会話の実装
langchainは、大規模言語モデル(LLM)を使ったアプリケーション開発を支援するPythonライブラリです。会話履歴を記憶し、文脈を踏まえた応答ができるチャットボットを簡単に作ることができます。
導入
ここからはGoogle colabで実装していきます。
LangChainをインストールするには、以下のコマンドを実行します。
# 必要なライブラリをインストール
!pip install langchain
!pip install langchain-openai
!pip install langchain_community次に環境変数の準備をします。
Google colabの左端にある鍵アイコンで「OPENAI_API_KEY」を設定します。
下図において、名前の欄に「OPENAI_API_KEY」、値の欄にご自身のAPIキーを入力してください。
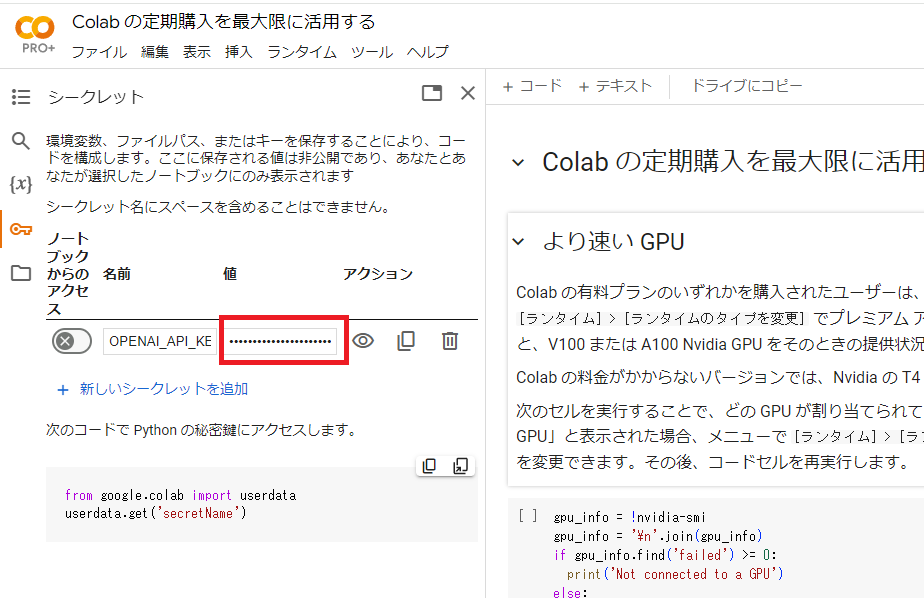
なお、まだOpenAIのAPIキーを取得していない方は、こちらから取得することができます。
設定が終わったら、以下のコードを実行します。
import os
from google.colab import userdata
# 環境変数の準備
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")使用したいモデルを選択してください。ここではgpt-4oを使用します。
from langchain_openai import ChatOpenAI
# LLMの準備
llm = ChatOpenAI(model="gpt-4o")会話
モデルを使って会話をすることができます。
from langchain_core.messages import HumanMessage
# 出力パーサーの準備
parser = StrOutputParser()
# 会話
result = llm.invoke([HumanMessage(content="こんにちは!私の名前はつくもちです。")])
parser.invoke(result)HumanMessageは、ユーザーの入力を表すクラスです。llm.invokeは、モデルにメッセージを渡して応答を取得します。StrOutputParserは、モデルの応答を文字列として解析するためのクラスです。
実行結果:
こんにちは、つくもちさん!お会いできて嬉しいです。今日はどんなお手伝いができますか?ただし、このままでは前の会話を覚えていないので、次に「私の名前は?」と聞いても適切に答えられません。
# 過去の会話内容についての質問
result = llm.invoke([HumanMessage(content="私の名前は?")])
parser.invoke(result)実行結果:
ごめんなさい、あなたの名前はわかりません。お手数ですが、教えていただけますか?このように、前の会話を覚えていないため、適切に応答できません。
チャットボットに会話履歴を記憶させるには、過去のメッセージもモデルに渡す必要があります。
from langchain_core.messages import AIMessage
# 会話履歴付きで過去の会話内容についての質問
result = llm.invoke(
[
HumanMessage(content="こんにちは! 私の名前はつくもちです。"),
AIMessage(content="こんにちは、つくもちさん!お会いできて嬉しいです。今日はどんなお手伝いができますか?"),
HumanMessage(content="私の名前は?"),
]
)
parser.invoke(result)実行結果:
あなたの名前は「つくもち」さんですね。どうぞよろしくお願いします!今日は何か特別なことがありますか?このようにメッセージの履歴をすべて渡せば、文脈に沿った応答が返ってきます。
実際のアプリケーション開発では、langchainのプロンプトテンプレートやチャット履歴機能を活用すると便利です。 また、LLMの挙動を把握するためにLangSmithでデバッグ・トレースするのも有効でしょう。
langchainを使えば、高度な言語理解能力を持つチャットボットを驚くほど簡単に作れます。 ユーザーの入力に加え、必要な情報を外部から取得して会話に反映させたり、チャットボットに実際のアクションを起こさせたりすることもできます。
チャットボットの会話履歴
LangChainには、モデルをステートフルにするためのMessage Historyクラスが用意されています。これを使うことで、モデルへの入力と出力を追跡し、データストアに保存することができます。将来のやりとりでは、これらのメッセージが読み込まれ、入力の一部としてチェーンに渡されます。
チェーンの設定
モデルをラップしてメッセージ履歴を追加するチェーンを設定します。ここで重要なのは、get_session_historyに渡す関数です。この関数は、session_idを受け取り、Message Historyオブジェクトを返すことが期待されています。session_idは、別々の会話を区別するために使用され、新しいチェーンを呼び出すときに設定の一部として渡す必要があります。
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
# 会話履歴の保存場所の準備
store = {}
# セッション毎の会話履歴の取得
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
# 会話履歴付きLLMの準備
message_history = RunnableWithMessageHistory(llm, get_session_history)次に、ランナブルに毎回渡すconfigを作成します。この設定には、入力の一部ではないが、有用な情報が含まれています。今回は、session_idを含めたいと思います。
# コンフィグの準備
config = {"configurable": {"session_id": "abc1"}}チャットボットとの対話
これで、チャットボットと会話ができるようになりました。session_idを変更すると、新しい会話が始まることがわかります。ただし、元の会話に戻ることもできます。
# 過去の会話内容についての質問
response = message_history.invoke(
[HumanMessage(content="私の名前は?")],
config=config,
)
response.content実行結果:
あなたの名前はつくもちさんですね。何か他にお手伝いできることがあれば教えてください!続けて会話をすることができます。
# 過去の会話内容についての質問
response = llm_with_history.invoke(
[HumanMessage(content="私の名前は?")],
config=config,
)
response.content実行結果:
あなたの名前は「つくもち」さんですね。何か他に知りたいことやお話したいことがあれば、ぜひ教えてください!これで、チャットボットが多くのユーザーと会話できるようになりました!
現時点では、モデルの周りにシンプルな永続化層を追加しただけです。プロンプトテンプレートを追加することで、より複雑でパーソナライズされたものにすることができます。
プロンプトテンプレート
シンプルなプロンプトテンプレートの例
最初は、シンプルなケースから見ていきましょう。ユーザーからのメッセージをそのままLLMに渡す場合、ChatPromptTemplateを使ってシステムメッセージを追加できます。
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages(
[
("system", "あなたは親切なアシスタントです。できる限りすべての質問に答えてください。"),
MessagesPlaceholder(variable_name="messages"),
]
)
chain = prompt | llmここでは、ChatPromptTemplateを使用して、システムメッセージとユーザーからのメッセージを組み合わせたプロンプトテンプレートを作成しています。MessagesPlaceholderは、ユーザーからのメッセージを受け取るためのプレースホルダーです。作成したプロンプトテンプレートをllmと組み合わせることで、chainを作成します。
これで、chainを呼び出すときに、言語を選択して渡せるようになりました。
response = chain.invoke(
{"messages": [HumanMessage(content="こんにちは!私はボブです")], "language": "日本語"}
)
response.content実行結果:
こんにちは、ボブさん!お会いできて嬉しいです。今日はどんなことについてお話ししますか?この例では、ユーザーからのメッセージ「こんにちは!私はボブです」と言語「日本語」を指定してchainを呼び出しています。
LLMは、システムメッセージとユーザーメッセージを組み合わせたプロンプトに基づいて応答を生成します。
Message Historyの利用
先ほどと同様にMessage Historyクラスとコンフィグの準備をします。
先ほどとは別なsession_idを用意します。
# 会話履歴付きLLMの準備
message_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="messages",
)
# コンフィグの準備
config = {"configurable": {"session_id": "abc2"}}ここでは、RunnableWithMessageHistoryを使用して、会話履歴を保持するLLMを準備しています。get_session_historyは、会話履歴を取得するための関数です。また、configで新しいセッションIDを指定しています。
会話の実行
プロンプトテンプレートを用いた会話を実行します。
# 会話(1回目)
response = message_history.invoke(
{"messages": [HumanMessage(content="こんにちは! 私の名前はつくもちです。")], "language": "日本語"},
config=config,
)
response.content実行結果:
こんにちは、つくもちさん!今日はどのようなお手伝いをしましょうか?続けて2回目の会話を実行します。
# 会話(2回目)
response = message_history.invoke(
{"messages": [HumanMessage(content="私の名前は?")], "language": "日本語"},
config=config,
)
response.content実行結果:
あなたの名前は「つくもち」さんですね。どうぞよろしくお願いします!この例では、1回目の会話でユーザーが「こんにちは! 私の名前はつくもちです。」と発言し、2回目の会話で「私の名前は?」と質問しています。
LLMは、会話履歴を保持しているため、1回目の会話でユーザーが名前を「つくもち」と言ったことを覚えており、2回目の質問に適切に応答することができます。
これで、複数の会話ターンにわたってユーザーの入力を追跡できるようになりました。
チャットボットの会話履歴を管理する方法
チャットボットを開発する上で重要な概念の一つに、会話履歴の管理があります。適切に管理されていない場合、メッセージのリストは際限なく増え続け、最終的にはLLMのコンテキストウィンドウをオーバーフローしてしまう可能性があります。そのため、渡すメッセージのサイズを制限するステップを追加することが重要です。
会話履歴の管理方法
会話履歴を管理するには、以下の手順を踏む必要があります。
- プロンプトテンプレートを適用する前に、Message Historyから過去のメッセージを読み込む
- 読み込んだメッセージを適切に修正するステップを追加する
- 修正したメッセージを新しいチェーンでラップする
具体的には、プロンプトの前にmessagesキーを適切に修正する簡単なステップを追加し、その新しいチェーンをMessage Historyクラスでラップします。
まず、渡されたメッセージを修正する関数を定義しましょう。最新のK個のメッセージを選択するようにします。そして、その関数を先頭に追加して新しいチェーンを作成します。
from langchain_core.runnables import RunnablePassthrough
# メッセージフィルタ (最近のk個のメッセージ)
def filter_messages(messages, k=4):
return messages[-k:]
# チェーンの準備
chain = (
RunnablePassthrough.assign(messages=lambda x: filter_messages(x["messages"]))
| prompt
| llm
)このコードでは、RunnablePassthroughを使用して、messagesキーの値を修正する関数(filter_messages)を適用しています。filter_messages関数は、与えられたメッセージリストの最後のk個のメッセージを返します。
次に、Message Historyクラスとコンフィグの準備を行います。 先ほどのコードとは別なsession_idを用意します。
# 会話履歴付きLLMの準備
message_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="messages",
)
# コンフィグの準備
config = {"configurable": {"session_id": "abc3"}}ここで、RunnableWithMessageHistoryを使用して、先ほど作成したチェーン(chain)、セッション履歴を取得する関数(get_session_history)、およびメッセージのキー名(input_messages_key)を指定しています。
また、コンフィグにはsession_idを指定します。これは会話履歴を一意に識別するために使用されます。
これで準備は完了です。実際に会話を行ってみましょう。
会話1回目
# 会話
response = message_history.invoke(
{"messages": [HumanMessage(content="こんにちは! 私の名前はつくもちです。")], "language": "日本語"},
config=config,
)
response.content実行結果:
こんにちは、つくもちさん!お知らせいただきありがとうございます。今日はどのようなことでお手伝いできますか?会話2回目
# 過去の会話内容についての質問
response = message_history.invoke(
{"messages": [HumanMessage(content="私の名前は?")], "language": "日本語"},
config=config,
)
response.content実行結果:
あなたの名前はつくもちさんですね。ほかに何かお手伝いできることはありますか?ここでは、1回目の会話で名乗った名前を覚えていることがわかります。
会話3回目
# 過去の会話内容についての質問
response = message_history.invoke(
{"messages": [HumanMessage(content="私の名前は?")], "language": "日本語"},
config=config,
)
response.content実行結果:
申し訳ありませんが、以前のメッセージの履歴は保持されていません。そのため、あなたの名前はわかりません。お名前を教えていただけますか?3回目の会話では、filter_messagesで最新の4つのメッセージのみを保持するように設定したため、1回目の会話内容が失われ、名前を覚えていないことがわかります。
このように、会話履歴の管理は、メモリ使用量とコンテキストの保持のバランスを取ることが重要です。適切な設定を行うことで、自然な会話の流れを実現しつつ、メモリ使用量を抑えることができるようになります。
まとめ
最後までご覧いただきありがとうございました。

