LLMの基本的な使い方
導入
ここからはGoogle colabで実装していきます。
LangChainをインストールするには、以下のコマンドを実行します。
# 必要なライブラリをインストール
!pip install langchain
!pip install langchain-openai次に環境変数の準備をします。
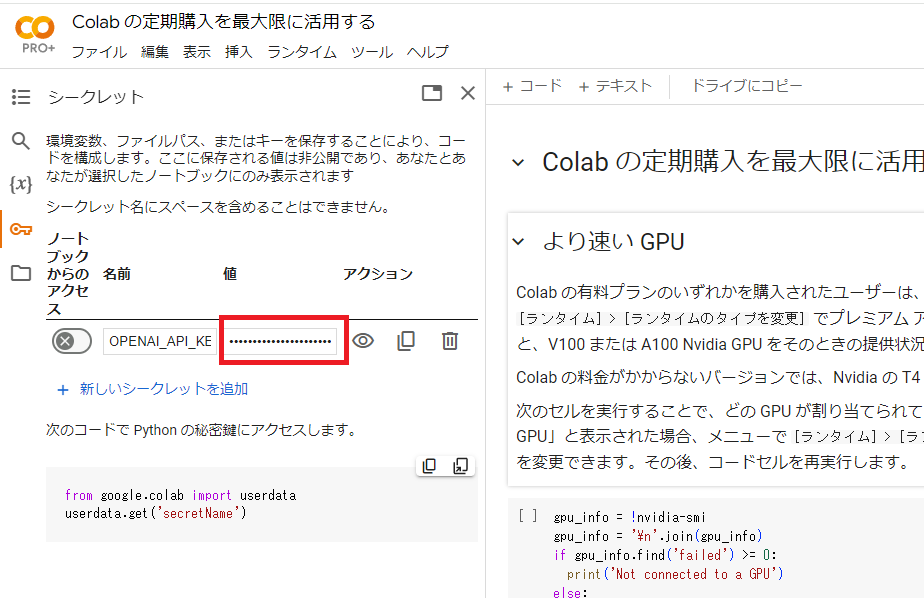
Google colabの左端にある鍵アイコンで「OPENAI_API_KEY」を設定します。
下図において、名前の欄に「OPENAI_API_KEY」、値の欄にご自身のAPIキーを入力してください。
なお、まだOpenAIのAPIキーを取得していない方は、こちらから取得することができます。
設定が終わったら、以下のコードを実行します。
import os
from google.colab import userdata
# 環境変数の準備
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")LLM単体の使い方
最初に言語モデル単体の使い方を紹介します。LangChainは相互に交換可能な様々な言語モデルをサポートしています。使用したいモデルを選択してください。
- OpenAI
- Anthropic
- Azure
- Cohere
- FireworksAI
- MistralAI
- TogetherAI
ここではOpenAIを例に説明します。
モデルはgpt-4oを使用します。
from langchain_openai import ChatOpenAI
# LLMの準備
llm = ChatOpenAI(model="gpt-4o")モデルを直接使ってみます。ChatModelはLangChainの"Runnable"のインスタンスで、それらと対話するための標準的なインターフェースを提供します。モデルを単純に呼び出すには、メッセージのリストを.invokeメソッドに渡します。
from langchain_core.messages import HumanMessage, SystemMessage
# メッセージリストの準備
messages = [
SystemMessage(content="日本語から英語に翻訳してください"),
HumanMessage(content="こんにちは!"),
]
# LLM呼び出し
llm.invoke(messages)実行結果:
AIMessage(content='Hello!', response_metadata={'token_usage': {'completion_tokens': 2, 'prompt_tokens': 22, 'total_tokens': 24}, 'model_name': 'gpt-4o', 'system_fingerprint': 'fp_319be4768e', 'finish_reason': 'stop', 'logprobs': None}, id='run-5520e88d-d7f0-440b-95b7-5f1ed169a8bd-0', usage_metadata={'input_tokens': 22, 'output_tokens': 2, 'total_tokens': 24})出力パーサー
上記はAIMessageであるため、文字列の応答と応答に関するその他のメタデータが含まれています。多くの場合、文字列の応答だけを扱いたいことがあります。これを実現するには、シンプルな出力パーサーを使用します。
from langchain_core.output_parsers import StrOutputParser
# 出力パーサーの準備
parser = StrOutputParser()
# LLMと出力パーサーを個別に実行
result = llm.invoke(messages)
parser.invoke(result)出力結果:
Hello!このパーサーでモデルを「チェーン」することができます。つまり、このチェーンでは、毎回このパーサーが呼び出されます。このチェーンは言語モデルの入力タイプ(文字列またはメッセージのリスト)を受け取り、パーサーの出力タイプ(文字列)を返します。
|演算子を使ってチェーンを簡単に作ることもできます。LangChainでは、2つの要素を結合するために|演算子が使われます。
# LLMと出力パーサーをチェーンでつなげて実行
chain = llm | parser
chain.invoke(messages)出力結果:
Hello!プロンプトテンプレート
LangChainを使った言語モデルへの入力は、通常、ユーザーからの生の入力とアプリケーションロジックを組み合わせて構築されます。アプリケーションロジックは、ユーザーの入力を加工し、言語モデルに渡す準備ができたメッセージのリストに変換します。よくある変換としては、システムメッセージの追加やユーザー入力によるテンプレートのフォーマットなどがあります。
LangChainの「プロンプトテンプレート」は、この変換を支援するためのものです。ユーザーの生の入力を受け取り、言語モデルに渡す準備ができたデータ(プロンプト)を返します。
プロンプトテンプレートの作成
ロンプトテンプレートを作成してみましょう。ここでは、次の2つのユーザー変数を受け取るテンプレートを作ります:
- language: テキストを翻訳する言語
- text: 翻訳するテキスト
システムメッセージとしてフォーマットする文字列とテキストを配置するためのシンプルなテンプレートを組み合わせて、PromptTemplateを作成します。
from langchain_core.prompts import ChatPromptTemplate
# プロンプトテンプレートの準備
prompt_template = ChatPromptTemplate.from_messages(
[
("system", "日本語から{language}に翻訳してください"),
("user", "{text}")
]
)このプロンプトテンプレートの入力は辞書です。テンプレート単体で動作を確認してみます。
これは、2つのメッセージから成るChatPromptValueを返します。メッセージに直接アクセスするには以下のようにします。
# プロンプトテンプレートを個別に実行
result = prompt_template.invoke({"language": "イタリア語", "text": "こんにちは"})
# ChatPromptValueをメッセージリストに変換
result.to_messages()実行結果:
[SystemMessage(content='日本語からイタリア語に翻訳してください'), HumanMessage(content='こんにちは')]プロンプトテンプレートとLLMと出力パーサーをチェーンでつなげて実行します。
# プロンプトテンプレートとLLMと出力パーサーをチェーンでつなげて実行
chain = prompt_template | llm | parser
chain.invoke({"language": "イタリア語", "text": "こんにちは"})実行結果:
Ciaoプロンプトテンプレートを使うことで、ユーザーの生の入力を言語モデルに渡す準備ができた形式に簡単に変換できます。システムメッセージの追加やユーザー入力へのテンプレートの適用など、様々なカスタマイズが可能です。
LangChainでのプロンプトテンプレートの活用により、言語モデルとのやり取りをよりスムーズに行えるでしょう。プロンプトテンプレートを適切に設計することで、言語モデルからより良い結果を得ることができます。
アプリの公開
作成したアプリケーションを公開するには、LangServeが便利です。LangServeを使えば、LangChainのチェーンをREST APIとして展開できます。FastAPIを使ってアプリを定義し、LangServeのadd_routesを使ってチェーンのルートを追加するだけで、すぐにAPIサーバーが立ち上がります。
LangServeで公開されたアプリケーションには、設定と呼び出しのためのシンプルなUIが付属しています。ストリーミング出力や中間ステップの可視化もサポートされており、動作確認に便利です。
プログラムからアプリケーションを呼び出したい場合は、RemoteRunnableを使うことで、クライアントサイドで実行されているかのようにチェーンを操作できます。
LangChainを使えば、初心者でも簡単にAIアプリケーションの開発を始められます。プロンプトテンプレートの作成、モデルとの連携、出力の解析、LCELでのチェーン化、LangSmithでの可観測性の向上、LangServeでのデプロイなど、AI開発に必要な基本的なスキルが身につきます。
まとめ
最後までご覧いただきありがとうございました。