今回の記事では2024年2月に登場した最先端の性能を誇るオブジェクト検出モデルであるYOLOv9の実装を紹介します。
Google Colabを使用して簡単に実装できますので、ぜひ最後までご覧ください。
今回の内容
・YOLOv9とは
・YOLOv9の実装
YOLOv9とは
YOLOv9は、2024年2月に登場した最先端の性能を誇るオブジェクト検出モデルです。ディープラーニングネットワークの設計と最適化において重要な2つの概念、すなわち「情報損失」と「プログラマブル勾配情報(PGI)」に焦点を当てています。YOLOv9-Eモデルでは55.6%のAP を達成しています。
- 情報損失と情報ボトルネック: ディープラーニングネットワークは、入力データを複数の層を通じて処理することでタスク(例えば、画像認識や言語翻訳)を実行します。各層を通過する際に、入力データの情報が失われることがあります。特に、情報ボトルネックは、重要な情報が失われ、ネットワークの性能が低下する可能性がある状況を指します。この問題に対処するため、研究者たちは情報の損失を最小限に抑える方法を模索しています。
- プログラマブル勾配情報(PGI): 論文では、この問題に対する一つの解決策としてPGIを提案しています。PGIは、ネットワークが目標タスクをより効果的に学習できるように、信頼できる勾配情報を提供する技術です。勾配は、ネットワークの学習過程において、どのように重みを更新すべきかを示す指標です。PGIを使用すると、ネットワークはより関連性の高い情報を保持しながら、必要な調整を行うことができます。
- Generalized Efficient Layer Aggregation Network(GELAN): さらに、論文では新しい軽量ネットワークアーキテクチャであるGELANを紹介しています。GELANは、従来の畳み込み演算を用いて、より効率的にパラメータを利用する方法を提供します。これは、ディープラーニングモデルの効率と性能を向上させることを目指しています。GELANの設計は、深度方向の畳み込みに基づく最新の技術よりも優れた性能を提供することを目標としています。
この論文はディープラーニングネットワークが直面する情報損失の問題に対処し、新しい技術とアーキテクチャ(PGIとGELAN)を提案して、これらの問題を解決する方法を探求しています。これにより、ネットワークは複数の目標をより効率的に達成できるようになり、全体的な性能が向上します。
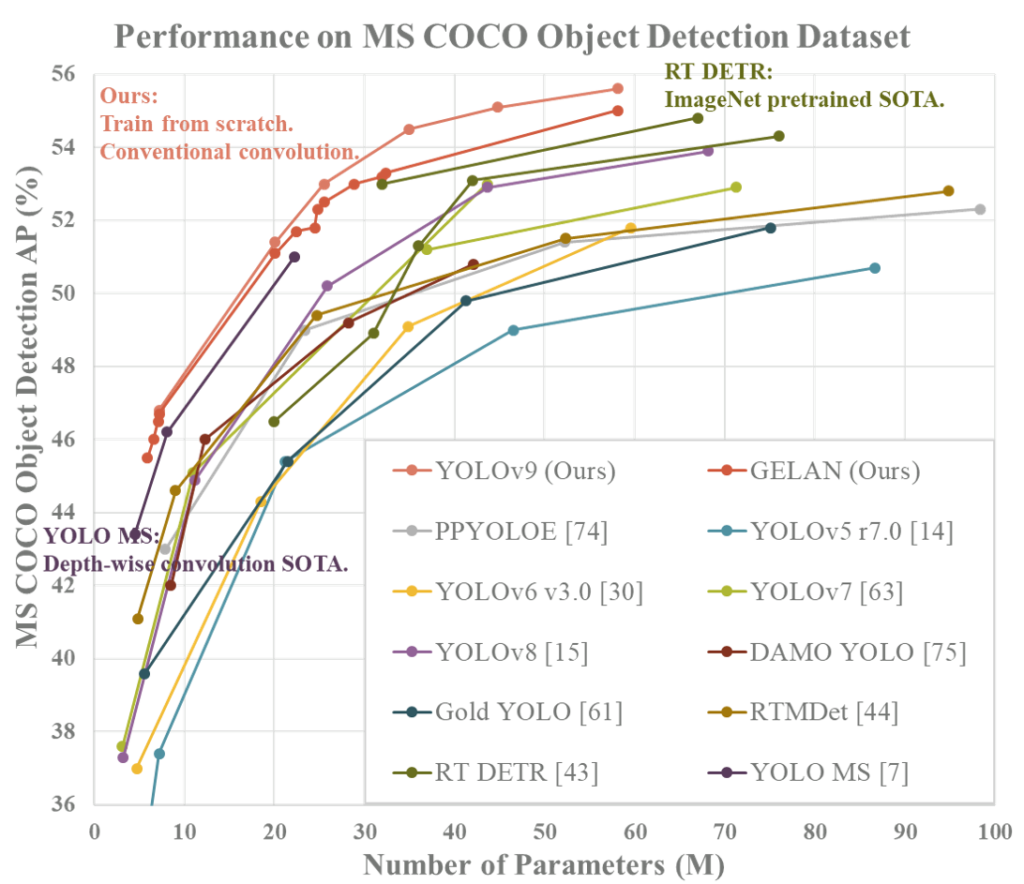
詳細は以下のリンクからご確認ください。
YOLOv9の実装(推論)
準備
ここからはGoogle colabを使用して、YOLOv9の学習済モデルによる推論を実装していきます。
まずはGPUを使用できるように設定をします。
「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をT4 GPUに変更
Googleドライブをマウントします。
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive公式リポジトリをクローンします。
!git clone https://github.com/WongKinYiu/yolov9
%cd yolov9必要なライブラリをインストールします。
!pip install -r requirements.txt -q
!pip install supervision -q学習済モデルをダウンロードします。
!mkdir -p weights
!wget -P weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c.pt
!wget -P weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-e.pt推論
今回はこちらの画像を使用して推論してみます。
まずは画像をダウンロードします。
!wget "https://user0514.cdnw.net/shared/img/thumb/susi1123PAR50424312_TP_V4.jpg?&download=1" -O "sample.jpg"必要な関数を定義します。
import torch
import cv2
import numpy as np
from models.common import DetectMultiBackend
from utils.general import non_max_suppression, scale_boxes
from utils.torch_utils import select_device, smart_inference_mode
from utils.augmentations import letterbox
import PIL.Image
import supervision as sv
%matplotlib inline
def predict(image_path, weights, imgsz, conf_thres, iou_thres, device, data):
device = select_device(device)
model = DetectMultiBackend(weights, device=device, fp16=False, data=data)
stride, names, pt = model.stride, model.names, model.pt
image = PIL.Image.open(image_path)
img0 = np.array(image)
assert img0 is not None, f'Image Not Found {image_path}'
img = letterbox(img0, imgsz, stride=stride, auto=True)[0]
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device).float()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
pred = model(img, augment=False, visualize=False)
pred = non_max_suppression(pred[0][0], conf_thres, iou_thres, classes=None, max_det=1000)
bounding_box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator(text_position=sv.Position.TOP_LEFT)
for i, det in enumerate(pred):
if len(det):
det[:, :4] = scale_boxes(img.shape[2:], det[:, :4], img0.shape).round()
for *xyxy, conf, cls in reversed(det):
label_name = names[int(cls)]
label = f'{label_name} {conf:.2f}'
detections = sv.Detections(
xyxy=torch.stack(xyxy).cpu().numpy().reshape(1, -1),
class_id=np.array([int(cls)]),
confidence=np.array([float(conf)])
)
labels = [
f"{names[int(class_id)]} {confidence:0.2f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
]
img0 = bounding_box_annotator.annotate(img0, detections)
img0 = label_annotator.annotate(img0, detections, labels)
return img0[:, :, ::-1]推論を実行します。
img = predict(image_path='sample.jpg', weights='weights/yolov9-e.pt', imgsz=640, conf_thres=0.5, iou_thres=0.7, device='0', data='data.yaml')
sv.plot_image(img)実行結果:
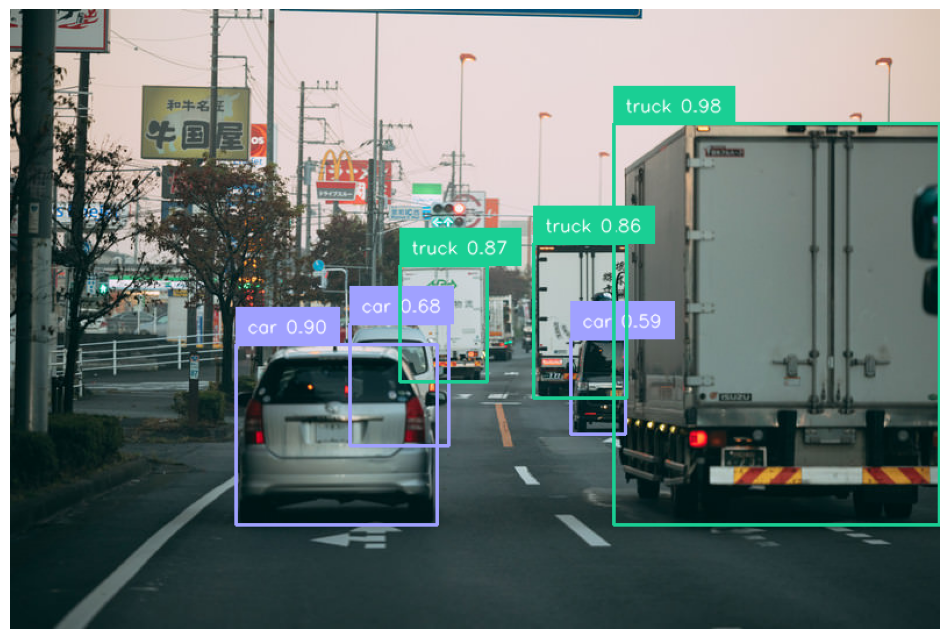
推論の設定(引数)
| 引数名 | 説明 |
|---|---|
image_path | 物体検出を行いたい画像のファイルパス。'sample.jpg'は検出を行う画像のファイル名。 |
weights | 物体検出モデルの重みファイルのパス。 |
imgsz | モデルが処理する画像のサイズ。640は、画像を640x640ピクセルにリサイズしてからモデルに入力することを意味する。 |
conf_thres | 物体検出時に使用される信頼度の閾値。0.5は、モデルが物体と判断する最低限の信頼度を表し、この閾値以上の信頼度を持つ検出結果のみを保持。 |
iou_thres | 非最大抑制(NMS)に使用されるIoUの閾値。0.7は、異なる検出ボックスが重複している度合いが0.7以上であれば、最も信頼度が高いボックスを除き他を除外。 |
device | 計算を実行するデバイス。'0'は、IDが0のGPUデバイス上で計算を行うことを意味し、通常GPUデバイスのIDを指す。 |
data | データセットの構成やクラスの情報を含むYAMLファイルのパス。'data.yaml'は、物体検出タスクに必要な追加情報(検出するクラスの種類やラベル情報など)が記述されたファイル。 |
動画の推論
出力結果(参考):
まとめ
最後までご覧いただきありがとうございました。

