エージェントとは
エージェントとは、特定のタスクを実行するために設計されたソフトウェアプログラムやシステムのことです。特に、LLM(大規模言語モデル)を活用するエージェントは、人間の指示に基づいてテキストを生成したり、情報を提供したりすることができます。
例えば、エージェントはユーザーの質問に答えるチャットボットとして機能します。ユーザーが「今日は天気はどう?」と尋ねると、エージェントはインターネットから最新の天気情報を取得し、適切な回答を返します。このように、エージェントは人間のように自然な会話を行い、様々なタスクを自動化することができます。
このチュートリアルでは、検索エンジンと対話できるエージェントを構築する方法を学びます。このエージェントに質問をすると、検索ツールを呼び出して情報を調べ、会話を行うことができるようになります。
ツールの導入
導入
ここからはGoogle colabで実装していきます。
LangChainをインストールするには、以下のコマンドを実行します。
# 必要なライブラリをインストール
!pip install langchain
!pip install langchain-openai
!pip install langchain-community
!pip install langchain-chroma次に環境変数の準備をします。
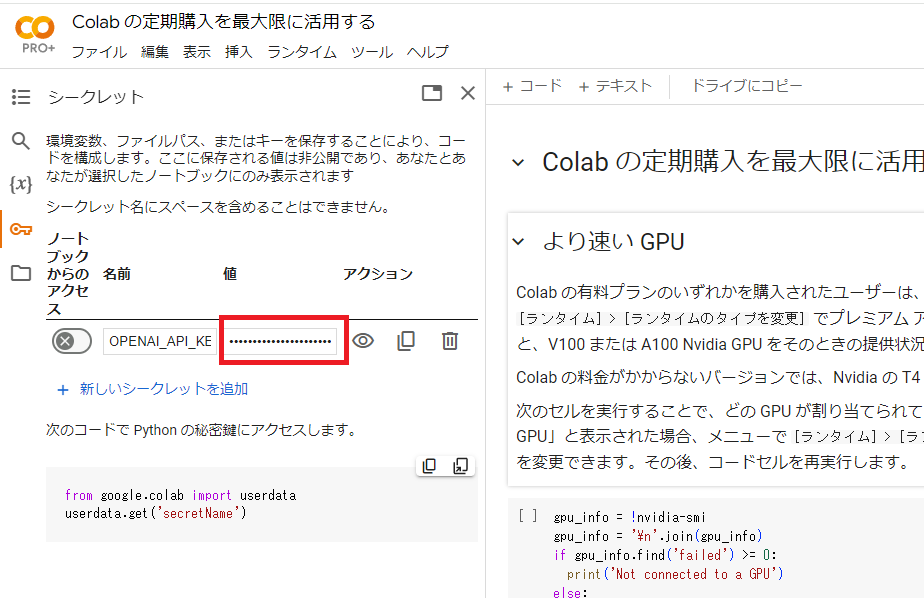
Google colabの左端にある鍵アイコンで「OPENAI_API_KEY」を設定します。
下図において、名前の欄に「OPENAI_API_KEY」、値の欄にご自身のAPIキーを入力してください。
なお、まだOpenAIのAPIキーを取得していない方は、こちらから取得することができます。
設定が終わったら、以下のコードを実行します。
import os
from google.colab import userdata
# 環境変数の準備
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")検索エンジン「Tavily」
Tavily AIは、AIエージェントや大規模言語モデル(LLM)向けに最適化された検索エンジンです。この検索エンジンは、迅速で効率的、かつ一貫した検索結果を提供することを目指しています。Tavilyの主な特徴は、複数の信頼できる情報源からデータを収集し、精緻なアルゴリズムを用いて、関連性の高い情報を抽出、フィルタリング、ランキングする点にあります。
Tavily Search APIは、通常の検索エンジンと異なり、特定のタスクや目標に応じて、最も適したコンテンツを集約して提供します。これにより、AI開発者や自律型AIエージェントは、手間をかけずに高品質なデータを取得しやすくなります。
また、Tavilyはオープンソースの自動研究エージェント「GPT Researcher」を提供しており、このエージェントはウェブ上の20以上の情報源からデータを収集し、フィルタリングして、信頼性の高い研究レポートを生成します。
Tavilyは無料で利用できるプランもあり、APIコールの回数に応じた有料プランも提供されています。特に研究者や開発者にとっては、非常に使いやすいツールとなっています。
Tavilyを使用した検索を実行する例を紹介します。
from langchain_community.tools.tavily_search import TavilySearchResults
# Tavilyツールの準備
search = TavilySearchResults(max_results=2)
# Tavilyツールの実行
search.invoke("東京の明日の天気は?")実行結果:
[{'url': 'https://tenki.jp/forecast/3/16/',
'content': '東京都の天気予報です。市区町村別の今日の天気、気温、降水確率が地図上に表示されているので、ひと目でわかります。タブ切り替えで10日間 ...'},
{'url': 'https://weathernews.jp/onebox/tenki/tokyo/',
'content': '東京の最新天気情報。よく当たる1時間毎のピンポイント天気、現在の気温や湿度、雨雲レーダー、週間天気が確認できます。都市、施設名、観光名所による検索もこちらで!'}]この例では、TavilySearchResultsクラスをlangchain_community.tools.tavily_searchモジュールからインポートしています。このクラスのインスタンスsearchを作成する際、max_resultsパラメータで最大検索結果数を指定しています。ここでは2に設定されています。
次に、search.invoke()メソッドを呼び出し、検索クエリ「東京の明日の天気は?」を渡しています。このメソッドは検索を実行し、結果をリストで返します。各結果は辞書型で表現され、'url'キーにURLが、'content'キーにそのページの概要が格納されています。
LLMの準備
次に、ツールを呼び出すための言語モデルを用意します。langchainは、OpenAIやAnthropicなどさまざまなモデルに対応しています。ここではgpt-4oを使用します。
from langchain_openai import ChatOpenAI
# LLMの準備
llm = ChatOpenAI(model="gpt-4o")このモデルに、先ほど定義したツールを利用できるように設定します。
# ツールのリストを作成し、検索ツールを追加
tools = [search]
# ツールを言語モデルにバインド
model_with_tools = llm.bind_tools(tools)toolsリストを作成し、先ほど作成した検索ツールsearchを追加します。次に、llm.bind_tools()メソッドを呼び出し、toolsリストを渡すことで、モデルにツールを紐付けます。この結果、model_with_tools変数にツール付きのモデルが格納されます。
from langchain_core.messages import HumanMessage
# ヒューマンメッセージを作成し、モデルにクエリを実行させる
response = model_with_tools.invoke([HumanMessage(content="東京の明日の天気を知りたい")])
# レスポンスのコンテンツを表示
print(f"ContentString: {response.content}")
# 使用されたツールコールを表示
print(f"ToolCalls: {response.tool_calls}")実行結果:
ContentString:
ToolCalls: [{'name': 'tavily_search_results_json', 'args': {'query': '東京 明日 天気'}, 'id': 'call_MonqfttgEE5iUi5CMiZ8ZQvz'}]今度はツールの呼び出しが発生しています。ただし、これはツールの利用を提案しているだけで、実際に呼び出したわけではありません。
ツールを実際に呼び出すには、langchainのエージェント機能を使う必要があります。
エージェントの導入
エージェントの作成
まずは、使用するツールとLLMを定義します。今回は、LangGraphを使ってエージェントを構築していきます。
LangGraphには、高レベルなインターフェースと、柔軟にカスタマイズ可能な低レベルのAPIの両方が用意されているので、必要に応じてエージェントのロジックを修正することもできますよ。
ツールとLLMが用意できたら、次のようにしてエージェントを初期化します。
from langgraph.prebuilt import create_react_agent
# エージェントの実行器を作成
agent_executor = create_react_agent(llm, tools)model_with_toolsではなくmodelを渡していることに注意してください。create_react_agentが内部で.bind_toolsを呼び出してくれるからです。
エージェントの実行
作成したエージェントにいくつかの質問をしてみましょう!現時点ではステートレスなので、過去のやり取りは覚えていませんが、対話の最終状態が返ってきます。
まずは、ツールを呼び出す必要のない単純な会話を実行します。
# HumanMessageを作成してエージェントに送信し、応答を取得
response = agent_executor.invoke({"messages": [HumanMessage(content="こんにちは。今日はいい天気ですね。")]})
# 応答メッセージの内容を表示
print(f'ContentString: {response["messages"][-1].content}')
# 2番目のメッセージの追加キーワードを表示
print(f'ContentString: {response["messages"][1].additional_kwargs}')実行結果:
ContentString: こんにちは!お天気がいいと気分も上がりますよね。今日は何か特別な予定がありますか?
ContentString: {}次に、検索ツールを使って情報を取得する必要がある質問をしてみます。
# HumanMessageを作成してエージェントに送信し、応答を取得
response = agent_executor.invoke( {"messages": [HumanMessage(content="こんにちは。東京の明日の天気を知りたい")]})
# 応答メッセージの内容を表示
print(f'ContentString: {response["messages"][-1].content}')
# 2番目のメッセージの追加キーワードを表示
print(f'ContentString: {response["messages"][1].additional_kwargs}')ここでは、東京の明日の天気を尋ねるHumanMessageを送信しています。エージェントは内部で適切なツールを選択して実行し、その結果を応答メッセージに組み込んで返してくれます。
実行結果:
ContentString: 東京の明日の天気予報は次の通りです:
- 予報:晴れ時々曇り
- 最高気温:約32°C
- 最低気温:約22°C
- 降水確率:低い
- 風速:約15.1 km/h
詳細な情報は、以下のリンクからも確認できます:
- [WeatherAPI](https://www.weatherapi.com/)
- [World-Weather](https://world-weather.info/forecast/japan/tokyo/june-2024/)
必要な場合は、これらのリンクを参照してください。
ContentString: {'tool_calls': [{'id': 'call_WJf7P0FCRQ9qPxWOmv4mBSQj', 'function': {'arguments': '{"query":"Tokyo weather forecast for tomorrow"}', 'name': 'tavily_search_results_json'}, 'type': 'function'}]}ここで注目すべきは、2番目のメッセージの追加情報にあるtool_callsです。これは、エージェントが天気情報を取得するために実行したツールの呼び出し履歴を表しています。tavily_search_results_jsonというツールに、"Tokyo weather forecast for tomorrow"というクエリを渡して実行したことがわかります。
過去の会話履歴を参照するエージェント
デフォルトのLangchainのエージェントはステートレスで、以前のやり取りを覚えていません。
メモリを持たせるには、チェックポインターを渡す必要があります。
その際、エージェントの呼び出し時にthread_idも指定し、どの会話を再開するかを識別できるようにします。
まず、SqliteSaverを使ってメモリ用のチェックポインターを作成します。
from langgraph.checkpoint.sqlite import SqliteSaver
# メモリーの準備
memory = SqliteSaver.from_conn_string(":memory:")次に、エージェントの作成時にこのメモリを渡します。
# LLMエージェントを作成し、メモリーをチェックポイントとして設定
agent_executor = create_react_agent(llm, tools, checkpointer=memory)会話の実行(1回目)
エージェントとの会話を開始するには、thread_idを指定したconfigを用意し、メッセージをストリームで渡します。
# エージェントのコンフィグレーション設定
config = {"configurable": {"thread_id": "abc123"}}
# エージェントにメッセージを送信し、レスポンスをストリーム出力
for chunk in agent_executor.stream(
{"messages": [HumanMessage(content="こんにちは。私は東京に遊びに来ています。")]}, config
):
print(chunk) # レスポンスの各チャンクを出力実行結果:
こんにちは!東京にようこそ!どこか特定の場所に行く予定がありますか?それともおすすめの観光スポットやアクティビティを知りたいですか?お手伝いできることがあれば教えてくださいね。会話の実行(2回目)
過去の会話内容に基づいて質問に答える場合も、同じthread_idを指定して実行します。
# 過去の会話内容の質問応答
for chunk in agent_executor.stream(
{"messages": [HumanMessage(content="明日の天気は?")]}, config
):
print(chunk)
print("----")実行結果:
明日の東京の天気は「晴れ一時曇り」の予報です。快適な日になりそうですが、念のため軽い上着を持っておくと良いかもしれません。
何か他に知りたいことがあれば教えてくださいね!この例では、2回目の会話で「明日の天気は?」と質問しています。
エージェントは過去の会話履歴を参照し、東京に遊びに来ていることを理解した上で、明日の東京の天気予報を回答しています。
まとめ
最後までご覧いただきありがとうございました。