RAG(Retrieval-Augmented Generation)とは
RAG(Retrieval-Augmented Generation)は、生成(Generation)と情報取得(Retrieval)を組み合わせたAIフレームワークであり、LLM(大規模言語モデル)の限界を克服するための技術です。通常、LLMはトレーニングデータに基づいて応答を生成しますが、そのデータは固定されており、時には古くなったり不完全な場合があります。RAGを使うと、LLMは外部の情報源から最新のデータを取得し、それを基に応答を生成できます。これにより、より正確でコンテキストに沿った回答が可能になり、例えば最新のニュースや研究データを取り入れることで、ユーザーに提供する情報が常に新鮮で関連性の高いものとなります。
また、RAGは生成された応答に情報源を明示することができるため、ユーザーはその情報の信憑性を確認することができます。これにより、LLMを使用したアプリケーションに対する信頼感が増し、安心して利用できるようになります。開発者にとってもRAGは非常に有用で、提供する情報源を柔軟に変更でき、異なる用途や要件に応じてモデルを調整することが可能です。具体的な利用例としては、カスタマーサポートのチャットボットや医療情報システムが挙げられます。カスタマーサポートでは、製品の最新情報や顧客の履歴データを取得して、より適切な対応が可能になり、医療分野では、最新の医学研究やガイドラインに基づいて患者に安全で正確なアドバイスを提供できます。
langchainを用いることで、会話履歴を記憶し、文脈を踏まえた応答ができるチャットボットを簡単に作ることができます。
Documentクラス
導入
ここからはGoogle colabで実装していきます。
LangChainをインストールするには、以下のコマンドを実行します。
# 必要なライブラリをインストール
!pip install langchain
!pip install langchain-openai
!pip install langchain-community
!pip install langchain-chroma次に環境変数の準備をします。
Google colabの左端にある鍵アイコンで「OPENAI_API_KEY」を設定します。
下図において、名前の欄に「OPENAI_API_KEY」、値の欄にご自身のAPIキーを入力してください。
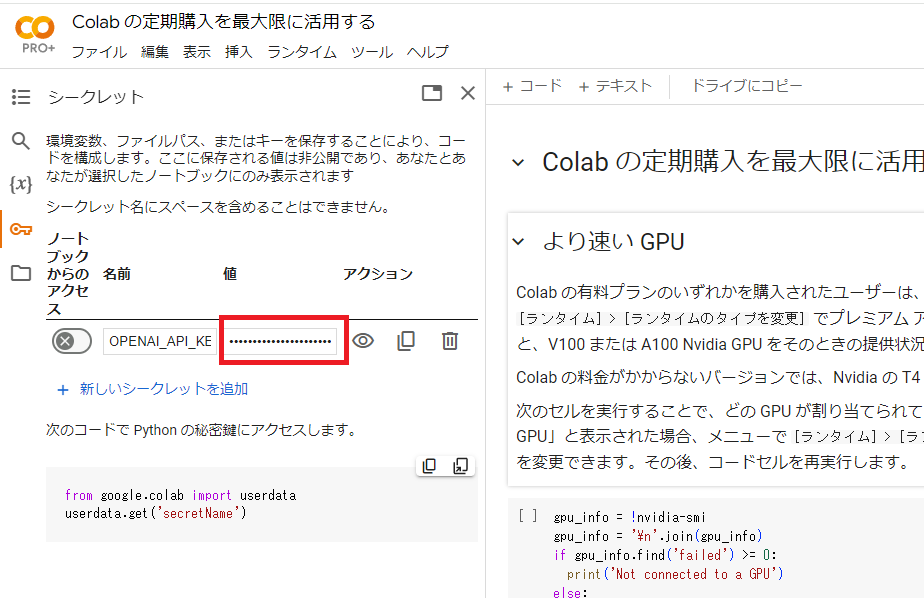
なお、まだOpenAIのAPIキーを取得していない方は、こちらから取得することができます。
設定が終わったら、以下のコードを実行します。
import os
from google.colab import userdata
# 環境変数の準備
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")使用したいモデルを選択してください。ここではgpt-4oを使用します。
from langchain_openai import ChatOpenAI
# LLMの準備
llm = ChatOpenAI(model="gpt-4o")Documentクラスの概要
LangChainはテキストの単位とメタデータを表現するためのDocumentクラスを提供しています。主な属性は以下の2つです。
- page_content: テキストの内容を表す文字列
- metadata: 任意のメタデータを含む辞書
metadataには、ドキュメントのソース、他のドキュメントとの関係、その他の情報を含めることができます。1つのDocumentオブジェクトは、多くの場合、より大きなドキュメントの一部を表します。
サンプルのDocumentを作成してみましょう。
from langchain_core.documents import Document
documents = [
Document(
page_content="犬は忠実でフレンドリーな性格で知られる素晴らしい伴侶です。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="猫は自分のスペースを好む独立心の強いペットです。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="金魚は初心者にも人気のペットで、比較的簡単に飼育できます。",
metadata={"source": "fish-pets-doc"},
),
Document(
page_content="オウムは人間の声を真似することができる賢い鳥です。",
metadata={"source": "bird-pets-doc"},
),
Document(
page_content="ウサギは社交的な動物で、跳ね回るためのスペースが必要です。",
metadata={"source": "mammal-pets-doc"},
),
]ここでは、3つの異なる"source"を示すメタデータを含む5つのDocumentを作成しました。
VectorStore
LangChainの中核となるのがVectorStoreという概念です。VectorStoreは、テキストデータを数値のベクトルに変換して保存するための仕組みです。これにより、テキストの類似性を計算して、関連するデータを高速に検索することができます。
LangChainでVectorStoreを使うには、まず、テキストデータをベクトルに変換するための埋め込みモデル(Embeddingモデル)を用意する必要があります。ここでは、OpenAIのEmbeddingモデルを使ってみましょう。
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
vectorstore = Chroma.from_documents(
documents,
embedding=OpenAIEmbeddings()
)これで、documentsというリストに格納されたテキストデータがVectorStoreに追加されました。
documentsはDocument型のリストで、各ドキュメントにはpage_contentとmetadataが含まれています。
page_contentにはドキュメントの本文、metadataにはドキュメントのメタデータ(ソースなど)が格納されます。
similarity_search
次に、VectorStoreに対して検索を行ってみましょう。
たとえば、「猫」に関連するドキュメントを探すには、以下のようにします。
vectorstore.similarity_search("猫")実行結果:
[Document(page_content='猫は自分のスペースを好む独立心の強いペットです。', metadata={'source': 'mammal-pets-doc'}),
Document(page_content='犬は忠実でフレンドリーな性格で知られる素晴らしい伴侶です。', metadata={'source': 'mammal-pets-doc'}),
Document(page_content='ウサギは社交的な動物で、跳ね回るためのスペースが必要です。', metadata={'source': 'mammal-pets-doc'}),
Document(page_content='金魚は初心者にも人気のペットで、比較的簡単に飼育できます。', metadata={'source': 'fish-pets-doc'})]猫に関係する文章が上位に来ていることがわかります。
similarity_searchは、指定したクエリ(この例では「猫」)に類似するドキュメントを、類似度が高い順にリストで返します。
similarity_search_with_score
スコアも一緒に取得したい場合は、similarity_search_with_score()メソッドを使います。
vectorstore.similarity_search_with_score("猫")実行結果:
[(Document(page_content='猫は自分のスペースを好む独立心の強いペットです。', metadata={'source': 'mammal-pets-doc'}),
0.2877156734466553),
(Document(page_content='犬は忠実でフレンドリーな性格で知られる素晴らしい伴侶です。', metadata={'source': 'mammal-pets-doc'}),
0.4049242436885834),
(Document(page_content='ウサギは社交的な動物で、跳ね回るためのスペースが必要です。', metadata={'source': 'mammal-pets-doc'}),
0.41790103912353516),
(Document(page_content='金魚は初心者にも人気のペットで、比較的簡単に飼育できます。', metadata={'source': 'fish-pets-doc'}),
0.4264119863510132)]asimilarity_search
VectorStoreは非同期に検索することもできます。
await vectorstore.asimilarity_search("猫")実行結果:
[Document(page_content='猫は自分のスペースを好む独立心の強いペットです。', metadata={'source': 'mammal-pets-doc'}),
Document(page_content='犬は忠実でフレンドリーな性格で知られる素晴らしい伴侶です。', metadata={'source': 'mammal-pets-doc'}),
Document(page_content='ウサギは社交的な動物で、跳ね回るためのスペースが必要です。', metadata={'source': 'mammal-pets-doc'}),
Document(page_content='金魚は初心者にも人気のペットで、比較的簡単に飼育できます。', metadata={'source': 'fish-pets-doc'})]asimilarity_searchは、similarity_searchの非同期版です。
大量のデータを検索する場合や、他の非同期処理と組み合わせる場合に便利です。
similarity_search_by_vector
検索クエリを直接ベクトルで指定することもできます。
await vectorstore.asimilarity_search("猫")実行結果:
[Document(page_content='猫は自分のスペースを好む独立心の強いペットです。', metadata={'source': 'mammal-pets-doc'}),
Document(page_content='犬は忠実でフレンドリーな性格で知られる素晴らしい伴侶です。', metadata={'source': 'mammal-pets-doc'}),
Document(page_content='ウサギは社交的な動物で、跳ね回るためのスペースが必要です。', metadata={'source': 'mammal-pets-doc'}),
Document(page_content='金魚は初心者にも人気のペットで、比較的簡単に飼育できます。', metadata={'source': 'fish-pets-doc'})]Retrievers
Retrieverとは
Retrieverは、与えられたクエリに対して関連性の高いドキュメントを取得するコンポーネントです。
LangChainでは、Retrieverを使うことで、大量のドキュメントの中から必要な情報を効率的に見つけ出すことができます。
VectorStoreRetrieverの作成
LangChainのVectorStoreオブジェクトをそのままRetrieverとして使うことはできませんが、as_retrieverメソッドを使うことで、簡単にRetrieverを作成できます。
以下は、similarity_searchメソッドを使ってRetrieverを作成する例です。
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 1},
)ここでは、search_typeに"similarity"を指定し、search_kwargsで検索結果の数を1に設定しています。
similarity_searchメソッドは、クエリベクトルとドキュメントベクトルのコサイン類似度を計算し、類似度の高い上位k件のドキュメントを返します。
作成したRetrieverは、batchメソッドを使って複数のクエリを一度に処理できます。
以下は、"猫"と"魚"というクエリを処理する例です。
# Retrieverの実行
retriever.batch(["猫", "魚"])実行結果:
[[Document(page_content='猫は自分のスペースを好む独立心の強いペットです。', metadata={'source': 'mammal-pets-doc'})],
[Document(page_content='金魚は初心者にも人気のペットで、比較的簡単に飼育できます。', metadata={'source': 'fish-pets-doc'})]]batchメソッドに渡された各クエリに対して、Retrieverが最も関連性の高いドキュメントを1件ずつ取得しています。
RAGへの応用
Retrieverは、より複雑なアプリケーションに組み込むこともできます。例えば、Retrieval-Augmented Generation (RAG)では、与えられた質問と関連するコンテキストを組み合わせてプロンプトを作成し、言語モデル(LLM)に入力します。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
# プロンプトテンプレートの準備
message = """
提供されたコンテキストのみを使用して、この質問に答えてください。
{question}
Context:
{context}
"""
prompt = ChatPromptTemplate.from_messages([("human", message)])
# RAGチェーンの準備
rag_chain = {"context": retriever, "question": RunnablePassthrough()} | prompt | llm
# 質問応答
response = rag_chain.invoke("猫について教えてください")
print(response.content)実行結果:
猫は独立心が強く、自分のスペースを好むペットです。RAGチェーンでは、まずretrieverを使って "猫について教えてください" という質問に関連するコンテキストを取得します。
次に、取得したコンテキストと質問をプロンプトテンプレートに埋め込み、LLMに入力します。
LLMは、与えられたコンテキストを使って質問に答えを生成し、その結果が最終的な出力になります。
まとめ
最後までご覧いただきありがとうございました。

