LangChainの概要
LangChainとは
LangChainは、ChatGPTをはじめとする大規模言語モデルを効率的に拡張するためのライブラリです。LangChainを使用することで、独自データの読み込み、Google検索の実行、LLMが苦手とする計算問題の解決など、様々な機能が利用可能となります。これにより、高度な処理や知識の組み合わせが可能となり、パフォーマンスの向上や複雑な処理の実現が期待されます。
ChatGPTなどのモデルでは最新情報に対応していない、長文を入力できない、複雑な計算問題に回答できないなどの課題がありますが、LangChainを用いることで、これらの課題への対処が可能となります。
例えば、長いPDFの文章に関する質問への回答が必要な場合、LangChainを使用することで簡単に実装が可能となります。このような機能は、LangChainを使用しなくても実装できることがありますが、LangChainではこれらの機能がパッケージ化されており簡単に実装することが可能です。
LangChain v0.1→v0.2の主な変更点
「LangChain v0.2」は 2024 年 5 月にリリースされました。主な変更点は以下の通りです。
- パッケージの分離: v0.2の主要な変更点の1つは、
langchainパッケージをlangchain-communityから分離したことです。この変更により、以前はlangchain-communityに含まれていたオプションの依存関係やサードパーティの統合を取り除くことで、langchainがより軽量でセキュアに、そして重点的になりました。 - バージョン管理されたドキュメンテーション: ドキュメンテーションが刷新され、バージョン管理が導入されました。これにより、ユーザーが使用しているバージョンに対応した関連情報を見つけやすくなりました。新しいドキュメンテーション構造はよりフラットでシンプルになり、チュートリアル、ハウツーガイド、概念ガイド、APIリファレンスに整理されています。
- ストリーミングと非同期操作のサポート改善: LangChain v0.2では、ストリーミングと非同期操作のサポートが強化され、リアルタイムのデータ処理を必要とするアプリケーションにとってより堅牢になりました。
- エージェント用のLangGraph: エージェントのワークフローのカスタマイズを改善するために、LangGraphという新しいコンポーネントが導入されました。LangGraphは、LangChain Expression Language(LCEL)をベースに、サイクル定義や組み込みメモリなどの機能を追加し、エージェントワークロードの作成とカスタマイズを容易にします。
- 標準化されたインターフェース: 異なる大規模言語モデル(LLM)間のシームレスな切り替えを可能にするため、v0.2ではツール呼び出しのサポートを標準化し、出力を構造化するための一貫したインターフェースを提供しています。
- パートナー統合: LangChain v0.2には、多数のエコシステムパートナーとの安定した信頼性の高い統合が含まれており、様々な外部サービスやツールとの互換性が向上しています。
主なユースケース
①RAG(Retrieval Augmented Generation)によるQA
RAGは、大規模言語モデル(LLM)の知識を追加データで拡張するための手法です。LLMは幅広いトピックについて推論できますが、その知識は特定の時点までの公開データに限定されています。そのため、非公開データやモデルのカットオフ日以降に導入されたデータについて推論するAIアプリケーションを構築するには、モデルの知識を必要な特定の情報で拡張する必要があります。適切な情報を持ってきてモデルのプロンプトに挿入するプロセスは、Retrieval Augmented Generation(RAG)と呼ばれています。
典型的なRAGアプリケーションには、主に2つのコンポーネントがあります。1つ目は、データをソースから取り込んでインデックス化するためのパイプラインで、これは通常オフラインで行われます。2つ目は、実際のRAGチェーンで、実行時にユーザークエリを受け取り、インデックスから関連データを取得して、それをモデルに渡します。
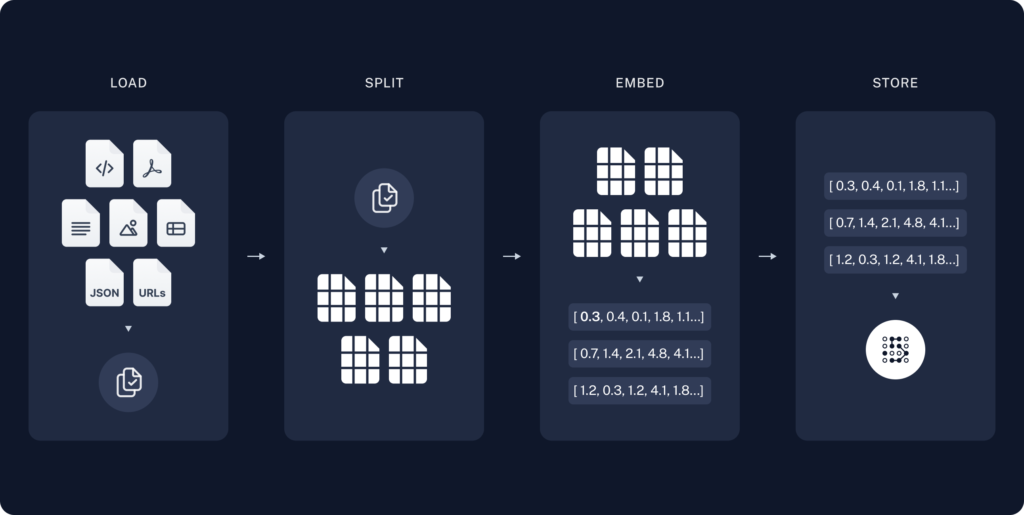
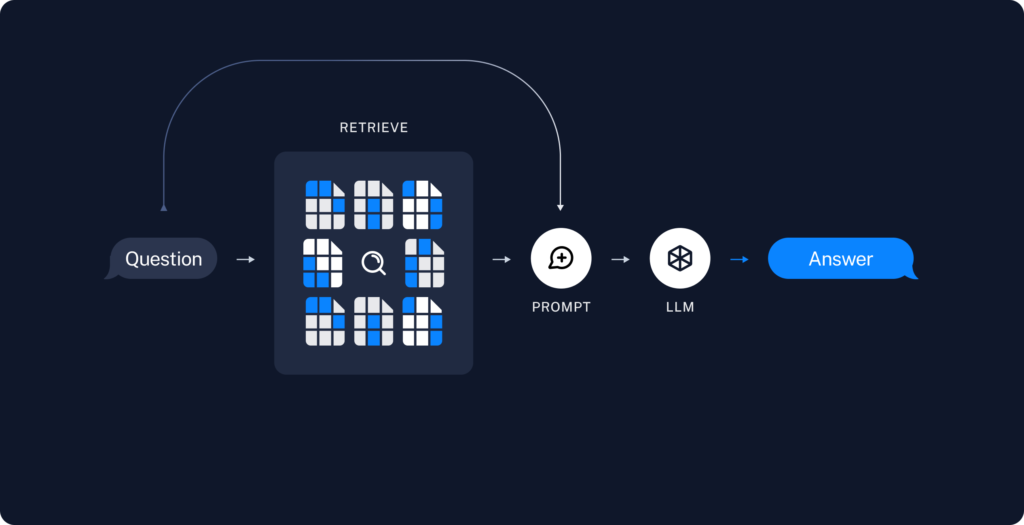
生データから回答までの最も一般的な一連の流れは、次のようになります。まず、DocumentLoadersを使用してデータを読み込みます。次に、Text splittersを使って大きなDocumentsを smaller chunksに分割します。これは、大きなチャンクは検索が難しく、モデルの有限なコンテキストウィンドウに収まらないため、データのインデックス化とモデルへの渡しの両方に役立ちます。そして、VectorStoreとEmbeddingsモデルを使用して、分割したデータを保存してインデックス化し、後で検索できるようにします。
ユーザーの入力に対して、Retrieverを使用してストレージから関連する分割データを取得し、ChatModel/LLMが質問と取得したデータを含むプロンプトを使用して回答を生成します。LangChainには、Q&Aアプリケーション、より一般的にはRAGアプリケーションを構築するのに役立つ多くのコンポーネントが用意されています。
②情報抽出
大規模言語モデル(LLM)は情報抽出アプリケーションを強力に支える技術として注目を集めています。従来の情報抽出ソリューションは、人手、手作業で作成された多数のルール(正規表現など)、カスタムのファインチューニング済みMLモデルの組み合わせに依存していました。しかし、そのようなシステムは時間とともに複雑になり、メンテナンスコストが高くなり、拡張が困難になる傾向がありました。
一方、LLMは適切な指示と参照例を与えるだけで、特定の抽出タスクにすばやく適応させることができます。LLMを使った情報抽出には、大きく分けて3つのアプローチがあります。
1つ目は、ツール/関数呼び出しモードをサポートしているLLMを使う方法です。これらのLLMは、与えられたスキーマに従って出力を構造化できます。一般的に、このアプローチは最も扱いやすく、良好な結果が期待できます。
2つ目は、JSONモードを使う方法です。一部のLLMは、有効なJSONを出力するように強制できます。これは、ツール/関数呼び出しアプローチと似ていますが、スキーマはプロンプトの一部として提供されます。一般的に、このアプローチはツール/関数呼び出しアプローチよりも性能が劣ると考えられていますが、自分のユースケースで検証することをお勧めします。
3つ目は、プロンプトベースのアプローチです。指示に従うことができるLLMは、目的の形式でテキストを生成するように指示できます。生成されたテキストは、既存の出力パーサーまたはカスタムパーサーを使用してJSONなどの構造化された形式に解析できます。このアプローチは、JSONモードやツール/関数呼び出しモードをサポートしていないLLMでも使用できます。より広く適用可能ですが、抽出やファンクションコール用にファインチューニングされたモデルよりも結果が悪くなる可能性があります。
LangChainには、パフォーマンス向上のためのガイドラインや、PDFなどのファイルからの抽出例、プロンプトベースのアプローチの使用方法など、情報抽出を効果的に行うためのリソースが豊富に用意されています。
③チャットボット
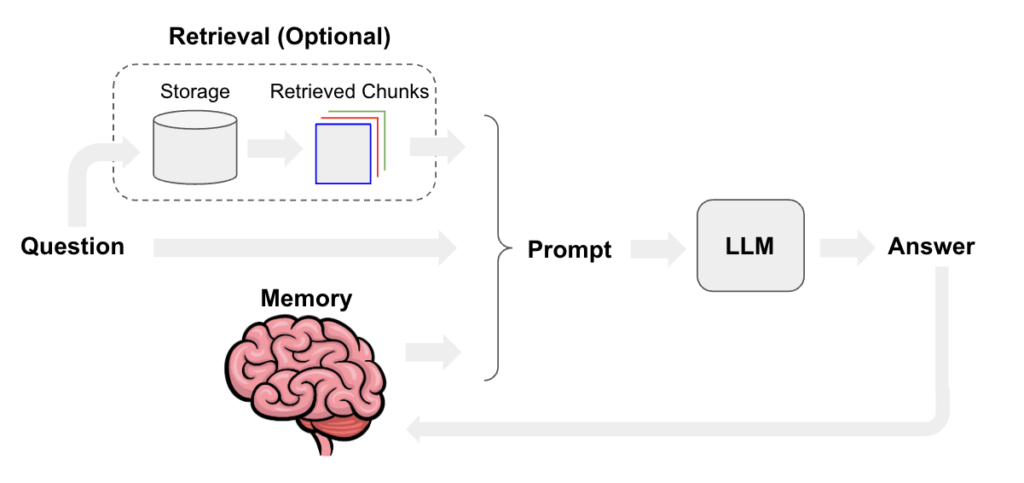
チャットボットの設計には、期待される質問の種類に応じて、様々な手法を組み合わせることが必要です。例えば、ドメイン特化型の質問により良く答えるために、プライベートデータを用いたRetrieval-Augmented Generation(RAG)がよく使われます。最終的な質問応答に最も関連性の高いコンテキストだけを使うために、複数のデータソース間でルーティングを行うことや、単なるメッセージのやり取り以上に特殊化されたチャット履歴やメモリを使うことを選択するのも一つの方法です。
このような最適化によって、チャットボットはより強力になりますが、レイテンシーと複雑さが増すというトレードオフがあります。このガイドでは、様々な機能の実装方法の概要を説明し、特定のユースケースに合わせてチャットボットをカスタマイズする手助けをすることを目的としています。
ガイドの内容は、クイックスタートから始まり、メモリ管理、検索、ツールの使用といったセクションに分かれています。クイックスタートでは、以降のガイドで前提とされるアーキテクチャを十分に理解できるようになります。メモリ管理のセクションでは、前回までの会話から情報を扱うための様々な戦略を、検索のセクションでは、外部データソースをコンテキストとして使う方法を、そしてツールの使用のセクションでは、他のシステムやAPIとのインタラクションを可能にするツールを追加することで、チャットボットを会話型エージェントに変える方法をカバーしています。
④ツールとエージェント
LangChainは、モデルの出力からJSON、XML、OpenAI関数呼び出しなどを抽出するための優れたモデル出力解析機能を持ち、多数の組み込みツールを提供しています。また、これらのツールを呼び出す際の柔軟性も高いのが特徴です。
ツールを使用する主な方法には、チェーンとエージェントの2つがあります。チェーンでは、ツールの使用順序を事前に定義することができます。一方、エージェントでは、モデルがループ内でツールを使用できるため、ツールを何回使用するかをモデル自身が決定することができます。つまり、チェーンはツールの使用順序が固定されたシナリオに適しているのに対し、エージェントは状況に応じてツールの使用回数や順序を動的に変更する必要があるようなより柔軟なシナリオに適しているといえます。
LangChainのツールとエージェントを活用することで、LLMの強力な言語理解・生成能力と、外部ツールの機能を組み合わせた高度なアプリケーションを構築することができます。

⑤クエリ解析
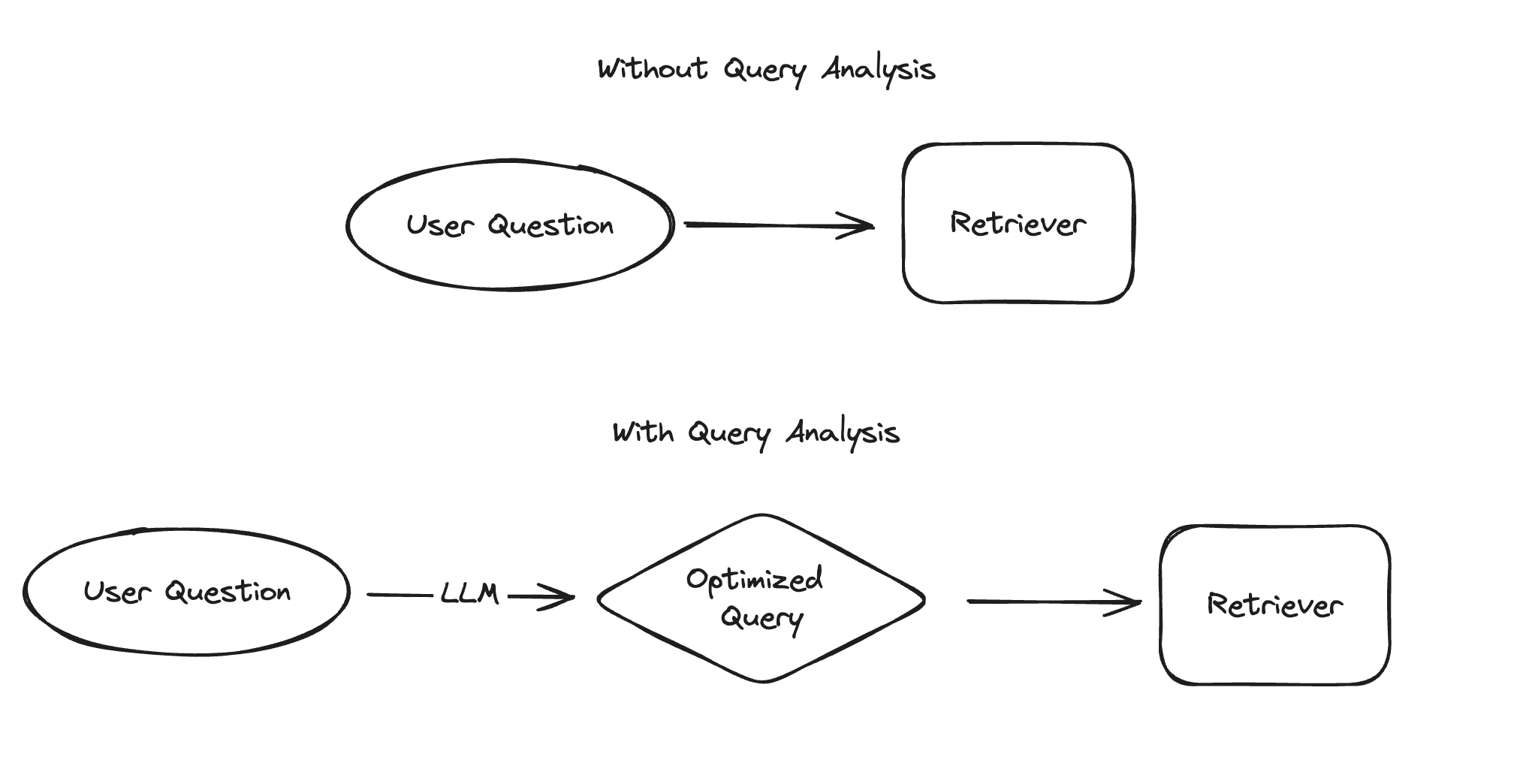
LangChainのクエリ解析は、ユーザーからの質問や入力をより最適化されたクエリに変換することで、検索やRetrieval Augmented Generationなどの性能を向上させる手法です。従来のルールベースの手法に加え、大規模言語モデル(LLM)を活用することで、より柔軟かつ効果的なクエリ最適化が可能になっています。
クエリ解析が特に有効なのは、検索対象のデータにフィールドが存在する場合、ユーザーの入力に複数の質問が含まれている場合、関連情報を取得するために複数のクエリが必要な場合、検索品質が表現方法に大きく左右される場合、複数の検索システムが存在する場合などです。ただし、問題の性質によって適切なクエリ解析手法は異なるため、現在の検索システムの課題を正確に把握することが重要です。
LangChainでは、クエリ分解、クエリ拡張、仮想ドキュメント埋め込み(HyDE)、クエリルーティング、ステップバックプロンプティング、クエリ構造化など、様々なクエリ解析手法をサポートしています。これらの手法を適切に組み合わせることで、ユーザーの質問意図をより正確に理解し、関連性の高い結果を得ることができます。
クエリ解析を効果的に行うためには、プロンプトにサンプルを追加したり、カテゴリカル変数の扱い方を工夫したり、複数のクエリや検索システムを適切に処理したりするなど、様々なテクニックが必要です。LangChainは、これらのテクニックを実装するためのガイドやツールを提供しており、開発者がスムーズにクエリ解析を導入できるようサポートしています。
⑥SQLデータベースに対する質問応答システム
SQLAlchemyでサポートされているMySQL、PostgreSQL、Oracle SQL、Databricks、SQLiteなどの様々なSQLデータベースと互換性のあるチェーンとエージェントが内蔵されており、自然言語の質問に基づいて実行されるクエリの生成、データベースのデータに基づいて質問に答えることができるチャットボットの作成、ユーザーが分析したい洞察に基づくカスタムダッシュボードの構築など、幅広いユースケースに対応できます。
ただし、SQLデータベースの質問応答システムを構築する際には、モデルが生成したSQLクエリを実行する必要があるため、セキュリティ上のリスクがあることに注意が必要です。チェーンやエージェントのニーズに合わせて、データベース接続の権限を可能な限り狭く設定することが重要です。これにより、モデル駆動型システムを構築する際のリスクを軽減できますが、完全に排除することはできません。
LangChainでSQLデータベースを操作するには、クイックスタートガイドから始めることができます。基本的な使い方に慣れたら、エージェントの構築、SQLクエリ生成の改善戦略、SQLクエリの検証、多数のテーブルや高基数の列を持つデータベースとのインタラクションなど、より高度なガイドに進むことができます。
⑦グラフデータベースに対する質問応答システム
グラフデータベースに対して自然言語で質問をすることで、必要な情報を取得できる機能です。LangChainには、Cypher、SparQL、Neo4j、MemGraph、Amazon Neptune、Kùzu、OntoText、Tigergraghなど、様々なグラフクエリ言語やデータベースに対応したチェーンやエージェントが用意されています。これらを活用することで、自然言語の質問からクエリを生成してデータベースを検索したり、データベースのデータを基にチャットボットが質問に答えたり、ユーザーが分析したい内容に基づいてカスタムダッシュボードを作成したりといった、様々なユースケースを実現できます。
ただし、モデルが生成したデータベースクエリを実行することには、セキュリティ上のリスクが伴うため、データベース接続の権限を必要最小限に設定するなどの対策が重要です。また、セマンティック層でデータベースクエリテンプレートを活用することで、クエリ生成の必要がなくなり、セキュリティの脆弱性を回避できるというメリットもあります。
LangChainのグラフデータベースQAを使いこなすには、基本的な使い方を理解した上で、プロンプト戦略、質問から値をマッピングする手法、セマンティック層の実装方法、ナレッジグラフの構築技術など、より高度なガイドを参考にすると良いでしょう。

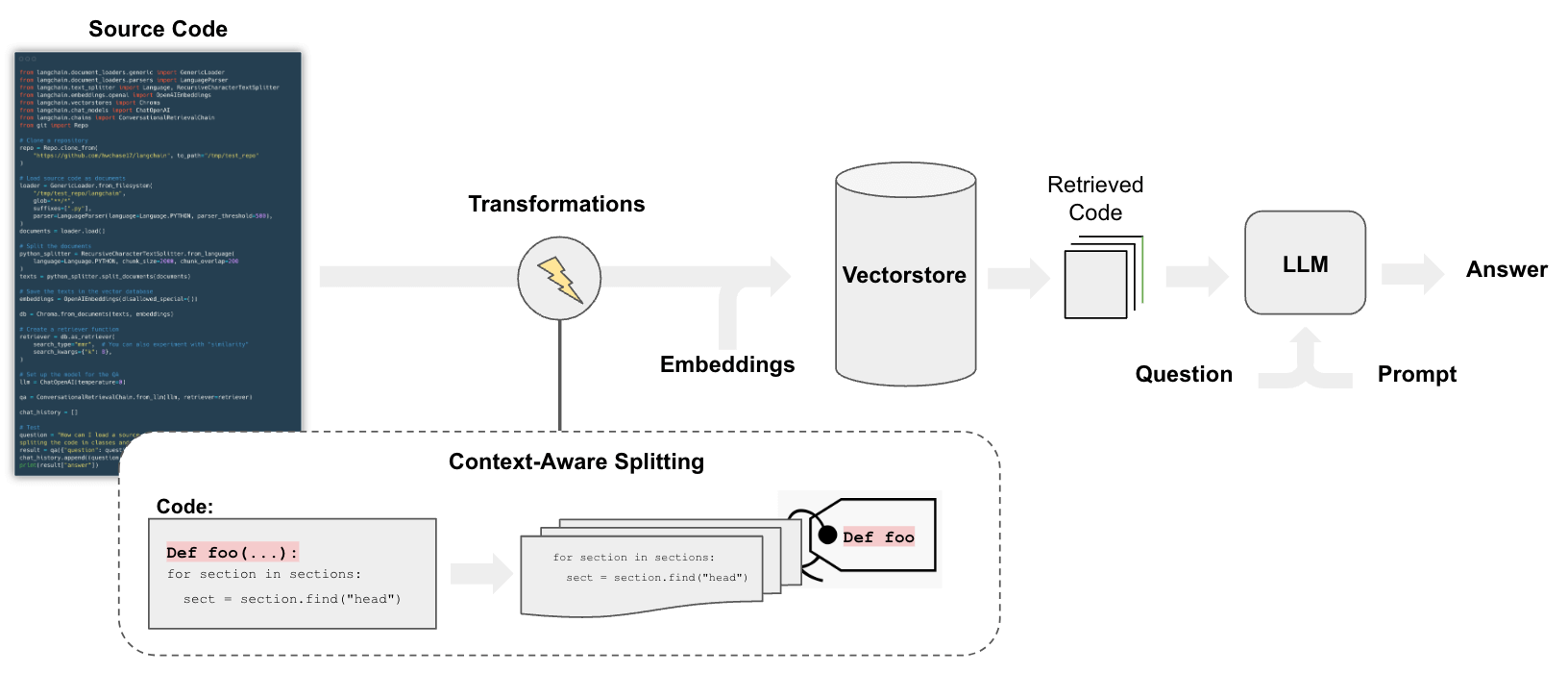
⑧コードの分析や理解
LangChainを用いることで、ソースコードの分析や理解をAI言語モデル(LLM)を活用して効率的に行うことができます。例えば、コードベースに関するQ&Aを通してコードの動作を理解したり、LLMによるリファクタリングや改善の提案を得たり、コードのドキュメント化などに役立てることができます。
Code understandingのパイプラインは、基本的にはドキュメントのQ&Aと同様のステップを踏みますが、いくつかの違いがあります。特に、コードを分割する際のストラテジーとして、各トップレベルの関数やクラスを個別のドキュメントとして扱い、残りのコードは別のドキュメントにまとめるようにします。その際、各分割の由来に関するメタデータを保持しておくことが重要です。
具体的な手順としては、まずPythonプロジェクトのファイルをTextLoaderを使ってアップロードし、LanguageParserでPythonコードを読み込みます。これにより、トップレベルの関数やクラスをまとめて1つのドキュメントとして扱い、残りのコードを別のドキュメントに分割しつつ、各分割の由来のメタデータを保持します。
次に、RecursiveCharacterTextSplitterを使ってドキュメントを埋め込みとベクトルストレージ用のチャンクに分割します。そして、ChromaなどのベクトルストアにOpenAIEmbeddingsを用いてドキュメントを保存し、意味的な検索ができるようにします。
最後に、ChatOpenAIなどのLLMを使ってチャットインターフェースを構築し、ユーザーからの質問に対して、検索クエリの生成、関連ドキュメントの検索、LLMによる回答の生成という一連のプロセスを経て回答を提示します。
また、PrivateGPTやGPT4Allのような、ローカルで動作するオープンソースのLLMを活用することも可能です。LangChainのOllamaインテグレーションを使えば、ローカルのOSSモデルに対して同様のCode understandingを行うことができます。
⑨合成データ生成
合成データとは、実際のイベントから収集されたデータではなく、人工的に生成されたデータのことを指します。プライバシーを損なったり、現実世界の制限に遭遇したりすることなく、本物のデータをシミュレートするために使用されます。
Langchain を使用して合成データを生成するプロセスは、まずデータモデルを定義することから始まります。これは、生成されるデータの構造やスキーマを決定するものです。次に、生成するデータの種類を示すために、いくつかのサンプルデータを提供します。これらのサンプルは、望ましいデータの代表的なものであり、ジェネレーターはそれらを使用して類似したデータを作成します。
次のステップは、プロンプトテンプレートを作成することです。このテンプレートは、基礎となる言語モデルに、目的の形式で合成データを生成する方法を指示するのに役立ちます。スキーマとプロンプトの準備ができたら、データジェネレーターを作成します。このオブジェクトは、合成データを取得するために基礎となる言語モデルとどのように通信するかを知っています。
最後に、ジェネレーターに必要な数の合成レコードを生成するように要求します。結果は、定義したデータモデルに従った形式で返されます。
Langchain は、プライバシーの懸念やデータの可用性の問題により実際の患者データを使用したくない場合に、アルゴリズムの開発やテストに特に役立ちます。合成データを使用することで、現実世界のデータ収集よりもコスト効率が良く、特定のシナリオを柔軟に作成でき、厳しいデータ保護法をナビゲートするのにも役立ちます。ただし、合成データは現実世界の複雑さを常に捉えられるとは限らないため、注意して使用する必要があります。
⑩タグ付け
文書に対して感情、言語、スタイル、トピック、政治的傾向などのラベルを付与することを指します。タグ付けを行うには、モデルがどのように文書にタグを付けるべきかを指定する関数と、文書をどのようにタグ付けしたいかを定義するスキーマの2つのコンポーネントが必要です。
OpenAIのツール呼び出しを使用したタグ付けの簡単な例では、Pydanticモデルを使用してスキーマ内のプロパティとその期待される型を指定します。そして、ChatPromptTemplateとChatOpenAIを使用してタグ付けチェーンを構築します。これにより、文書を入力として受け取り、指定されたスキーマに従ってタグ付けされた結果を出力することができます。
さらに、スキーマ定義を注意深く行うことで、モデルの出力をより細かく制御することができます。具体的には、各プロパティの可能な値、モデルがプロパティを正しく理解するための説明、返される必要のあるプロパティを定義できます。これにより、期待通りの制限された回答を得ることができます。
また、LangChainのメタデータタガードキュメントトランスフォーマーを使用して、LangChainドキュメントからメタデータを抽出することもできます。これは、タグ付けチェーンと同じ基本的な機能をカバーしていますが、LangChainドキュメントに適用されます。

⑪要約
要約を行う際には、LLMのコンテキストウィンドウにどのように文書を渡すかが重要な問題となります。Langchainでは、主に2つのアプローチがあります。
1つ目は、"Stuff"と呼ばれる手法で、シンプルに全ての文書を1つのプロンプトにまとめてLLMに渡す方法です。この方法は最もシンプルで、16kトークンのOpenAI gpt-3.5-turbo-1106や100kトークンのAnthropic Claude-2など、大きなコンテキストウィンドウを持つモデルに適しています。
2つ目は、"Map-reduce"と呼ばれる手法で、まず各文書を個別に要約する"Map"ステップを行い、その後、それらの要約を最終的な要約にまとめる"Reduce"ステップを行います。この方法では、まずLLMChainを使って各文書を個別に要約し、次にReduceDocumentsChainを使ってそれらの要約を1つの最終的な要約にまとめます。
また、"Refine"と呼ばれる3つ目の手法もあります。これは、Map-reduceに似ていますが、入力文書をループ処理し、反復的に回答を更新することで要約を構築します。
Langchainでは、これらの手法を簡単に使うことができ、プロンプトやLLMのカスタマイズも可能です。また、長い文書をチャンクに分割し、それぞれを要約した後に最終的な要約を生成するAnalyzeDocumentsChainも提供されています。
⑫Webスクレイピング
Webからコンテンツを収集するためのいくつかのコンポーネントを提供しています。まず、GoogleSearchAPIWrapperなどを使ってクエリからURLを取得する検索機能があります。次に、AsyncHtmlLoaderやAsyncChromiumLoaderなどを使ってURLからHTMLを読み込む機能があります。最後に、HTML2TextやBeautiful Soupなどを使ってHTMLを整形されたテキストに変換する機能があります。
LangChainでは、AsyncHtmlLoaderを使って簡単で軽量なスクレイピングを行うことができます。これはaiohttpライブラリを使って非同期のHTTPリクエストを行います。より複雑なWeb操作やJavaScriptのレンダリングが必要な場合は、AsyncChromiumLoaderを使ってPlaywrightでChromiumインスタンスを起動することができます。
HTMLコンテンツをプレーンテキストに変換するには、HTML2Textが適しています。これはHTMLを人間が読みやすいテキストに変換します。一方、Beautiful Soupは、特定のタグの抽出、削除、コンテンツのクリーニングなど、HTMLコンテンツをより細かく制御することができます。
LangChainでは、OpenAI関数を使った抽出チェーンを使うことで、Webサイトのレイアウトや内容の変化に対応するスクレイピングスクリプトを常に変更する必要がなくなります。スキーマを定義することで、必要なデータを指定し、LLMがそれに従ってコンテンツを抽出します。
さらに、WebResearchRetrieverを使って、検索されたコンテンツを使って特定の質問に答えるプロセスを自動化することができます。これにより、LLMを使って関連する検索クエリを生成し、各クエリの検索を実行し、選択したすべてのリンクから情報を読み込み、それらのドキュメントをベクトルストアにインデックス化し、元の検索クエリに最も関連するドキュメントを見つけることができます。

まとめ
最後までご覧いただきありがとうございました。

