingface_transformers_demo/'必要なライブラリをインストールします。
!pip install transformers fugashi ipadic sentencepiece datasets前回学習したモデルの読み込み
まずは前回保存したモデルを読み込みます。
import torch
import pandas as pd
import numpy as np
from transformers import AutoModelForSequenceClassification, AutoTokenizer
# トークナイザの取得
tokenizer = AutoTokenizer.from_pretrained('./text/news_model')
# モデルの取得
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = (AutoModelForSequenceClassification
.from_pretrained('./text/news_model')
.to(device))テストデータの読み込み
次に前々回の記事で作成したテスト用のデータを読み込み、最初の10行を表示してみます。
test_df = pd.read_csv("./text/news_test.csv",encoding='UTF-8')
test_df[:10]| index | label | sentence |
|---|---|---|
| 0 | 6 | モデルも常連!カロリーオフのおむすび屋 【プレゼント有り】 |
| 1 | 7 | Interop Tokyo 2012:デジタルサイネージジャパンにてセラクがAndroidを搭載した鏡付き洗面台「スマート洗面台」を出展【レポート】 |
| 2 | 6 | 波乱の恋のドキドキ映画で恋のボルテージを上げる! |
| 3 | 6 | インタビュー:国生さゆり「私は、まだまだ女の初心者」 |
| 4 | 6 | 食欲も美容も満たす! 満足女子鍋 |
| 5 | 6 | コラーゲン、摂るだけで安心していませんか? |
| 6 | 5 | インタビュー:長野じゅりあ「世の男性にもっと強く、男らしくなって欲しい」 |
| 7 | 5 | 小さくなったバズが走り回る! 『トイ・ストーリー3』続編の特別映像が公開 |
| 8 | 5 | 雨上がり決死隊の宮迫が、息子と対決 |
| 9 | 1 | MacBook ProがRetina対応 次はAirも対応?【デジ通】 |
test_df = pd.read_csv("./text/news_test.csv",encoding='UTF-8')
test_df[:10]推論
推論する文章を用意します。
sample_text = test_df['sentence'][1]
sample_text
# Interop Tokyo 2012:デジタルサイネージジャパンにてセラクがAndroidを搭載した鏡付き洗面台「スマート洗面台」を出展【レポート】この文章に対して推論を実施します。
inputs = tokenizer(sample_text, return_tensors="pt")
labels =['dokujo', 'it', 'sports-','kaden','homme','movie','peachy','smax','topic-news']
model.eval()
with torch.no_grad():
outputs = model(inputs["input_ids"].to(device), inputs["attention_mask"].to(device))
prediction = torch.nn.functional.softmax(outputs.logits,dim=1)結果(ラベル)を表示する
結果を表示します。
#ラベル番号を表示
print(int(torch.argmax(prediction)))
#ラベル名を表示
print(labels[int(torch.argmax(prediction))])実行すると以下のような結果が出力されます。
#ラベル番号
7
#ラベル名
smax正しく推論できていることがわかりました。
スコアを表示する
スコアを表示します。
print(prediction.cpu().detach().numpy())
#[[0.00333388 0.01006817 0.00436237 0.06067429 0.00629614 0.00435802 0.00476074 0.9016149 0.00453156]]全てのカテゴリに対してのスコアが表示されました。
これの最大値を取ることで、推論結果のスコアを得ることができます。
print(np.max(prediction.cpu().detach().numpy()))
# 0.9016149全てのデータに対して推論
全てのデータに対して推論を行います。
df = pd.DataFrame(columns=['label','pred', 'sentence'])
for sentence in test_df['sentence']:
inputs = tokenizer(sentence, return_tensors="pt")
labels =['dokujo', 'it', 'sports-','kaden','homme','movie','peachy','smax','topic-news']
model.eval()
with torch.no_grad():
outputs = model(inputs["input_ids"].to(device), inputs["attention_mask"].to(device))
prediction = torch.nn.functional.softmax(outputs.logits,dim=1)
df = df.append({'label':labels[int(torch.argmax(prediction))] ,'pred':np.max(prediction.cpu().detach().numpy()),'sentence':sentence}, ignore_index=True)| index | label | pred | sentence |
|---|---|---|---|
| 0 | kaden | 0.6927857398986816 | モデルも常連!カロリーオフのおむすび屋 【プレゼント有り】 |
| 1 | smax | 0.9016149044036865 | Interop Tokyo 2012:デジタルサイネージジャパンにてセラクがAndroidを搭載した鏡付き洗面台「スマート洗面台」を出展【レポート】 |
| 2 | peachy | 0.5601576566696167 | 波乱の恋のドキドキ映画で恋のボルテージを上げる! |
| 3 | peachy | 0.4652966856956482 | インタビュー:国生さゆり「私は、まだまだ女の初心者」 |
| 4 | dokujo | 0.5311513543128967 | 食欲も美容も満たす! 満足女子鍋 |
| 5 | dokujo | 0.515322744846344 | コラーゲン、摂るだけで安心していませんか? |
| 6 | peachy | 0.8403741717338562 | インタビュー:長野じゅりあ「世の男性にもっと強く、男らしくなって欲しい」 |
| 7 | movie | 0.9187605381011963 | 小さくなったバズが走り回る! 『トイ・ストーリー3』続編の特別映像が公開 |
| 8 | movie | 0.8839553594589233 | 雨上がり決死隊の宮迫が、息子と対決 |
| 9 | it | 0.9639502167701721 | MacBook ProがRetina対応 次はAirも対応?【デジ通】 |
結果をcsvファイルに出力することができます。
df.to_csv("./text/news_test_result.csv",encoding='UTF-8')評価指標(混同行列、適合率(precision),再現率(recall),F1スコア,正解率(accuracy))
混同行列
混同行列を出力します。
y_true = []
y_pred = []
for item in zip(test_df['label'], test_df['sentence']):
inputs = tokenizer(item[1], return_tensors="pt")
labels =['dokujo', 'it', 'sports-','kaden','homme','movie','peachy','smax','topic-news']
model.eval()
with torch.no_grad():
outputs = model(inputs["input_ids"].to(device), inputs["attention_mask"].to(device))
prediction = torch.nn.functional.softmax(outputs.logits,dim=1)
y_true.append(item[0])
y_pred.append(int(torch.argmax(prediction)))labels =['dokujo', 'it', 'sports-','kaden','homme','movie','peachy','smax','topic-news']
def plot_confusion_matrix(y_preds, y_true, labels):
cm = confusion_matrix(y_true, y_pred, normalize="true")
fig, ax = plt.subplots(figsize=(6, 6))
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot(cmap="Blues", values_format=".2f", ax=ax, colorbar=False)
plt.title("Normalized confusion matrix")
plt.show()
plot_confusion_matrix(y_pred, y_true,labels)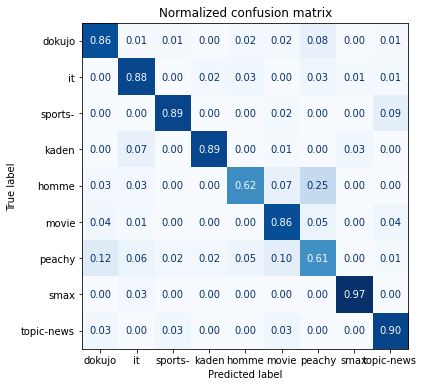
評価指標を出力する
適合率(precision)、再現率(recall)、F1スコア、正解率(accuracy)、マクロ平均、マイクロ平均を出力します。
classification_report()を使用すると、これらの指標をまとめて簡単に出力することができます。
from sklearn.metrics import classification_report
labels =['dokujo', 'it', 'sports-','kaden','homme','movie','peachy','smax','topic-news']
report = classification_report(y_true, y_pred,target_names=labels,output_dict=True)
report_df = pd.DataFrame(report).T
report_df実行すると、以下のように表形式で出力されます。
| index | precision | recall | f1-score | support |
|---|---|---|---|---|
| dokujo | 0.8425925925925926 | 0.8584905660377359 | 0.850467289719626 | 106.0 |
| it | 0.8260869565217391 | 0.8837209302325582 | 0.853932584269663 | 86.0 |
| sports- | 0.9318181818181818 | 0.8913043478260869 | 0.9111111111111111 | 92.0 |
| kaden | 0.9506172839506173 | 0.8850574712643678 | 0.9166666666666666 | 87.0 |
| homme | 0.7352941176470589 | 0.625 | 0.6756756756756757 | 40.0 |
| movie | 0.7840909090909091 | 0.8625 | 0.8214285714285715 | 80.0 |
| peachy | 0.6710526315789473 | 0.6144578313253012 | 0.6415094339622641 | 83.0 |
| smax | 0.9493670886075949 | 0.974025974025974 | 0.9615384615384615 | 77.0 |
| topic-news | 0.8478260869565217 | 0.896551724137931 | 0.8715083798882682 | 87.0 |
| accuracy | 0.8455284552845529 | 0.8455284552845529 | 0.8455284552845529 | 0.8455284552845529 |
| macro avg | 0.8376384276404626 | 0.8323454272055505 | 0.8337597971400341 | 738.0 |
| weighted avg | 0.844834431909039 | 0.8455284552845529 | 0.8441819018002916 | 738.0 |
まとめ
最後までご覧いただきありがとうございました。
今回の記事ではHuggingface Transformersの入門として、livedoor ニュース記事のデータセットによる文章分類モデル推論と評価指標の出力方法を紹介しました。

