このシリーズでは、Pythonの様々な活用の方法を紹介しています。
今回は「Tesseract OCR」と「PyOCR」を使って、画像からテキストを読み取る方法を紹介します。
実際にOCR技術を使ってみましょう。
Google colabを使用して簡単に実装することができますので、ぜひ最後までご覧ください。
今回の目標
・PyOCRとは
・Tesseract+PyOCRの導入
・OCRの実装
・文字の位置を検出
PyOCRとは
OCRとは
OCRは、Optical Character Reader(またはRecognition)の略で、光学的文字認識と呼ばれています。
画像データからテキスト部分を認識し、文字データに変換する技術のことです。
例えば、スキャナーで読み込んだ書類などの文字情報や写真に写っている文字を認識して、テキストデータとして出力することができます。
この技術をうまく活用することで、以下のようなメリットがあります。
| ①データ入力の簡略化 |
| 紙データを入力することは非常に手間がかかります。OCR技術を活用することで、スキャンしたデータをテキスト化することが可能となる、これらの作業を短時間かつ自動的に行うことができるようになります。 |
| ②データの検索性向上 |
| 書類の中から必要な情報を探し出すのは非常に大変な作業です。書類をスキャンしたデータにOCR技術を活用することで、欲しい情報を簡単に検索できるようになります。 |
| ③データの分析 |
| テキストデータを自然言語処理などの技術と組み合わせることで、文書内の文章を分析するとも可能になります。 |
Tesseractとは
GoogleとHPが開発したオープンソースのOCRエンジンです。
Unicode(UTF-8)をサポートしており、日本語を含めた100以上の言語を認識することができます。
入力の画像はPNGやJPEGなどをサポートしています。
詳細は公式実装からご確認ください。
Tesseract : https://github.com/tesseract-ocr/tesseract
PyOCRとは
Python用のOCRツールラッパーで、さまざまなOCRツールを使用できます。
Tesseractもサポートしています。
詳細は公式実装からご確認ください。
Tesseract+PyOCRの導入
ここからはGoogle colab環境で進めていきます。
なお、今回紹介するコードはこちらからも確認することができます。
![]()
まずは、Googleドライブをマウントします。
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive次に「Tesseract」と「PyOCR」をインストールします。
# 必要なライブラリをインストールする
!apt install tesseract-ocr libtesseract-dev tesseract-ocr-jpn
!pip install pyocrインストールが完了しました。
次に日本が使えるかどうかを確認しておきましょう。
# 日本語が使えることを確認する
!tesseract --list-langs実行すると、以下のように出力されます。
List of available languages (3):
eng
osd
jpn「jpn」と表示されており、日本語のOCRが使用できることがわかりました。
OCRの実装
準備
ここからはOCRを実装していきます。
まずはPyOCRが使用できることを確認します。
from PIL import Image
import pyocr
import cv2
from google.colab.patches import cv2_imshow
# pyocrが使えることを確認する
tools = pyocr.get_available_tools()
tool = tools[0]
print(tool.get_name())
# Tesseract (sh)と出力されればOK「Tesseract (sh)」と出力されれば、問題なく使用できます。
画像を用意する
次に実際に文字を読み取る画像を準備して、Googleドライブにアップしましょう。
今回はこちらの動画の中から切り取った画像を使用します。
使用する画像を表示してみます。
img1 = Image.open('input_ocr.png')
img1
画像が表示されました。
この画像に対してOCRを行い、文字を読み取ります。
画像から文字を読み取る
文字を読み取り、表示させてみます。
txt1 = tool.image_to_string(
img1,
lang='jpn+eng',
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
print(txt1)実行すると、以下のような結果が出力されました。
画像系の機械学習の分野の1つである「超解像」について初心者向けに紹介します。
今回はReaLESRGANの公式チュートリアルに治って実装する方法を紹介します。
実際に解像度の低い画像を高解像度化してみましょう。
Google colabを使用して簡単に実装することができますので、ぜひ最後までご覧ください。
今回の目標
・超解像の概要を学ぶ
・ReaL-ESRGANの実装方法を学ぶ
・オリジナル画像を高解像度化してみるPyOCRを使用して、簡単に画像から文字を読み取ることができました。
結果をテキストファイルとして出力する
最後に結果をテキストファイルとして出力してみましょう。
# 結果をテキストファイルとして出力
file_path = "input_ocr.txt"
with open(file_path, 'w') as f:
f.writelines(txt1)先ほど結果として得られた文字列を「input_ocr.txt」というテキストファイルに出力することができました。
文字の位置を検出
文字の位置を枠線で囲う
PyOCRを使うと、文字の位置も出力することができます。
results = tool.image_to_string(
img1,
lang='jpn+eng',
builder=pyocr.builders.WordBoxBuilder(tesseract_layout=6)
)
draw_rectangle = cv2.imread('input_ocr.png')
for box in results:
cv2.rectangle(draw_rectangle, box.position[0], box.position[1], (255, 0, 0), 1)
cv2.imwrite('draw_rectangle.png', draw_rectangle)
draw_rectangle = Image.open('draw_rectangle.png')
draw_rectangle実行すると、以下のような画像を表示することができます。
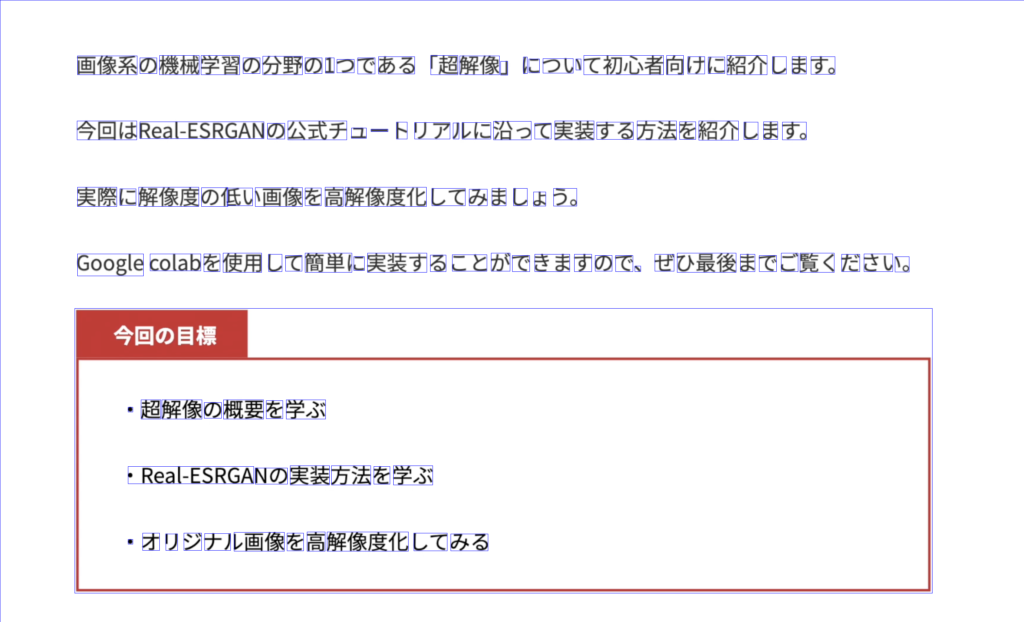
OCRにより検出した文字を青枠で囲い表示していることがわかります。
文字の位置の座標を出力する
文字の位置の座標データを出力することもできます。
draw_rectangle = cv2.imread('input_ocr.png')
for box in results:
print(box)実行すると、以下のように出力されす。
画像 197 142 349 190
系 0 0 2609 1586
の 356 147 399 187
機械 406 141 507 190
学習 512 141 610 190
の 619 147 662 187
分 669 143 770 190
野 777 147 820 187
の 829 147 851 186
1 0 0 2609 1586
つ 858 151 902 185
で 911 147 955 188
ある 964 144 1056 188
〜〜以下省略〜〜それぞれの文字が画像の中のどの位置にあるのかを把握することが可能となります。
まとめ
最後までご覧いただきありがとうございました。
今回は「Tesseract OCR」と「PyOCR」を使って、画像からテキストを読み取る方法を紹介しました。
OCRの技術は日常の様々な場面で多く活用されていますが、Pythonで簡単に実装できることで、活用の場面もさらに広がりそうですね。
このシリーズでは、Pythonの様々な活用の方法を紹介しています。
ぜひ他の記事も合わせてご覧ください。