このシリーズでは、自然言語処理において主流であるTransformerを中心に、環境構築から学習の方法までまとめます。
今回の記事ではHuggingface Transformersの入門の第1回目として、モデルの概要と使い方について紹介します。
Google colabを使用して、簡単に最新の自然言語処理モデルを実装することができますので、ぜひ最後までご覧ください。
Google Colabの使い方はこちら
【前回】
【🔰Huggingface Transformers入門⓪】自然言語処理とTransformers
このシリーズでは、自然言語処理において主流であるTransformerを中心に、環境構築から学習の方法までまとめます。 今回の記事ではHuggingface Transformersの入門の初回…
今回の内容
・Transformerとは
・Transformer系の派生モデル
・Huggingface Transformers モデルの使い方
・モデルの保存と読み込み
- 1. Transformerとは
- 1.1. Transformerの概要
- 1.2. Transformerのアーキテクチャ
- 2. Transformerの派生モデル
- 2.1. エンコーダモデル
- 2.2. デコーダモデル
- 2.3. エンコーダ・デコーダモデル
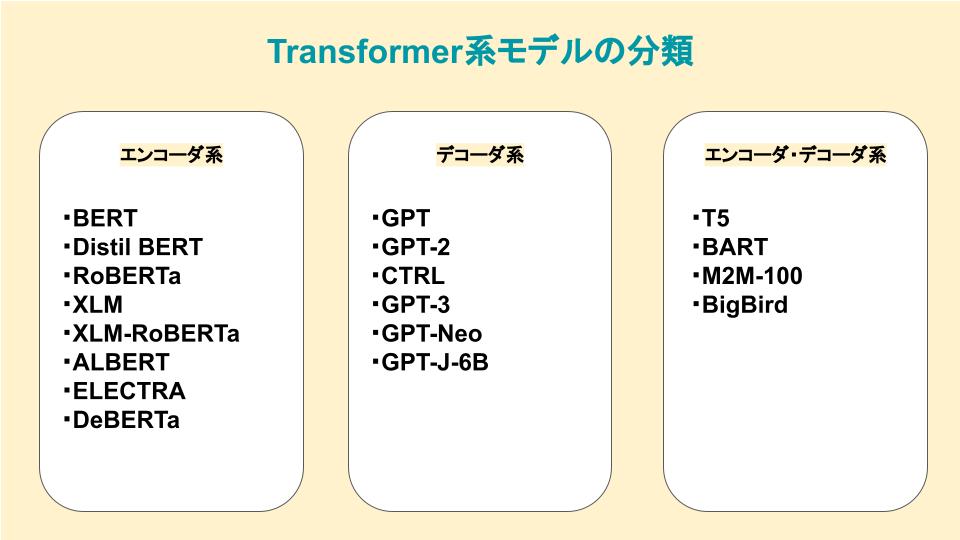
- 3. エンコーダ系のモデル
- 3.1. BERT
- 3.2. DistilBERT
- 3.3. RoBERTa
- 3.4. XLM
- 3.5. XLM-RoBERTa
- 3.6. ALBERT
- 3.7. ELECTRA
- 3.8. DeBERTa
- 4. デコーダ系のモデル
- 4.1. GPT
- 4.2. GPT-2
- 4.3. CTRL
- 4.4. GPT-3
- 4.5. GPT-Neo,GPT-J-6B
- 5. エンコーダ・デコーダ系のモデル
- 5.1. T5
- 5.2. BART
- 5.3. M2M-100
- 5.4. BigBird
- 6. Huggingface Transformers モデルの使い方
- 6.1. モデルの使用方法
- 6.2. モデルの構造を表示する
- 6.3. モデルの読み込み
- 6.4. Huggingface Transformersのモデル
- 7. モデルの保存と読み込み
- 7.1. モデルの保存
- 7.2. モデルの読み込み
- 8. モデルのキャッシュパス
- 9. まとめ
Transformerとは
Transformerの概要
「Transformer」は2017年にGoogleが「Attention is all you need」で発表した深層学習モデルです。
現在では、自然言語処理に利用する深層学習モデルの主流になっています。
これまでの自然言語処理分野で多く使われていた「RNN」(Recurrent Neural Network)や「CNN」(Convolutional Neural Network)を利用せず、Attentionのみを用いたEncoder-Decoder型のモデルとなっています。
「Transformer」が登場して以降、多くの自然言語処理モデルが再構築され、過去を上回る成果を上げています。
最近では自然言語処理だけでなく、ViTやDETRなどといった画像認識にも応用されています。
これまでに登場した主なモデルを以下に示します。
| 登場年 | 主なモデル |
|---|---|
| 2017年 | ・「Attention is all you need」というタイトルの論文で、初めてTransformerモデルの提案がなされた。この論文では、翻訳タスクを行うものであった。 |
| 2018年 | ・学習済みTransformerモデルとしてGPTが初めて登場。ファインチューニングによる様々なNLPタスクへの適用がなされた。 ・BERTが発表される。 |
| 2019年 | ・GPTの改良版として、よりサイズも大きいGPT2が誕生した。 ・BERTの蒸留モデルであるDistilBERTが誕生。BERTの97%の精度を維持しつつも、推論速度が60%速く、モデルのサイズも40%小さい。 ・BARTとT5という大規模データセットで学習済みのsequence-to-sequenceモデルが誕生。 |
| 2020年 | ・GPT-2よりも更に大きいGPT-3が誕生。Few-shot learningによりfine-tuningのコストを出来るだけ抑えて、様々なタスクに転用できるモデル。 ・Transformerを画像認識に応用したVision Transformerが誕生。画像分類タスクにおいて、CNN(畳み込み)を用いずに最高性能の記録。 |
| 2021年 | ・GPT3と同等の性能でありながら、より小型なモデルであるGPT-NEOやGPT-J-6Bが誕生。 |
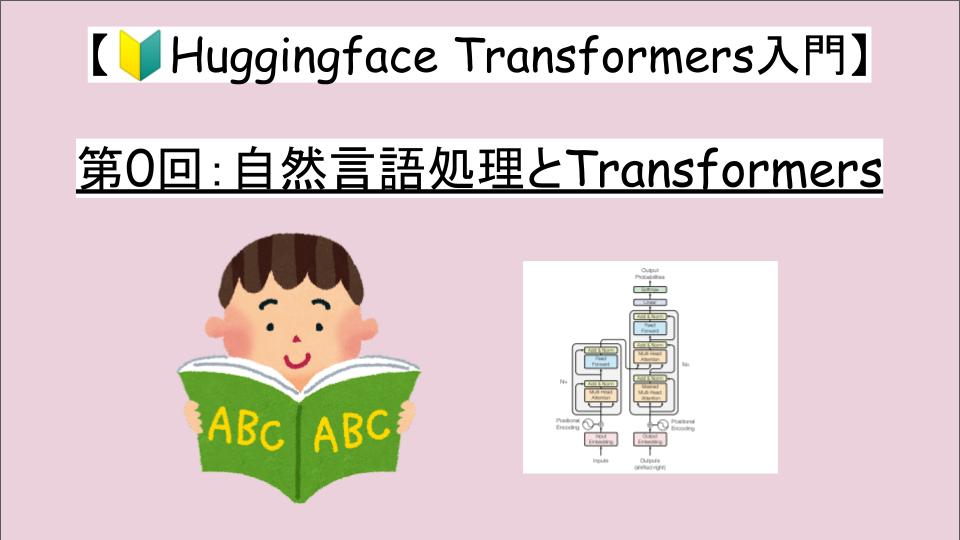
Transformerのアーキテクチャ
まずは、Transformerの全体像を示します。
上図において、左半分がエンコーダ、右半分がデコーダ になっています。
それぞれ、エンコーダは入力データを多次元の数値ベクトルでの表現に変換する特徴表現の役割を持ち、デコーダはエンコーダの出力(入力データの特徴表現)と別の入力データを受け取り、出力データを生成します。
Transformerの派生モデルとして、エンコーダとデコーダを切り離して個別に使用した、エンコーダモデルやデコーダモデルがあります。
次章では、代表的なモデルの概要を紹介します。
Transformerの派生モデル
Transformerの派生モデルは、以下のように3つのカテゴリに分類することができます。
エンコーダモデル
Transformerのエンコーダ部分のみを使ったモデルです。
入力データのトークンの一部を[Mask]トークンでマスクし、元のトークンを当てるという穴埋め問題を解くタスクを設定し、学習を進めます。
Attention層は入力系列データに含まれる全ての単語に対して注目することができ、各単語の前にある単語だけでなく、後ろに続く単語にも注目できるので「双方向のAttention」という位置付けになっています。
Encoderモデルは入力データの特徴表現を出力するので、それを分類器にわたすモデルのタスクに適していると言えます。
例として、文書分類、固有表現認識、対象の文書内から回答部分を抽出するタイプの質問応答などがあります。
デコーダモデル
Transformerのデコーダ部分のみを使ったモデルです。
入力系列データに含まれる単語に対して、次に続く単語を予測するタスクを設定し、学習を進めます。
Attention層は入力データに含まれる単語のうち、それぞれの単語の前にある単語にのみ注目できます。
テキスト生成のようなタスクに適したモデルとなっています。
エンコーダ・デコーダモデル
Transformerのアーキテクチャを全体的に活用したモデルです。
エンコーダ部分は入力系列データの単語全てに注目し、デコーダ部分はそれぞれの単語よりも前に出てくる単語のみに注目します。
エンコーダモデルでの穴埋め問題を解くタスクと、デコーダモデルで次に続く単語を予測するタスクの両方を設定し、学習を進めます。
テキストを入力して、その内容に応じて別のテキストを出力するといったタスクへの応用に適しています。
例えば文書要約、機械翻訳、特定の文書を参照することなく自然文で質問応答をする対話システムなどがあります。
エンコーダ系のモデル
ここからは、それぞれのモデルについて概要を紹介します。
BERT
「Toronto Book Corpus」 と 「Wikipedia」 で構成される大規模なコーパスで、マスクされた言語モデリングの目的と次の文の予測の組み合わせを使用して事前トレーニングされた、双方向トランスフォーマーです。
すべてのレイヤーで左と右の両方のコンテキストを組み合わせて調整することにより、ラベルのないテキストから深い双方向表現を事前トレーニングするように設計されています。
事前トレーニング済みの BERT モデルは、追加の出力レイヤーを 1 つ追加するだけで、質問応答や言語推論などの幅広いタスク向けの実装が可能ですが、言語モデリング (MLM) と次の文の予測 (NSP) の目的でトレーニングされているため、テキスト生成には不向きとしています。
| 論文 | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding |
| 著者 | Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova |
| 発表 | 2018年 |
| URL | https://huggingface.co/docs/transformers/model_doc/bert |
DistilBERT
事前学習で「知識蒸留」を使うことで、BERTを蒸留したモデルです。
元の性能の97%を達成しつつ、40%少ないメモリ使用量と60%の高速化を果たしています。
RoBERTa
事前学習のスキームを変更することにより性能を向上させることがわかってきました。
RoBERTaはより多くの学習データと大きなバッチで長時間学習させることで、BERTと比較して大幅に性能が向上しました。
XLM
クロスリンガル言語モデル(XLM)の研究において、GPTのような自己回帰言語モデルやBERTのようなマスク言語モデルなど、多言語モデル構築のための事前学習タスクがいくつか検討されました。
マスク言語モデルを複数言語の入力に拡張した翻訳言語モデルを導入することで、多言語の自然言語理解ベンチマークで最高水準の結果を達成しました。
XLM-RoBERTa
Common Crawlコーパスを用いて、2.5TBのテキストからなるデータセットを用いて、学習をさせたモデルです。
このデータセットには翻訳が含まれていないため、XLMで用いられた翻訳言語モデルは削除されています。
このアプローチは特に低リソース言語において、性能を発揮します。
ALBERT
A Lite BERTという名前の通り、BERTを軽量化したモデルです。
主な改良点は以下の通りです。
①トークンの埋め込み次元を隠れ層の次元から切り離し、埋め込み次元を小さくすることで、特に語彙が大きくなった時にパラメータを節約できるようになリました。
②全ての層で同じパラメータを共有すること(パラメータシェアリング)により、パラメータ数を減少させています。
③次文予測を文の順序予測に置き換えて学習させています。
| 論文 | ALBERT: A Lite BERT for Self-supervised Learning of Language Representations |
| 著者 | Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut |
| 発表 | 2019年 |
| URL | https://huggingface.co/docs/transformers/model_doc/albert |
ELECTRA
Google が提案した BERT の事前学習手法の改良モデルです。
最初のモデルは標準的なマスク言語モデルのように動作し、マスクされたトークンを予測します。
識別器では最初のモデル出力にあるトークンのうち、どれが元からマスクされていたのかを予測します。
そのため、識別器は全てのトークンに対して2値分類を行う必要があるため、学習効率が30倍向上します。
この手法により、標準的なマスク言語モデルのように各学習ステップにおいてマスクされたトークンのみが更新され、他のトークンが更新されないという問題を克服していています。
DeBERTa
Microsoftが2021年に提案したモデルです。
SuperGLUEベンチマークにおいて人間のベースラインを初めて破ったモデルとなっています。
以下のようにアーキテクチャ上の変更を導入しています。
①各トークンは内容と相対的な位置の2つのベクトルとして表現されますが、トークンの内容と相対的な位置を切り離すことで、セルフアテンション層は近くのトークンベアの依存関係をより良くモデル化できるようになりました。
②トークンのデコードヘッドのソフトマックス層の直前に絶対位置の埋め込みを追加しています。
デコーダ系のモデル
GPT
OpenAIが2018年に提案したGenerative Pre-trained Transformerという大規模な言語モデルで、タスクに特化した学習をしなくても自然な文章を生成できることが特徴です。
Transformerデコーダアーキテクチャと転移学習を組み合わせています。
GPTでは前の単語を元に次の単語を予測することでモデルを事前学習をします。
| 論文 | Improving Language Understanding by Generative Pre-Training |
| 著者 | Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever |
| 発表 | 2018年 |
| URL | https://huggingface.co/docs/transformers/model_doc/openai-gpt |
GPT-2
OpenAIが2019年に提案したGPTの後継モデルです。
あまりに自然な文章を生成できるとしてフェイクニュースなどの危険性から、当初は小規模モデのみが公開されていました。
シンプルでスケール性の高い事前学習手法などから、オリジナルのモデルと学習データセットをスケールアップすることでGPT2が誕生しました。
CTRL
GPTのようなモデルでは、生成される系列のスタイルを制御できないという欠点があります。
そこで、系列の先頭にコントロールトークンを追加することでこの問題を解決したものがCTRLです。
コントロールトークンにより、生成されるテキストのスタイルを制御でき、多様な生成が可能となります。
GPT-3
OpenAIが2020年に提案したGPT2の後継モデルです。
計算量、データサイズセット、モデルサイズ、言語モデルの性能の関係を支配する単純なべき乗の存在が明らかになったことから、GPT2の100倍にスケールアップされ、1750億のパラメータを持つGPT3が誕生しました。
非常にリアルなテキストを生成できるだけでなく、few-shot-lerningの能力も示しました。
GPT-Neo,GPT-J-6B
GPT3スケールのモデルを再現して公開することを目指して作成されたモデルです。
パラメータ数はGPT3と比較すると、数十億程度と小さくなっています。
エンコーダ・デコーダ系のモデル
T5
Googleが2020年に提案したモデルで、Text-to-Text Transfer TransformerからT5という名前になっています。
全ての自然言語理解と自然言語生成のタスクをテキストの変換タスクに変換して統一的に解くことができます。
大規模にクロールされたC4データセットを用いてマスク言語モデルでモデルを事前学習し、SuperGLUEの全タスクを系列変換タスクに変換しています。
| 論文 | Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer |
| 著者 | Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu |
| 発表 | 2020年 |
| URL | https://huggingface.co/docs/transformers/model_doc/t5 |
BART
BERTとGPTの事前学習をエンコーダ・デコーダのアーキテクチャの中で組み合わせたものです。
入力系列は単純なマスキングから文の並べ替え、トークンの削除、文書の回転などのうち1つの変換が行われています。
これらの変換された入力はエンコーダを通過し、デコーダは元のテキストを再構築するため、さまざまなタスクで性能を発揮します。
M2M-100
100言語間の翻訳を可能にする初めての翻訳モデルです。
希少な言語やあまり取り上げられない言語の翻訳を高品質に行うことができます。
BigBird
Transformerモデルの主な制限の1つとして、アテンション機構のメモリ要件が2乗のオーダーであるために起きる最大コンテキストサイズの問題があり、これに対応するため、線形にスケールするスパース形式のアテンションを使用しています。
これにより、BERTモデルでは512トークンにしか対応できないのに対し、BigBirdでは4096トークンまでの入力に対応することができます。
テキストの要約タスクのように、長い依存関係を保持する際に有効です。
Huggingface Transformers モデルの使い方
モデルの使用方法
ここまで多くのモデルを紹介してきましたが、ここからHuggingface Transformersにおけるモデルの使用方法を紹介します。
Google colabを使用して、モデルを実際に扱ってみましょう。
まずは、必要なライブラリをインストールします。
!pip install transformersAutoModelクラスにより、使いたいモデルのcheckpointを指定することで、簡単にモデルを使うことができます。
以下の例では、「bert-base-japanese-whole-word-masking」というモデルを指定しています。
from transformers import AutoModel
checkpoint = 'cl-tohoku/bert-base-japanese-whole-word-masking'
model = AutoModel.from_pretrained(checkpoint)「bert-base-japanese-whole-word-masking」は東北大学が作成した日本語用のBERTベースのモデルです。
日本語の自然言語処理を扱う際には、よく使用するモデルとなります。
詳細は、以下のリンクからご確認ください。
モデルの構造を表示する
使いたいモデルが決まっている場合は、そのモデルのクラスを直接使ってインスタンスを作ることも可能です。
BERTを使う場合は、以下のようすることで読み込むことができます。
ここでは例として、BERTの構造を表示してみます。
from transformers import BertConfig, BertModel
config = BertConfig()
model = BertModel(config)
print(config)
BertConfig {
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.24.0",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}BERTの構造を表示することができました。
なお、それぞれの属性の意味はこちらから確認することができます。
モデルの読み込み
次にこのconfigをBertModelに与えて、モデルのインスタンスを作成します。
これにより、事前学習済みモデルを使用して、タスクの実装が行えるようになります。
checkpoint = 'cl-tohoku/bert-base-japanese-whole-word-masking'
model = BertModel.from_pretrained(checkpoint)初回モデル読み込み時には重みパラメータのダウンロードが行われますが、2回目以降に使用する場合にはローカルにキャッシュされたものから読み込まれるようになっています。
Huggingface Transformersのモデル
今回は日本語BERTのモデルを例に紹介しましたが、Huggingface Transformersでは多くの事前学習済みモデルが公開されています。
(本記事執筆時点では、83,000ものモデルが公開されています。)
タスクや求める性能、使用する言語に応じて、様々なモデルから選択できるようになっています。
詳細は、以下のリンクからご確認ください。
モデルの保存と読み込み
モデルの保存
モデルの保存方法について紹介します。
自分で学習を行った際にはモデルを保存することができます。
以下の例では、モデルを「tmp」というフォルダに保存します。
なお、保存先のディレクトリが存在しない場合には、自動でフォルダを作成してくれます。
model.save_pretrained("./tmp"))保存をすると「config.json」と「pytorch_model.bin」という2種類のファイルが保存されます。
モデルの読み込み
保存と同様に読み込みも簡単に行うことができます。
以下の例では、先ほど保存した「tmp」フォルダにあるモデルを読み込みます。
saved_model = model.from_pretrained("./tmp")モデルのキャッシュパス
# モデルのキャッシュパスの確認
from transformers import file_utils
print(file_utils.default_cache_path)
# モデルのキャッシュパスの変更
import os
os.environ['TRANSFORMERS_CACHE'] = '/content/drive/My Drive/huggingface_transformers_demo'
os.environ['HF_DATASETS_CACHE'] = '/content/drive/My Drive/huggingface_transformers_demo/Datasets'まとめ
最後までご覧いただきありがとうございました。
今回の記事ではHuggingface Transformersの入門として、モデルの概要と使い方を紹介しました。
次回の記事では、トークナイザーについて紹介します。
このシリーズでは、自然言語処理全般に関するより詳細な実装や学習の方法を紹介しておりますので、是非ご覧ください。
【次回】
【🔰Huggingface Transformers入門②】トークナイザーの概要と使い方
このシリーズでは、自然言語処理において主流であるTransformerを中心に、環境構築から学習の方法までまとめます。 今回の記事ではHuggingface Transformersの入門として…