・本記事はJDLA Generative AI Testの学習メモです。
・本記事は試験内容と一切関係ありません。また、試験の合格を保証するものでもありません。ご使用は自己責任にてお願いします。
・本記事の情報は投稿日時点の情報となります。技術の進歩がとても速い分野となりますので、最新の情報もこちらからご確認ください。
- 1. JDLA Generative AI Testとは
- 2. 生成モデルに共通する技術的な特徴
- 2.1. 確率モデル
- 2.2. ハルシネーション
- 3. 大規模言語モデルの基本構造
- 3.1. 基盤モデル
- 3.2. 言語モデル
- 3.3. 大規模言語モデル (LLM)
- 3.4. トランスフォーマー (Transformer)
- 3.5. アテンション (Attention)
- 3.6. GPT-3
- 4. 大規模言語モデルにおけるモデルの学習方法
- 4.1. 教師あり学習
- 4.2. 自己教師あり学習
- 4.3. 事前学習
- 4.4. ファインチューニング
- 5. 大規模言語モデルのアラインメント
- 5.1. アラインメント (Alignment)
- 5.2. 人間のフィードバックによる強化学習 (RLHF)
- 5.3. インストラクション・チューニング (Instruction Tuning)
- 6. 大規模言語モデルにおける生成の仕組み
- 6.1. コンテキスト内学習 (In-Context Learning)
- 6.2. Zero-ShotとFew-Shot
- 6.3. サンプリング手法
- 7. 生成モデルの技術動向
- 7.1. 条件付き生成
- 7.2. 拡散モデル (Diffusion Model)
- 8. 大規模言語モデルのオープン化の動向と原因
- 8.1. オープンコミュニティ
- 8.2. オープン大規模言語モデル
- 8.3. オープンデータセット
- 8.4. オープンソース
- 9. 大規模言語モデルの性能を決める要素の動向と原因
- 9.1. スケーリング則 (Scaling Laws)
- 9.2. データセットのサイズ
- 9.3. データセットの質
- 9.4. モデルのパラメーター数
- 9.5. 計算資源の効率化
- 9.6. GPU
- 10. 大規模言語モデルのマルチモーダル化の動向と原因
- 10.1. マルチモーダル
- 11. 大規模言語モデルの外部ツール・リソースの利用の動向と原因
- 11.1. 学習データの時間的カットオフ
- 11.2. 大規模言語モデルの知識
- 11.3. 大規模言語モデルの不得意タスク
- 12. 生成AIには何ができるのか
- 12.1. ケイパビリティ
- 13. 生成AIをどのように使うのか
- 13.1. 生成AIの活用事例
- 14. 生成AIの性能を拡張する使い方
- 14.1. プロンプトエンジニアリング
- 15. 生成AIの新たな活用方法を生み出すためのアプローチ
- 15.1. ハッカソン
- 15.2. 自主的なユースケース開発
- 15.3. インターネット・書籍、活用の探索
- 15.4. 活用の探索
- 16. 生成AIの活用を制限する要因
- 16.1. 生成AIの学習データ
- 16.2. 生成AIの性能評価
- 16.3. 生成AIの言語能力
- 17. 業界に特化した生成AIの活用方法
- 17.1. ChatGPT・Bard
- 17.2. 広告クリエイティブへの応用
- 17.3. ドメイン固有
- 18. 生成AIが、技術面・倫理面・法令面・社会面などで多様なリスクを孕むこと
- 18.1. 正確性
- 18.2. ハルシネーション (Hallucination)
- 18.3. セキュリティ
- 18.4. 公平性
- 18.5. プライバシー
- 18.6. 透明性
- 19. 生成AIの入力(データ)と出力(生成物)について注意すべき事項
- 19.1. 著作権
- 19.2. 個人情報
- 19.3. 機密情報
- 19.4. 商用利用
- 19.5. 利用規約
- 20. 生成AIについて、現時点では認識されていない新たなリスクの出現とそれに伴う規制化の可能性
- 20.1. 新たなリスク
- 20.2. 規制化
- 20.3. 情報収集
- 21. 生成AIの活用に伴うリスクを自主的に低減するための方法
- 21.1. 自主対策
- 22. まとめ
JDLA Generative AI Testとは
発展目覚ましい生成AIの分野において、基礎知識を有し、適切な活用を行うための能力や知識を有しているかをミニテスト形式で検定する。(公式ページより引用)
Generative AI Test(生成AIの理解度やリテラシーを図るミニテスト) - 一般社団法人日本ディープラーニング協会【公式】
Generative AI Testとは、累計受験者13万人を突破したG検定を運営する日本ディープラーニング協会(JDLA)が実施する、生成AI(Generative AI Test)の活⽤リテラシー習得…

生成モデルに共通する技術的な特徴
確率モデル
大規模言語モデル (Large Language Models、LLM) は、人間の言語使用のパターンを学習するための機械学習モデルです。その中心となる原理は、確率的な観点からテキストデータを解釈することにあります。確率モデルの役割とその動作の詳細を理解することで、LLMがどのようにして言語を「理解」し、「生成」するかを深く把握することができます。
大規模言語モデルは、基本的には単語やフレーズの出現のパターンを学習し、それに基づいて新しいテキストを生成します。これは確率モデルを通じて行われます。確率モデルはデータ内のパターンを捉え、それを利用して未知の事象に対する予測を行うためのツールです。この場合、事象はテキスト中の次の単語やフレーズの出現で、その予測は既存のテキストデータに基づいて行われます。
LLMの一つの重要なタイプは、トランスフォーマーベースのモデルであり、その一例がOpenAIのGPT-3やGPT-4です。これらのモデルは「自己回帰」性質を持っています。これは、あるシーケンスの次の要素を予測するために、それまでのシーケンスを利用するという特性です。自己回帰モデルは、過去のデータを利用して未来を予測します。
例えば、「彼はコーヒーを飲むのが__」というフレーズが与えられたとき、自己回帰モデルは次の単語を予測します。確率的な観点から見ると、モデルは「好き」、「嫌い」、「慣れている」などの可能な単語すべてに確率を割り当て、最も確率の高い単語を出力します。
その出力は、モデルが訓練中に見た大量のテキストデータ(インターネットの書籍、ウェブサイト、記事など)から学習したパターンに基づいています。このような学習プロセスによって、LLMは文脈、一般的な知識、さまざまな話題についての情報など、人間の言語の多面的な特性を捉えることができます。
確率モデルの使用は、LLMが不確実性を取り扱い、新しい情報を生成するための基本的な方法です。それにより、これらのモデルは人間の言語を驚くほど正確に模倣し、ある程度のコンテキストに基づいて意味のある予測を提供することが可能になります。
ハルシネーション
ハルシネーション(AIの幻覚)とは、AIがその訓練データに基づいて正当化できない情報を信じ込んだ結果、生成AIが不正確や不適切な回答を生成する現象を指します。これは、例えば、AIが自身の訓練データに基づいて正当化できない数値(テスラの収益が136億ドルなど)を伝えるといった形で表れます。
この現象は、人間の心理学におけるハルシネーション現象に似ているとされ、それにちなんで"ハルシネーション"と名付けられています。ただし、人間のハルシネーションが主に感覚的な偽の知覚に関連しているのに対し、AIのハルシネーションは不正確や不適切な回答や信念と関連しています。
AIのハルシネーションは、2022年頃から大規模な言語モデル(Large Language Models、LLMs)の登場と共に注目を集めるようになりました。ユーザーからは、これらのAIが信憑性のあるように見える虚偽の情報を生成する傾向にあるという不満が出ています。
ハルシネーションの主な原因には、データからのハルシネーションと訓練からのハルシネーションの2つのタイプがあります。
- データからのハルシネーション: これは訓練データに偏りや矛盾が存在する場合に起こります。大規模な訓練データセットでは、データ間での情報の不一致や誤解がよく発生します。
- 訓練からのハルシネーション: データセット自体は問題がない場合でも、AIの訓練方法によりハルシネーションが生じることがあります。モデルの誤ったデコーディング、モデルが以前に生成したシーケンスに対するバイアス、モデルがそのパラメータに知識をエンコードする方法から生じるバイアスなどが、ハルシネーションの原因となり得ます。
大規模言語モデルの基本構造
基盤モデル
基盤モデルは、ラベルなしの大量データを使って事前学習し、その後、幅広い下流タスクに適応できるようにファインチューニングする、という2段階の訓練工程を踏んだ、1つの機械学習モデルのことを指します。基盤モデルの一つの特徴は、マルチタスクに適応できることです。この用語は2021年にスタンフォード大学のHAI(人間中心のAI研究所)によって広められ、2022年中に特にAI関連の研究者や技術者の間で徐々に注目されるようになりました。OpenAIのGPT-3や、同じくOpenAIが発表した「Stable Diffusion」にも使われているCLIPなどがその代表例です。
言語モデル
言語モデルは、単語列に対する確率分布を表現するもので、ある単語列全体に対する確率を与えます。この確率分布は、1つまたは複数の言語のテキストコーパスを使用して、言語モデルを訓練することによって得られます。しかし、言語は無限に有効な文を表現できるため、訓練データでは遭遇しないような言語的に有効な単語列にゼロでない確率を割り当てることが課題となります。この問題を克服するために、マルコフ仮定や、回帰型ニューラルネットワークあるいはトランスフォーマー(transformer)などのニューラルアーキテクチャなど、さまざまなモデリング方法が利用されます。
大規模言語モデル (LLM)
大規模言語モデル(LLM:Large Language Models)は自然言語処理(NLP)や自然言語生成(NLG)において、ディープラーニングを基盤とするモデルです。これらのモデルは、言語の複雑な特性やその相互関連性を学習するために、大量のデータを基に訓練されます。その後、これらのモデルは特定のタスクに適応させるために、さまざまな技術を活用します。
大規模言語モデルの基本は、Googleのエンジニアにより2017年に発表された「Attention is All You Need」の論文で初めて紹介されたTransformerベースのニューラルネットワークです。これらのモデルの主な目的は、次に来る可能性のあるテキストを予測することです。モデルの性能と洗練度は、パラメータの数、すなわち、出力を生成する際に考慮する要素の数によって判断されます。
大規模言語モデルは、オープンソースの形で提供され、オンプレミスあるいはプライベートクラウドでのデプロイが可能です。これにより、ビジネスの採用が促進され、サイバーセキュリティも強化されています。これらのモデルは感情分析、カスタマーサービス、コンテンツ作成、詐欺検出、予測と分類など、多くのプロセスを自動化するために使用することができます。これらのタスクの自動化により、手作業やそれに伴うコストを削減することが可能です。
トランスフォーマー (Transformer)
トランスフォーマーモデルは、「Attention is All You Need」(ヴァシュワニ他、2017)という論文で初めて紹介された深層学習アーキテクチャです。その特徴的な要素は、全ての処理がアテンションメカニズム(具体的にはセルフアテンションまたはマルチヘッドアテンション)を利用している点です。この設計により、トランスフォーマーモデルは文脈を捉える上で非常に有効であり、長い範囲の依存関係を捉える能力を持っています。
トランスフォーマーは、エンコーダとデコーダの2つの主要部分から成り立っています。エンコーダは入力データ(たとえば、テキストの系列)を固定長のベクトル(通常は数千次元)に変換します。このベクトルは、入力データの全ての情報をエンコードした「文脈ベクトル」と呼ばれます。その後、デコーダはこの文脈ベクトルを元にして新しいデータ(たとえば、翻訳されたテキスト)を生成します。
トランスフォーマーモデルの特徴的な要素の1つであるセルフアテンションメカニズムは、入力シーケンス内のすべての位置からすべての位置への依存関係を計算します。これは、各単語が文全体のコンテキストに基づいて解釈されることを意味します。この機能は、文脈によって意味が変わる単語の理解に特に有用であり、結果としてより高度な言語理解を可能にします。
大規模言語モデル(LLM)の訓練では、トランスフォーマーモデルが頻繁に使用されます。LLMは大量のテキストデータ(インターネット上の記事、書籍など)から言語のパターンを学習し、人間のような文章を生成する能力を獲得します。この学習プロセスは「事前学習」または「ファインチューニング」の形を取ることがあり、特定のタスクに対するモデルのパフォーマンスを改善します。
また、トランスフォーマーモデルはその柔軟性と効率性から、翻訳、要約、質問応答など、多くの自然言語処理(NLP)タスクで主要なアーキテクチャとして使用されています。特に、GPT(Generative Pre-trained Transformer)シリーズやBERT(Bidirectional Encoder Representations from Transformers)など、現在の最先端のNLPモデルの多くはトランスフォーマーベースです。
アテンション (Attention)
アテンションとは、人間の認知プロセスを模倣したアルゴリズムの一種で、特に自然言語処理(NLP)の分野で注目を集めています。このアルゴリズムは、情報の関連性に応じて情報の重要性を「注視」(重み付け)するという原理に基づいています。
この原理が最初に導入されたのは、トランスフォーマーという名のニューラルネットワークで、特に言語モデルで広く利用されています。ここでは、トランスフォーマーのアテンションのメカニズムについて詳細に説明します。
トランスフォーマーは、いわゆる「自己注意」または「セルフアテンション」メカニズムを利用します。このメカニズムは、文章の各単語(またはトークン)が他のすべての単語とどの程度関連しているかを計算します。この関連性は、各単語のコンテキストをより豊かに表現し、モデルが例えば代名詞の指す対象を理解するのに役立ちます。
具体的なプロセスは次のとおりです:
- クエリ、キー、バリューへの分解:まず、各単語のエンベッディング(多次元空間における単語の位置または表現)は、クエリ(Q)、キー(K)、バリュー(V)の3つの異なるベクトルに分解されます。これらのベクトルは、それぞれ異なる目的を持ちます。クエリは関心のある単語を表し、キーは他の単語がクエリにどの程度関連しているかを判定する役割を持ち、バリューは最終的な注目結果を計算するための重要な情報を提供します。
- スコアの計算:次に、各単語のクエリベクトルは他のすべての単語のキーベクトルと比較(通常はドット積)され、一連のスコアが生成されます。これらのスコアは、各単語が他の単語とどの程度関連しているかを示します。
- スコアの正規化:次に、これらのスコアはソフトマックス関数を通じて正規化されます。これにより、すべてのスコアは0から1の間の値となり、合計は1になります。これは、各単語が他の単語にどの程度「注目」すべきかを示す確率分布を生成します。
- 値の加重平均の計算:最後に、正規化されたスコアは各単語のバリューベクトルに掛けられ、加重平均が計算されます。これがアテンションの結果です。
トランスフォーマーのアーキテクチャでは、このプロセスは複数の「アテンション・ヘッド」を通じて並行して行われ、それぞれが異なる特徴に注目します。そして、これらのヘッドからの出力は組み合わされて、次のネットワーク層に送られます。
このアテンションメカニズムにより、トランスフォーマーは文脈により敏感な言語モデルを構築することが可能になります。具体的には、単語の間の長距離の依存関係や、文の構造など、広範な情報を捉える能力が向上します。
GPT-3
- Transformer Model (2017): "Attention is All You Need"という論文で提案されたTransformerは、自然言語処理(NLP)の分野に革新をもたらしました。これは、RNNやCNNに代わる新しいアーキテクチャで、自己注意(self-attention)またはTransformerと呼ばれる新しいメカニズムを導入しました。このモデルは、入力データのすべての単語が互いに直接関連していると仮定するため、パフォーマンスと効率性の向上が期待されました。
- GPT (Generative Pretrained Transformer, 2018): OpenAIはGPTをリリースし、NLPの新しいアプローチを紹介しました。GPTはTransformerのデコーダ部分を使用し、大規模なテキストデータセットから事前学習することで、様々なNLPタスクにおけるfine-tuningを可能にしました。GPT-1の学習方法は二段階に分かれています。まず、大量のインターネットテキストデータで事前学習を行い、その後で特定のタスクに対して微調整(fine-tuning)を行います。事前学習では、モデルは文章の一部を予測するタスクを解くことで、文法や語彙、一般的な知識などを学びます。このモデルは117Mのパラメータを有しています。
- BERT (Bidirectional Encoder Representations from Transformers, 2018): Googleは、Transformerのエンコーダ部分を使用する新しいモデル、BERTをリリースしました。BERTは、文脈を考慮した双方向の理解により、自然言語理解タスクの新しい基準を設定しました。
- GPT-2 (2019): GPTの次のバージョンであるGPT-2は大幅にパラメータ数が増え、1.5Bまでになりました。これにより、より複雑な文脈を理解し、より自然な文章を生成する能力が向上しました。学習方法は基本的にはGPT-1と同じで、大量のインターネットテキストで事前学習を行い、その後で微調整を行います。その結果、モデルの出力は人間が書いたものと区別するのが難しくなりました。しかし、その能力が悪用される懸念から、OpenAIは当初、GPT-2のフルモデルを公開しないという決定をしました。
- GPT-3 (2020): OpenAIは、1750億のパラメータを持つGPT-3をリリースしました。その規模と力は、その前のモデルを大きく上回り、GPT-3は驚異的な自然言語生成能力を示しました。事前学習ではコンテキスト内学習(与えられたプロンプト(テキスト)を入力とし、そのプロンプトからタスクを理解し、適切な出力を生成することを学習)という方法で学習します。また、GPT-3はほとんどのタスクにおいてファインチューニングを必要とせず、zero-shotやfew-shot learningによる高い性能を示しました。GPT-3の事前学習はメタ学習を行なっているとも解釈することができる。
- Instruct-GPT(2022): 強化学習と人間のフィードバックを用いて訓練された大規模言語モデルで、GPT-3をベースにしています。このモデルは対話専用ではありませんが、会話形式で使用可能で、ユーザーの指示(プロンプト)に基づいて応答を生成します。安全性、信頼性、ユーザーの意図との一致に優れ、GPT-3よりも高品質の出力を提供します。
大規模言語モデルにおけるモデルの学習方法
教師あり学習
この方法では、ラベル付きの学習データセットを使用します。つまり、各入力データに対して正しい出力(ラベル)があらかじめ与えられています。大規模言語モデルのコンテキストでは、教師あり学習は、各単語(またはフレーズ)が与えられた文脈で次に来るべき単語を予測するタスクとして考えることができます。例えば、「彼は自転車に乗って_」という文章が与えられた場合、次に来るべき単語として「学校へ」や「公園へ」などの答えが正解として事前に与えられ、モデルはこの情報を基に学習を行います。
自己教師あり学習
自己教師あり学習は教師あり学習の一種ですが、ラベルを人間が付けるのではなく、データ自体からラベルを生成します。これは大量の未ラベルデータからパターンを学習するための強力な方法です。大規模言語モデルでは、典型的にはマスク言語モデル(Masked Language Model, MLM)と呼ばれるアプローチが使われます。このアプローチでは、文章中の一部の単語(または単語)をランダムにマスク(隠す)し、そのマスクされた単語を元のコンテキストから予測するようにモデルを学習します。例えば、「彼は自転車に乗って学校へ行った」という文章が与えられた場合、この中の一部の単語、例えば「学校」事前学習は、モデルが基本的な言語理解を獲得するための初期段階です。このフェーズでは、モデルは大規模なテキストコーパス(ウェブページ、書籍、記事などから成る大量のテキスト)を用いて学習します。学習の目標は、与えられた単語やフレーズの文脈から次の単語を予測することです(教師あり学習)あるいは文中のマスクされた単語を予測することです(自己教師あり学習)。このプロセスを通じて、モデルは語彙、文法、さらには一部の共通知識(都市の名前、有名人、一般的な事実など)を獲得します。をマスクし、「彼は自転車に乗って_行った」のようにします。そしてモデルは、マスクされた単語「学校」を予測するように学習します。この方法は、ラベル付きデータが不足している場合や、未知のパターンを学習する必要がある場合に非常に有用です。
BERTにおける自己教師あり学習
- Masked Language Model (MLM): この手法は入力文の中のランダムな単語をマスクし(隠し)、BERTにその隠された単語を予測させます。これにより、BERTは文脈全体を利用して単語の意味を理解する能力を養います。
- Next Sentence Prediction (NSP): このタスクでは、BERTは与えられた二つの文が連続しているかどうかを予測します。これにより、BERTは文章の間の関連性を理解することを学びます。
事前学習
事前学習は、モデルが基本的な言語理解を獲得するための初期段階です。このフェーズでは、モデルは大規模なテキストコーパス(ウェブページ、書籍、記事などから成る大量のテキスト)を用いて学習します。学習の目標は、与えられた単語やフレーズの文脈から次の単語を予測することです(教師あり学習)あるいは文中のマスクされた単語を予測することです(自己教師あり学習)。このプロセスを通じて、モデルは語彙、文法、さらには一部の共通知識(都市の名前、有名人、一般的な事実など)を獲得します。この事前学習が終わった後にファインチューニング行います。
ファインチューニング
ファインチューニングは、特定のタスク向けにモデルのパフォーマンスを最適化するプロセスです。このフェーズでは、特定のタスクに関連する小さなラベル付きデータセット(例えば、感情分析、質問応答、文章生成など)を用いてモデルをさらに訓練します。事前学習で獲得した一般的な言語理解能力に加え、モデルはこの段階で特定のタスクに関する知識やスキルを獲得します。
大規模言語モデルのアラインメント
アラインメント (Alignment)
大規模言語モデル(LLM: Large Language Models)のアラインメントとは、モデルの行動を人間のユーザーにとって有用で安全になるように調整することを指します。これは、望ましい行動を強化し、望ましくない行動を抑制するプロセスと言えます。
大規模言語モデルをアラインするためにはいくつかのアプローチがあります。一つは、有用で正直で無害(HHH: Helpful, Honest, Harmless)なテキストプロンプトをモデルに注入することです。これにより、モデルのアラインメントを改善し、有害な出力を減らすことができます。もう一つの方法は、人間のフィードバックを用いた強化学習(RLHF: Reinforcement Learning from Human Feedback)を活用することです。これにより、モデルは有用で無害な出力を生み出すように訓練されます。
しかし、これらのアラインメントの方法はある程度効果的ではあるものの、それでも危険なほど壊れやすいと指摘されています。特に、短い敵対的なプロンプトは、モデルがネガティブな行動や社会的なバイアスを引き起こす可能性があります。また、アラインメント手法が不完全であることが報告されており、RLHFのステップ数と一部のネガティブな行動の間には逆のスケーリングが存在するという事実も浮かび上がっています。
人間のフィードバックによる強化学習 (RLHF)
人間からのフィードバックを用いた強化学習(Reinforcement Learning from Human Feedback、以下RLHF)は、人間からのフィードバックを報酬として利用する強化学習を行う手法です。RLHFは主に以下の3つのステップで行われます。
- 事前学習(Pretraining):このステップでは、モデルは大量のテキストデータを用いて学習します。これにより、モデルは文法、語彙、一般的な知識、ある程度の推論能力などを獲得します。この学習は主に教師なし学習(unsupervised learning)の手法が使われます。
- 微調整(Fine-tuning):事前学習後、モデルは特定のタスクに対するパフォーマンスを向上させるために、人間からのフィードバックを用いて微調整されます。このフィードバックは、モデルの出力が正しいかどうか、またはどの出力が最も適切かを評価するものです。
- 強化学習(Reinforcement Learning):微調整されたモデルは、人間からのフィードバックに基づく報酬を最大化するように、さらに学習します。ここでの報酬は、モデルの出力がどれほど人間の評価者にとって有益であるかを示します。
この3つのステップは、モデルが理解し、適応し、そして人間の意図により近づくためのプロセスを表しています。RLHFの目的は、AIモデルが人間の利益になるような行動をとることを最大化することです。
RLHFの利点
まず一つ目は、人間の価値基準がAIモデルの出力に反映される点です。RLHFは人間の意図や好みを反映した出力を得るための学習プロセスであるため、モデル作成者が何を重視するかという情報がAIモデルの行動に直接影響を与えます。これにより、人間が目指す特定の結果を達成するためのAIモデルを作ることが可能になります。
二つ目のメリットは、既存の言語モデルをチューニングしやすいという点です。AIモデルは学習データから知識を得ますが、RLHFを利用することで、人間が具体的な指示や要求をすることでその行動を調整することができます。例えば、ChatGPTのような会話型AIはRLHFを利用して、人間の意図に沿った、かつ無害な対話を実現するように調整されています。
三つ目は、報酬の決定方法を柔軟に設定できるというメリットがあります。モデルの学習を行う際、人間がAIが生成した応答文の良し悪しを評価し、それを基に報酬を与えます。この報酬の与え方を設計する際に、モデル作成者の好みを反映させることができます。これにより、より人間が望む応答文を生成するAIモデルの設計が可能になります。
また、具体的なプロセスとしては、事前学習の段階で人間が提供したプロンプトとそれに対応する望ましい応答のセットを教師データとして使用することで、モデル作成者の意図が生成モデルに反映されます。
RLHFの課題
ただし、RLHFは完璧な手法ではありません。モデルが人間のフィードバックから学習するため、フィードバックが偏っていると、モデルもそれに基づいて偏った結果を出す可能性があります。また、フィードバックは必ずしも正確であるとは限らず、モデルが誤った情報を学び取る可能性もあります。
RLHFの主な課題の一つは、人間のフィードバックのスケーラビリティとコストです。これは、教師なし学習に比べて遅く、コストがかかることがあります。また、人間のフィードバックの質と一貫性は、タスクやインターフェース、人間の個々の嗜好によって異なることがあります。人間のフィードバックが可能であっても、RLHFモデルはまだ人間のフィードバックによって捉えられない望ましくない行動を示すか、報酬モデルの抜け穴を利用する可能性があります。これは、整列性と堅牢性の課題を浮き彫りにします 。
RLHFの効果は、人間のフィードバックの質に依存します。フィードバックが公平性を欠いたり、一貫性がなかったり、誤っていたりすると、AIは間違ったことを学ぶ可能性があります。これはAIのバイアスとも呼ばれます。また、AIが受け取ったフィードバックに過度に適応するリスクもあります。たとえば、フィードバックが特定の人口統計学的グループから主に来ていたり、特定のバイアスを反映していたりすると、AIはこのフィードバックから過度に一般化することを学ぶ可能性があります。
インストラクション・チューニング (Instruction Tuning)
Instruction Tuningとは、事前学習済みの言語モデルを対象とした手法で、モデルが特定のタスクを実行するように微調整(Fine-tuning)を行う手法です。ただし、その特性は一般的なタスク特化型のFine-tuningとは異なります。ここで重要なのは、「指示」(Instruction)と呼ばれるタスクを記述した情報をモデルに与えて、その指示に基づいて行動するようにモデルを訓練するという点です。様々なタスクでファインチューニングすることで、未知のタスクに対するZero-shotのパフォーマンスを向上させることができます。
例えば、多様なタスク(B、C、Dなど)についてモデルを訓練しますが、それぞれのタスクに対して「指示」を与えます。この指示は、例えばタスクBに対しては「次の文章を要約せよ」といった具体的な説明であり、それに基づきモデルは学習を行います。重要なのは、この方法では、モデルは単に特定のタスクの実行を学習するだけでなく、与えられた「指示」に基づいて行動することを学習します。これにより、モデルは未知のタスク(A)についても、適切な「指示」が与えられれば、そのタスクを遂行することが可能となります。
例えば、モデルが以前に経験したことのない新たな要約タスクが与えられたとしても、そのタスクの指示を「次の文章を要約せよ」と指定することで、モデルはそのタスクを解決する方法を理解し、適切な応答を生成することができます。
大規模言語モデルにおける生成の仕組み
コンテキスト内学習 (In-Context Learning)
In-Context Learning(文脈学習)はGPT-3の論文内で提案された手法で、大規模な言語モデルにおいて特定のタスクに対応するために、パラメータを個別に更新(fine-tuning)することなく、そのタスクの説明や入出力例を見る中で学習するアプローチを指します。つまり、与えられたプロンプト(テキスト)を入力とし、そのプロンプトからタスクを理解し、適切な出力を生成することを学習します。それにより、特定のタスクに適応するために新たにパラメータを調整し学習し直すという手間を省くことが可能となります。
先に述べたファインチューニングは、ある特定のタスクにおけるモデルの精度を向上させるための方法として人気があります。ファインチューニングは教師ありの強化学習の一種で、モデルをさらに学習させて精度を上げていくものです。しかし、その一方で、新たなタスクに適応するためにはモデルを再学習する必要があり、そのたびに時間とリソースが必要となるという課題がありました。それに対して、In-Context Learningは各タスクの説明や例から学習を進めるため、一度の学習で多様なタスクに適応できるメリットがあります。
In-Context Learningを大規模コーパスを用いた事前学習と組み合わせたものはメタ学習とも呼ばれます。特に、In-Context Learningにおいて与えられる入力が0、1、または十分少ない場合をそれぞれZero-shot Learning(ゼロショット学習)、One-shot Learning(ワンショット学習)、Few-shot Learning(フューショット学習)と呼びます。これらは事前に言語知識を身につけ、タスクの説明や例を見る中で学習を進める点において、人間の学習と似ています。
この学習方式は、事前学習済みのモデルであっても、特定のタスクに適応するためにラベル付きデータが必要な問題を解消します。具体的には、特定のタスクに適応するためには大量のラベル付きデータを必要とする従来の方法では、データのアノテーションに時間とコストがかかるという問題がありました。しかし、In-Context Learningではその課題を克服し、より効率的に多様なタスクへの適応を可能にしています。
Zero-ShotとFew-Shot
Few-shot learningとは、極めて少数のトレーニングサンプルから一般化能力を獲得する学習パラダイムを指します。この技術は、共通のタスク表現を学習し、その表現に基づいてタスク固有の分類器を構築することで、データの少なさにも関わらず高性能なモデルを作り出す能力があります。
OpenAIのGPT-3は、その高度なFew-shot学習能力で知られています。GPT-3は、学習後のパラメータを更新することなく、タスクの情報とわずかなデモンストレーションをプロンプトとして受け取ることで、さまざまな自然言語処理(NLP)タスクを処理することができます。これにより、モデルはタスク固有の知識を獲得し、新しいコンテクストでも適切に対応する能力を発揮します。
一方、Zero-shot learningは、訓練中に直接学習されなかったクラスの分類を行う技術を指します。これは、モデルが訓練中に見ていない新しいタスクやクラスについての予測を行う能力があります。
GPT-3のケースでは、Zero-shot learningは、モデルに与えられるのがタスクの説明だけで、具体的なデモンストレーションが一切与えられない状況を指します。このシナリオでは、GPT-3は自身の学習済み知識を活用して、問題を解決するための答えを生成します。
サンプリング手法
大規模言語モデル(LLM)は、テキストを生成する際に異なるサンプリング手法を使用します。これらの手法は、モデルが出力するテキストのバリエーションや一貫性を制御します。
- Greedy Sampling:これは最もシンプルな形のサンプリングで、各ステップで最も高い確率を持つ次の単語を選択します。この手法は高速であり、出力の一貫性は保たれますが、出力に多様性が欠ける可能性があります。
- Beam Search:Beam Searchはgreedy samplingを拡張したもので、各ステップで確率の高い複数の「ビーム」(単語のシーケンス)を保持し、それら全体を評価して進めていきます。最終的な出力は最も確率の高いビームを選択します。これはより一貫した出力を提供しますが、greedy samplingと同様に、多様性が欠ける可能性があります。
- Stochastic Sampling (Random Sampling):この手法では、各ステップで次の単語を確率分布に基づいてランダムに選択します。これにより、より多様なテキストを生成できますが、一貫性が低下する可能性もあります。
- Top-K Sampling:この方法では、モデルが最も可能性が高いと判断した上位K個の単語からランダムに選択します。これにより、生成されるテキストに多様性を持たせつつ、極端な単語の選択を防ぐことができます。
- Top-p Sampling (Nucleus Sampling):このサンプリング手法では、次の単語の確率分布が累積して指定されたp値を超えるまでの単語を考慮に入れ、その範囲からランダムに選択します。これは、適度な多様性と一貫性を持つテキストを生成するためにしばしば用いられます。
生成モデルの技術動向
条件付き生成
大規模言語モデルは、事前に数十億の文書から学習し、文字、単語、または文章の並びを予測する能力を持つAIシステムです。この学習は、人間が文章を読み、次の単語やフレーズを予想するプロセスに似ています。AIは、入力された単語やフレーズから次に来る最も可能性の高い単語やフレーズを予測します。
しかし、AIはただ予測するだけでなく、特定の「条件」に従って出力を制御することも可能です。これが「条件付き生成」です。これにより、AIは、特定の話題やスタイル、観点などに基づいて情報を生成することが可能になります。
例えば、ユーザーが「太陽系について簡単な説明を書いてください」という指示をAIに与えると、AIは「太陽系」に関する情報を生成し、それを「簡単な」形で表現します。また、ユーザーが「シェイクスピアのスタイルで詩を書いてください」と指示すると、AIはシェイクスピアの言語や韻律に基づいて詩を生成します。
大規模言語モデルによる条件付き生成は、教育、エンターテイメント、文書生成など、幅広い応用分野での可能性を持っています。しかし、これらのモデルはあくまで学習したデータに基づく予測を行うため、その出力は常に完全に信頼できるわけではないことを理解することが重要です。そのため、人間の監視と介入が必要となる場合もあります。
CLIP (Contrastive Language–Image Pretraining)
CLIP (Contrastive Language–Image Pretraining)は、OpenAIによって開発されたモデルで、テキストと画像間の豊かなセマンティックな関係を学習します。CLIPは画像とテキストを同時に理解する能力を持ち、モデルはテキストの指示に基づいて画像を分類したり、逆に画像の内容を説明したりすることができます。
条件付き生成とは、一般的には、モデルが特定の条件を満たすようにデータを生成する能力を指します。具体的な例としては、言語モデルに対する初期プロンプトや、画像生成モデルに対するラベルなどがあります。
これをCLIPの文脈に適用すると、CLIPはテキストプロンプトを条件として使用し、そのプロンプトと一致または関連性のある画像を「生成」する能力があります。ただし、注意すべき点として、CLIP自体は実際には画像を生成する能力を持っていません。代わりに、大規模な画像集合から最もプロンプトに適合する画像を「選ぶ」能力を持っています。
CLIPの学習プロセスは次のようになります。
モデルは大量のテキスト-画像ペアで事前学習されます。これらのペアはインターネットから集められ、関連性のあるテキストと画像が一緒に存在することが前提となっています。
その後、モデルは特定の画像が与えられたときに、その画像と最も一致するテキスト(またはその逆)を予測するように訓練されます。
このプロセスは、画像とテキストの間に存在する複雑な関連性を捉えるために、コントラスティブ(対比的)な損失関数を用いて行われます。
CLIPは一種の条件付き生成モデルと見なすことができますが、その出力は実際の「生成」ではなく、与えられた条件に最も一致する既存のデータ(この場合、画像)の選択です。
拡散モデル (Diffusion Model)
拡散モデルは、新たな強力な深層生成モデルの一族であり、画像合成、ビデオ生成、分子設計など、多くの応用で最高のパフォーマンスを記録しています。これらは、効率的なサンプリング、改善された尤度推定、特殊な構造を持つデータの取り扱いなど、3つの主要な研究領域にカテゴライズされます。さらに、拡散モデルを他の生成モデルと組み合わせる可能性も提案されています。
拡散モデルは、データにノイズを注入して徐々に破壊し、そのプロセスを逆に学習してサンプル生成を行う確率的生成モデルの一族です。現在の拡散モデルの研究は、主に以下の3つの定式化に基づいています:ノイズ除去拡散確率モデル (DDPMs)、スコアベースの生成モデル (SGMs)、確率微分方程式 (Score SDEs)。
- ノイズ除去拡散確率モデル (DDPMs):DDPMは、データをノイズに変え、ノイズをデータに戻す2つのマルコフ連鎖を使用します。前者は、任意のデータ分布を単純な事前分布(例えば、標準ガウス分布)に変換することを目指して手作業で設計されます。後者のマルコフ連鎖は、前者を逆にするために、深層ニューラルネットワークによってパラメータ化された遷移カーネルを学習します。新しいデータポイントは、事前分布からランダムベクトルを最初にサンプリングし、逆マルコフ連鎖を通じて祖先サンプリングを行うことによって生成されます。
- スコアベースの生成モデル (SGMs):SGMsの中心的な概念はスコア(またはスコア関数)です。SGMsの主要なアイデアは、データを強度を増すガウスノイズで変え、すべてのノイズデータ分布のスコア関数をノイズレベルに条件づけた深層ニューラルネットワークモデルを訓練することで同時に推定することです。サンプルは、スコアベースのサンプリングアプローチとともに、減少するノイズレベルでのスコア関数を連鎖させることによって生成されます。
- 確率微分方程式 (Score SDEs):DDPMとSGMは、時間ステップやノイズレベルが無限大のケースにさらに一般化でき、摂動とノイズ除去のプロセスは確率微分方程式(SDE)の解となります。この定式化はScore SDEと呼ばれ、SDEを用いてノイズの摂動とサンプル生成を行い、ノイズ除去のプロセスではノイズデータ分布のスコア関数の推定が必要となります。
なお、モデルがどの程度データを生成する能力を持つかを測定するためには、Inception Score (IS) と Fréchet Inception Distance (FID) が一般的に使用されます。ISは、モデルが多様で意味のある画像を生成する能力を評価するために使用されます。一方、FIDは、生成された画像の分布と実際の画像の分布との間の距離を測定します。これらの指標は、生成モデルのパフォーマンスを定量的に評価するための標準的な方法です。
Stable Diffusion
Stable Diffusionは、テキストベースの入力から画像を生成する深層学習モデルで、2022年に開発されました。その主な用途はテキストに基づいた詳細な画像の生成ですが、補間、外挿、テキストプロンプトによってガイドされた画像間の翻訳の生成など、他のタスクにも対応可能です。開発はルートヴィヒ・マクシミリアン大学のCompVis GroupとRunwayが行い、Stability AIからの計算支援と非営利団体からのトレーニングデータを使用しました。
Stable Diffusionは「latent diffusion model」と呼ばれる深層生成ニューラルネットワークの一部であり、そのコードとモデルの重みは公開されています。ほとんどの一般的なハードウェアで稼働可能で、少なくとも8GBのVRAMを持つ適度なGPUが必要です。
モデルの構成は、変分自己符号化器(VAE)が画像をピクセル空間からより小さな次元の潜在空間に圧縮し、基本的なセマンティック情報を捉えるところから始まります。その圧縮された潜在表現には、前方拡散中にガウスノイズが繰り返し適用されます。次に、ResNetのバックボーンを用いたU-Netブロックが前方拡散の出力をバックワードにノイズ除去し、潜在表現を取得します。最後に、VAEデコーダがこの表現をピクセル空間に戻し、最終的な画像を生成します。
Stable Diffusionは、ユーザーが特定の要素を含むか省くようなテキストプロンプトを使用して新しい画像をゼロから生成する機能をサポートしています。また、「guided image synthesis」と呼ばれるプロセスを通じて、テキストプロンプトにより新しい要素を含むように既存の画像をモデルが再描画する機能もサポートしています。
しかし、モデルにはいくつかの制約があります。たとえば、人間の手足の生成に問題が発生することがあります。これは、訓練データベースの手足のデータ品質が低いためです。さらに、特定の新しいユースケース(例えば、アニメキャラクターの生成)に対応するためには、新たなデータと追加の訓練が必要です。このような微調整は、新たなデータの品質に敏感であり、低解像度の画像やオリジナルデータと異なる解像度の画像を使用すると、新たなタスクを学習できないだけでなく、モデルの全体的なパフォーマンスを低下させる可能性があります。
大規模言語モデルのオープン化の動向と原因
オープンコミュニティ
大規模言語モデルのオープンコミュニティの一例として、Hugging Faceがあります。
Hugging Faceは、自然言語処理(NLP)を中心に活動するオープンソースのコミュニティです。具体的には、NLPモデルの開発やモデルの学習を容易にするためのツールやライブラリを提供しています。
最も注目されているライブラリの一つが「Transformers」で、これはさまざまな大規模な事前学習済み言語モデル(LLM)、例えばBERT、GPT-2, GPT-3などを扱うためのものです。Transformersは研究者や開発者がこれらのモデルを手軽に利用でき、新しいモデルを学習したり、既存のモデルをファインチューニングしたりするためのツールキットを提供しています。
また、Hugging Faceはモデルの共有や再利用を促進するためのモデルハブを提供しています。このモデルハブでは、研究者や開発者が自分たちが訓練したモデルを公開し、他の人々がそれを再利用することが可能です。これにより、コミュニティ全体が持つ知識や経験を共有し、一緒に学ぶことができます。
さらに、Hugging Faceはコミュニティが質問を投稿したり、議論を行ったり、新しいアイデアや手法を共有したりするためのフォーラムも提供しています。これにより、Hugging Faceのユーザーは最新のNLPの研究や開発について議論したり、問題解決のためのアドバイスを得たりすることができます。
オープン大規模言語モデル
2023年2月、Meta AI社はLLaMAというオープンソースの大規模言語モデル(Large Language Model、以下LLM)を公開し、これが多数の同様の開発に火をつけるきっかけとなりました。これに引き続き、LAION AI社もOpenAssistantというオープンソースのLLMをリリースし、これらの事例を通じて全世界的にLLMのオープンソース化の流れが見られるようになりました。
特に2023年3月から4月にかけては、VicunaやBaizeといった研究目的で利用されるオープンソースのLLMが次々と開発・公開されるようになりました。その後、Dolly 2.0などの商用利用が可能なオープンソースのLLMも開発されるなど、LLMの応用範囲は更に広がりを見せています。
2023年4月後半から5月にかけては、画像入力が可能なモデルの開発が活発化しました。LLaVAやMiniGPT-4などは、これらの要求に対応するために特別にチューニングされています。また、最近では日本語特化のオープンソースLLMとしてOpenCALMやJapanese-gpt-neoxが公開され、各地域の特定の要件に対応する動きも見受けられます。
これらの多種多様なLLMの性能は、LLM-Leaderboardというプラットフォームを通じて確認・比較することが可能であり、開発者や研究者にとって有用な参照情報となっています。オープンソースのLLMの動向は新たな研究や応用開発の可能性を示す一方で、それぞれのモデルがどのような特性を持ち、どのような目的に最適化されているかを把握することは、それを適切に利用・応用するためには重要な要素となっています。
オープンデータセット
RedPajama-Data
RedPajama-Dataは、大規模言語モデルの訓練のための一組のデータセットを生成するためのコードを集約したリポジトリであり、オープンソースの言語モデル開発の一環として位置づけられているプロジェクト「RedPajama」の一部です。その主な成果として、LLaMAトレーニングデータセットを再現し、それには1兆2000億を超えるトークンが含まれています。
RedPajama-Dataの組成は、7つの主要なデータセクションによって構築されています。これらは以下のとおりです。
- CommonCrawl:このセクションには、約8780億のトークンが含まれています。
- C4:ここには、1750億のトークンが収録されています。
- GitHub:この部分は、約590億のトークンをカバーしています。
- Books:このセクションには、260億のトークンが収録されています。
- ArXiv:この部分には、280億のトークンが含まれています。
- Wikipedia:240億のトークンを含むこのセクションは、知識の宝庫となっています。
- StackExchange:この部分は、200億のトークンを含んでいます。
これらすべてを合計すると、約1兆2000億のトークンが集められ、慎重に前処理とフィルタリングが行われています。この広範なデータセットは、AIの研究と開発に関心を持つ者にとっての資源として、Hugging FaceというAI向けのリポジトリプラットフォームで公開されており、全世界の研究者や開発者が自由に利用できます。
Dolly v2
Dolly v2は、Databricksによって開発された大規模言語モデルで、特定の指示に基づいて行動する能力を有しています。このモデルは、EleutherAIのPythia-2.8bという先進的な言語モデルを基礎とし、Databricksの従業員によって作成された約15,000件の指示と応答のペアを集約したオープンソースのデータセット、databricks-dolly-15kを利用して微調整(ファインチューニング)されています。
このdatabricks-dolly-15kデータセットは、InstructGPTという論文で提唱されたいくつかの能力領域を踏まえて構築されています。これらの領域には、ブレインストーミング、分類、閉鎖型質問応答(クローズドQA)、生成、情報抽出、開放型質問応答(オープンQA)、要約等が含まれています。
このデータセットは、Apache-2.0 licenseという商業利用も可能なライセンスの下で公開されています。したがって、このデータセットは、研究目的だけでなく、商業的な製品開発においても利用することが可能です。このように、Dolly v2は商業的な実用性と学術的な洞察の両方を提供する、先進的な大規模言語モデルとしての位置付けられています。
| プロジェクト/データソース | 説明 |
|---|---|
| RedPajama | RedPajamaは、完全にオープンソース化された大規模言語モデルを開発するプロジェクトであり、高品質で範囲をカバーする事前学習データの開発を行っています。AI向けリポジトリサイトのHugging Faceで公開されています。 |
| Pile | Pileは、825GiBの多様なオープンソースの言語モデリングデータセットで構成されています。 |
| CommonCrawl | CommonCrawlは、最大のオープンソースのウェブクローリングデータベースの一つで、ペタバイトスケールのデータ量を含み、非常に規模の大きな言語モデルの訓練データとして広く使用されています。 |
| Redditは、リンクとテキスト投稿をユーザーが投稿でき、他の人が「アップボート」または「ダウンボート」で投票できるソーシャルメディアプラットフォームです。高品質なデータセットを作成するために利用されます。 | |
| Wikipedia | Wikipediaは、多種多様なトピックについての高品質な記事を大量に含むオンライン百科事典です。多言語の大規模言語モデル訓練にも使用できます。 |
オープンソース
最近流出したGoogleの内部文書によれば、AI業界の競争では最終的な勝者が「オープンソース」になると予測されています。文書では、業界のリーダーとしてMetaが挙げられ、OpenAIは他社ほど重要でないと示唆されています。また、Googleの「LaMDA」開発がMetaの「LLaMA」モデルと比較され、大部分のオープンソースイノベーションはMetaのアーキテクチャ上で行われているとされ、Metaはこの技術を自社製品に直接組み込む能力を持つと述べられています。
大規模言語モデルの性能を決める要素の動向と原因
スケーリング則 (Scaling Laws)
大規模言語モデルのスケーリング法則(Scaling Laws)は、モデルの性能がその規模、つまりモデルのパラメータ数、訓練データセットの規模、および計算量という三つの要素に依存するという規則です。これらの要素はパワーロー(power-law)関係を持ち、この関係性は7つ以上の桁数にわたる広範な範囲で存在します。
この法則において特筆すべき点は、モデルの詳細なネットワーク構造(例えばネットワークの深さや幅)は、一般的にモデルの性能に対する影響が少ないとされていることです。つまり、大規模言語モデルの性能向上は、主にモデルの規模拡大、訓練データの拡大、および計算リソースの増加によって達成されます。
大規模なトランスフォーマー言語モデルのテスト損失(つまり、モデルがどれだけ正確に新たなデータを予測できるか)を予測するためには、以下の三つの条件におけるパワーローが考慮されます。
- パラメータ数が限られたモデルが、大規模なデータセットで訓練される場合。
- 早期停止を行い、制限されたデータセットで訓練される大規模モデルの場合。
- 計算量が制約されていても、大規模なデータセット、適切なサイズのモデル、そして最適なバッチサイズ(最適な計算の使用)で訓練される場合。
これらの条件下では、パラメータ数、データセットの規模、および訓練に使用する計算量を増やすことにより、それらの大数に比例してテスト損失が減少(モデルの性能を向上)させることが可能です。
しかし、最近の研究により、新たな訓練手法であるUL2Rの使用により、大規模言語モデルのパフォーマンスやそのスケーリングカーブが大幅に改善されることが示されています。UL2Rは、混合デノイザーオブジェクティブを使用し、既存の大規模言語モデル(例えばPaLM)をさらに数ステップ訓練します。これにより、追加計算コストはわずかながら、スケーリング特性が大きく改善します。
さらに、UL2Rはモデルにプレフィックス言語モデリングと長短スパンの腐敗(例えば、インフィリング)タスクを組み合わせたUL2の目的を教えます。これにより、モデルは新たなプロンプト機能を学習し、複数の空白を含むインプットプロンプトの空白を埋める能力を獲得します。
この新しい手法の使用により、既存の数ショットNLPタスクのスケーリング法則が大幅に改善され、UL2Rが計算量の約半分で、最終的なPaLM 540Bモデルと同等のパフォーマンスを得ることが可能になりました。
UL2Rの採用により、U-PaLMは新しいタスクパフォーマンスと全体的に改善されたスケーリングカーブを持ち、さらに入力プロンプト中の複数の空白を埋める二次的なプロンプト機能、つまり双方向インフィリングを持つようになります。これにより、モデルの利用価値は大幅に向上します。
データセットのサイズ
規模言語モデル (LLM) のトレーニング データセットのサイズは、数十億から数千億のパラメーターに及びます。
GPT-3では、その訓練に約45TBの大規模なデータセットを前処理することにより生み出された、約570GBのテキストデータを使用しています。このモデルは、およそ1兆7500億という膨大なパラメータ数を有しています。
この言語モデルの訓練におけるデータセットは多様で、その中にはWebText、Wikipedia、Common Crawl、ニュースのアーカイブ、書籍、科学論文といった様々なソースが含まれています。それらは膨大な情報を提供し、言語モデルの学習に対する深みと広さを増しています。
また、GPT-3の訓練データセットはその前世代であるGPT-2と比較すると顕著に大きな規模となっています。GPT-2は約40GBのデータセットと150億のパラメーターを持っていたのに対して、GPT-3はそれらをはるかに超越しています。この進化は、言語モデルの進歩とともに訓練データの規模と複雑さが増大する傾向を示しています。
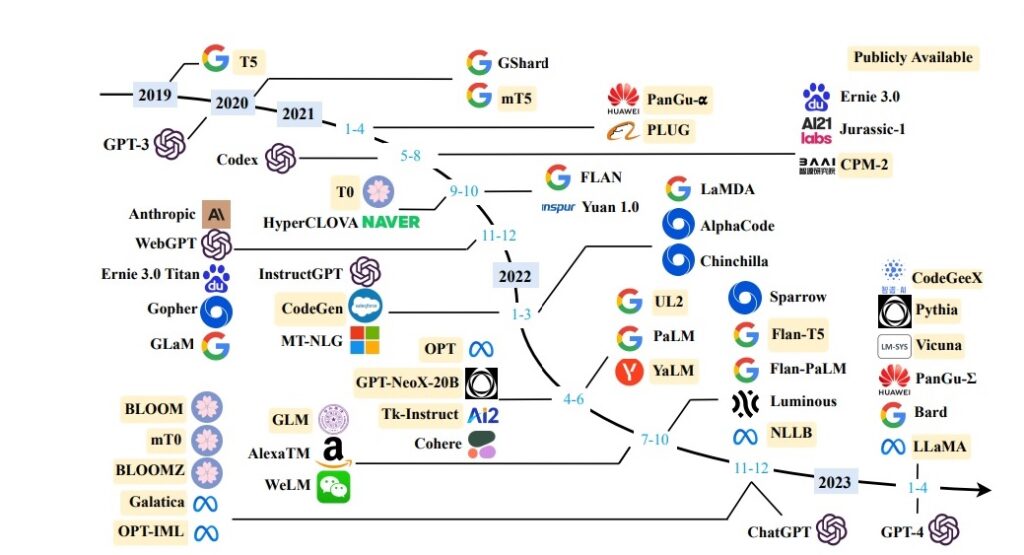
以下に主要な大規模言語モデルとそのプレトレーニングに使用されたデータの規模を示します。
| モデル名 | プレトレーニング データ規模 |
|---|---|
| T5 | 1T tokens |
| mT5 | 1T tokens |
| PanGu-α | 1.1TB |
| CPM-2 | 2.6TB |
| T0 | - |
| CodeGen | 577B tokens |
| GPT-NeoX-20B | 825GB |
| Tk-Instruct | - |
| UL2 | 1T tokens |
| OPT | 180B tokens |
| NLLB | - |
| GLM | 400B tokens |
| Flan-T5 | - |
| BLOOM | 366B tokens |
| mT0 | - |
| Galactica | 106B tokens |
| BLOOMZ | - |
| OPT-IML | - |
| LLaMA | 1.4T tokens |
| CodeGeeX | 850B tokens |
| Pythia | 300B tokens |
| GPT-3 | 300B tokens |
| GShard | 1T tokens |
| Codex | 100B tokens |
| ERNIE 3.0 | 375B tokens |
| Jurassic-1 | 300B tokens |
| HyperCLOVA | 300B tokens |
| FLAN | - |
| Yuan 1.0 | 180B tokens |
| Anthropic | 400B tokens |
| WebGPT | - |
| Gopher | 300B tokens |
| ERNIE 3.0 Titan | - |
| GLaM | 280B tokens |
| LaMDA | 768B tokens |
| MT-NLG | 270B tokens |
| AlphaCode | 967B tokens |
| InstructGPT | - |
| Chinchilla | 1.4T tokens |
| PaLM | 780B tokens |
| AlexaTM | 1.3T tokens |
| Sparrow | - |
| WeLM | 300B tokens |
| U-PaLM | - |
| Flan-PaLM | - |
| Flan-U-PaLM | - |
| GPT-4 | - |
| PanGu-Σ | 329B tokens |
データセットの質
大規模言語モデルの学習におけるデータセットの量と品質という二つの要素が重要となります。
データセットの量という観点から見ると、学習に用いる情報の量が多いほど、モデルのパフォーマンスが一般的に向上するとされています。これは、広範な情報源から学習を行うことにより、モデルはより幅広く精密な知識を獲得する可能性が増大するからです。ただし、注意点としてデータの量がある一定の量を超過すると、パフォーマンスの低下や過学習といった問題が顕在化する可能性があります。
一方、データセットの品質という観点からは、高品質なデータセットから学習することで、モデルのパフォーマンスと能力が向上するという認識があります。高品質なデータから学習することにより、モデルはより正確で信頼性の高い情報を獲得する可能性があるためです。さらに付言すれば、データの品質だけではなく、データの均一性もまた重要です。データセット内の各ケースが全体で均一に分布するようにすることにより、偏りのない学習が可能となります。
具体的な目標達成を視野に入れた場合、一般的なテキストデータだけではなく、特定の目的に特化したデータソースの活用が求められます。この理由としては、特定の目的に適合した形式のデータセットが、その目的達成に対して有効性を発揮するためです。
データセットの収集方法としては、ウェブページ、CommonCrawl、Redditのリンク、Wikipediaなどが一般的に利用されます。これらの情報源からデータを収集する際には、適切なフィルタリングと処理を行うことで、データの品質が保証され、その有用性が増大します。
また、データセットのオープンソース化により、質の高いデータを入手することが用意になっています。
モデルのパラメーター数
大規模言語モデルのパラメーター数はそのモデルの複雑さを示す一つの指標です。多くのパラメーターを持つモデルはより多くのデータを学習し、より複雑な関係やパターンを捉える能力があります。
以下に、主要な言語モデルとそれらのパラメーター数を示します:
- GPT (Generative Pretrained Transformer) - 1.5億のパラメーター
- GPT-2 - 15億のパラメーター
- GPT-3 - 1750億のパラメーター
このような大規模モデルは大量の計算リソースを必要とし、モデルの訓練には長い時間と膨大な量のデータが必要です。しかし、これらの大規模モデルは、非常に自然な人間のようなテキストを生成する能力を持ち、多くのNLP (自然言語処理) タスクで優れた結果を示します。
それらのモデルは一般的な言語理解や生成タスクだけでなく、文書の要約、質問応答、翻訳、テキスト生成など、多くの応用例に使われます。また、最近の研究では、これらのモデルを使用して特定のタスクに適応させるための微調整(fine-tuning)が一般的に行われています。
しかし、これらの大規模モデルには課題もあります。例えば、モデルの透明性と解釈可能性、訓練データに基づくバイアス、誤った情報の生成、エネルギー消費といった環境への影響などが挙げられます。
以下に主要な大規模言語モデルとそのパラメータ数を示します。
| モデル名 | サイズ(B) |
|---|---|
| T5 | 11 |
| mT5 | 13 |
| PanGu-α | 13* |
| CPM-2 | 198 |
| T0 | 11 |
| CodeGen | 16 |
| GPT-NeoX-20B | 20 |
| Tk-Instruct | 11 |
| UL2 | 20 |
| OPT | 175 |
| NLLB | 54.5 |
| GLM | 130 |
| Flan-T5 | 11 |
| BLOOM | 176 |
| mT0 | 13 |
| Galactica | 120 |
| BLOOMZ | 176 |
| OPT-IML | 175 |
| LLaMA | 65 |
| CodeGeeX | 13 |
| Pythia | 12 |
| GPT-3 | 175 |
| GShard | 600 |
| Codex | 12 |
| ERNIE 3.0 | 10 |
| Jurassic-1 | 178 |
| HyperCLOVA | 82 |
| FLAN | 137 |
| Yuan 1.0 | 245 |
| Anthropic | 52 |
| WebGPT | 175 |
| Gopher | 280 |
| ERNIE 3.0 Titan | 260 |
| GLaM | 1200 |
| LaMDA | 137 |
| MT-NLG | 530 |
| AlphaCode | 41 |
| InstructGPT | 175 |
| Chinchilla | 70 |
| PaLM | 540 |
| AlexaTM | 20 |
| Sparrow | 70 |
| WeLM | 10 |
| U-PaLM | 540 |
| Flan-PaLM | 540 |
| Flan-U-PaLM | 540 |
| GPT-4 | - |
| PanGu-Σ | 1085 |
計算資源の効率化
PEFT(Parameter-Efficient Fine-Tuning)
大規模言語モデルにファインチューニングを適用すると、事前に学習済みのモデルのパラメータが部分的または全体的に更新され、モデルの出力動作を変化させます。ただし、事前に学習済みのモデルを特定の下流タスクに適応させるためには、通常は全パラメータの再学習が必要とされます。しかし、近年のモデルではパラメータの数が数千億にも上るため、全パラメータの再学習は現実的ではありません。
そのため、LLMや大規模な事前学習モデルの広範な利用を実現するには、通常のファインチューニング(Full FT)とは異なる、より効率的なファインチューニングの手法が求められます。これに応える新たな手法として注目を浴びているのが、パラメータ効率的なファインチューニング(Parameter-Efficient Fine-Tuning: PEFT)です。
PEFTは、LLMのような大規模な事前学習済みモデルを新たなタスクに効率的に適応させる手法であり、モデル全体のパラメータを更新する代わりに、一部のパラメータのみを更新します。これにより、Full FTに比べて計算コストとストレージコストを大幅に削減することが可能となります。また、PEFTは、事前学習で得た知識の忘却(壊滅的忘却)を抑えつつ、新しいタスクや未知の状況への適応性(汎化性能)を維持する特性を有しています。
PEFTの手法としては、トークン追加型、アダプター型、LoRA型などがあります。これらはそれぞれ、特定の問題解決に適した特性を持ちます。トークン追加型は、入力層に新たな仮想トークンを追加することで、特定のタスク固有の特徴を学習します。一方、アダプター型は、事前学習済みモデルの外部に新たなサブモジュールを追加し、そのサブモジュールのパラメータを更新します。LoRA型は、事前学習済みモデル自体のパラメータを固定したまま、低ランク行列のみを更新するという手法を採用しています。
これらの各種PEFT手法には、それぞれ特性があり、応用範囲や性能に差異があります。しかし、いずれのアプローチも計算コストの削減、壊滅的忘却の抑制、未知の状況に対する汎化性能の向上といった点で、ビジネス応用における有用性を持っています。
LoRA(Low-Rank Adaptation)
LoRA(Low-Rank Adaptation)は、生成型AI技術の一つで、事前学習済みモデルのパラメータを効率的に調整する手法です。この技術の最大の特徴は、事前学習済みモデルのAttention層のクエリとバリューに対して低ランク行列を適用し、元のモデルと同等またはそれ以上の性能を持ちながら、パラメータ数を大幅に削減することができるという点です。
具体的には、事前学習済みモデルのパラメータを固定(凍結)し、クエリとバリューの行列に対して低ランク行列を掛け合わせて新たな行列を生成します。この低ランク行列は、ファインチューニング(新たなタスクの学習)時に更新される唯一のパラメータとなります。
LoRAの使用により、事前学習済みモデルの99.9%以上のパラメータが固定され、新しいタスクの学習には低ランク行列のみが更新されます。その結果、大量のパラメータと計算要件を必要とする全パラメータのファインチューニング(Full FT)と同等の性能を実現しつつ、パラメータ数と計算要件を大幅に削減することが可能となります。
また、LoRAは言語タスクだけでなく、画像タスクにも効率的に適用することができるため、応用範囲が非常に広いです。
他のアダプテーション手法(例えばAdapter)と比較した場合、LoRAの利点は推論時の速度です。Adapterでは、事前学習済みモデルに新たに学習可能なパラメータが追加されるため、推論時間が長くなる可能性があります。しかし、LoRAでは、事前学習済みモデルの各層に学習可能な低ランク行列が注入され、推論中に凍結された重みと更新された重みをマージすることが可能です。これにより、推論の遅延が発生しにくくなります。
この特性により、LoRAは計算リソースやストレージコストが制約となる本番環境で、大規模な言語モデルをデプロイしやすくなります。
しかし、LoRAにはいくつかの課題が指摘されています。その一つは、低ランク行列への変換が元のモデルの表現力をある程度損なう可能性がある点です。また、パラメータの更新が元の事前学習済みモデルに依存しているため、その事前学習済みモデルの性能や制限事項を受け継ぐという問題もあります。
GPU
LLMの多くで生じる問題点の1つは、学習や推論に極めて大きな計算量とメモリ量を必要とすることにあります。
以下に主要な大規模言語モデルのモデル名(Model)、使用されたハードウェア(Hardware (GPUs / TPUs))、モデルの訓練に要した時間(Training Time)を示します。
| Model | Hardware (GPUs / TPUs) | Training Time |
|---|---|---|
| T5 | 1024 TPU v3 | - |
| mT5 | - | - |
| PanGu-α | 2048 Ascend 910 | - |
| CPM-2 | - | - |
| T0 | 512 TPU v3 | 27 h |
| CodeGen | - | - |
| GPT-NeoX-20B | 96 40G A100 | - |
| Tk-Instruct | 256 TPU v3 | 4 h |
| UL2 | 512 TPU v4 | - |
| OPT | 992 80G A100 | - |
| NLLB | - | - |
| GLM | 768 40G A100 | 60 d |
| Flan-T5 | - | - |
| BLOOM | 384 80G A100 | 105 d |
| mT0 | - | - |
| Galactica | - | - |
| BLOOMZ | - | - |
| OPT-IML | 128 40G A100 | - |
| LLaMA | 2048 80G A100 | 21 d |
| CodeGeeX | 1536 Ascend 910 | 60 d |
| Pythia | 256 40G A100 | - |
| GPT-3 | - | - |
| GShard | 2048 TPU v3 | 4 d |
| Codex | - | - |
| ERNIE 3.0 | 384 V100 | - |
| Jurassic-1 | 800 GPU | - |
| HyperCLOVA | 1024 A100 | 13.4 d |
| FLAN | 128 TPU v3 | 60 h |
| Yuan 1.0 | 2128 GPU | - |
| Anthropic | - | - |
| WebGPT | - | - |
| Gopher | 4096 TPU v3 | 920 h |
| ERNIE 3.0 Titan | - | - |
| GLaM | 1024 TPU v4 | 574 h |
| LaMDA | 1024 TPU v3 | 57.7 d |
| MT-NLG | 4480 80G A100 | - |
| AlphaCode | - | - |
| InstructGPT | - | - |
| Chinchilla | - | - |
| PaLM | 6144 TPU v4 | - |
| AlexaTM | 128 A100 | 120 d |
| Sparrow | 64 TPU v3 | - |
| WeLM | 128 A100 40G | 24 d |
| U-PaLM | 512 TPU v4 | 5 d |
| Flan-PaLM | 512 TPU v4 | 37 h |
| Flan-U-PaLM | - | - |
| GPT-4 | - | - |
| PanGu-Σ | 512 Ascend 910 | 100 d |
FlexGen
FlexGenは、Large Language Model (LLM)の処理を行うための生成エンジンで、2023年2月にリリースされました。このエンジンは、一般的なGPUを1つ積んだパソコンでもLLMの処理が行えるという特性と、高い生成スループットを持つという2つの特徴があります。
スループットとは、生成エンジンがどれだけの速さでトークン(単語や句読点などの意味を持つ最小単位)を生成できるかを示す指標で、FlexGenはこの指標に優れています。この能力により、LLMの処理が以前はGPUを並列に用いた高性能なPCや大規模なレンタルサーバー、クラウド上で主に行われていたものが、FlexGenによって一般的なPCでも行えるようになりました。
FlexGenがこのような特性を持つ理由は主に3つのメカニズムによるものです。まず一つ目は、GPU、CPUメモリ、そしてディスクを利用した分散処理(オフローディング)です。LLMの処理は通常、GPUに全てを任せるのが一般的ですが、FlexGenではこれら3つのリソースを利用して分散処理を行い、LLMのサイズがGPUのメモリを超えていても処理が可能になります。
二つ目のメカニズムは、LLMの重み、キー、バリューを4ビット整数に圧縮する処理(量子化)です。LLMの重要なパラメータであるこれらを精度を保ちつつ4ビットの整数に圧縮することで、データの容量を削減し、処理の負担を軽減します。
三つ目のメカニズムは、従来の処理手法と異なる順序で処理を行う「ジグザグ処理」です。従来の生成エンジンでは、全トークンのバッチを行ごとに処理しますが、FlexGenでは複数行のバッチを列ごとに処理します。これにより、行間で重みを共有する部分が多くなり、重みのロードを繰り返すことなく処理を進めることができます。ただし、この手法を採用するためには、メモリに残すパラメータの容量を管理する必要があります。
大規模言語モデルのマルチモーダル化の動向と原因
マルチモーダル
マルチモーダルとは、生成型AIモデルがテキスト、画像、動画、音声データなど、異なる形態(モダリティ)で出力を生成する能力を指します。これはAIがさまざまなアプリケーションで使用されるにつれて、ますます重要となってきています。
生成型AIモデルは訓練データのセットに基づいて新たなデータを生成する機能を持っています。例えば、猫の画像のデータセットで訓練された生成型AIモデルは、その訓練データセットに似た新たな猫の画像を生成します。
マルチモーダルの生成型AIモデルは、この概念を拡張し、複数のモダリティを組み合わせてより多様で微妙な出力を生成します。テキストと画像、またはテキストと音声の両方で訓練されたマルチモーダルの生成型AIモデルは、それぞれの入力に基づいて相応の出力を生成します。
マルチモーダルの生成型AIモデルの応用は非常に広範で、仮想アシスタントやチャットボットから芸術や音楽の創造まで、多くの分野で利用可能です。これらのモデルはユーザーに対してよりパーソナライズされた、没入型の体験を提供する能力を持っています。
しかしながら、マルチモーダルの生成型AIモデルの開発と訓練は、大量の多様なデータと専門的な訓練技術を必要とし、それは大きな課題となります。異なるモダリティを一緒に生成するモデルを訓練するには、それぞれのモダリティの入力を含むデータセットと、複数のモダリティを扱うことができる専門的な訓練アルゴリズムが必要です。
また、複数のモダリティを含む大量かつ多様なデータセットの必要性も開発の大きな課題となります。例えば、テキストと画像を一緒に生成するモデルを訓練するためには、テキストと画像の入力が互いに関連するようなデータセットが必要で、これによりモデルはテキストと画像の入力の間の統計的なパターンを学習し、それに基づいた新たな出力を生成します。
大規模言語モデルの外部ツール・リソースの利用の動向と原因
学習データの時間的カットオフ
学習データの時間的カットオフとは、学習に使用するデータの期間を指します。例えば、Chat-GPT、GPT-4は2021年9月までのデータを使用して学習されています。そのため、Chat-GPT、GPT-4は2021年9月以降の情報を正しく生成することができません。
ChatGPTのウェブブラウジング機能
ChatGPTはウェブブラウジング機能を備えており、これによりユーザーからの質問に対する最新の情報をWeb上から取得することが可能となっています。この機能の利用により、ChatGPTが学習したデータが2021年9月までの情報に限定されているという制約を補完することが可能となります。具体的には、最新のニュース記事や特定トピックに関するデータなど、インターネット上の情報を直接アクセスして答えを導き出すことができます。
ウェブブラウジング機能を利用するためには、ChatGPTの設定画面から「Beta Features」を有効化する必要があります。その後、特定の情報を必要とする質問を行うと、「ウェブを閲覧中…」という表示が出て、ChatGPTが情報を検索します。ただし、ChatGPTのウェブブラウジングは標準的なウェブブラウザの操作とは異なり、ページ全体を表示するのではなく、ユーザーの問い合わせに関連する情報に焦点を当て、それを会話形式で伝えます。
大規模言語モデルの知識
ChatGPTの知識範囲には、データの時期や分野、内容による制約が存在します。具体的には、このAIは訓練データに基づいて応答を生成しますが、その訓練データは主に2021年までの情報に基づいています。したがって、それ以降の情報や出来事については、ChatGPTが詳細に説明することはできないかもしれません。さらに、訓練データは多くの異なる分野から収集されていますが、それにもかかわらず、すべてのトピックについて完全に正確な情報を提供するわけではありません。特に科学、技術、法律といった高度に専門的な分野においては、具体的かつ詳細な情報が必要な場合、ChatGPTの知識範囲を超えてしまうことがあります。
また、ChatGPTは幅広い情報源から学習しているとはいえ、専門家のレベルの深い知識を持つわけではない点を理解することが重要です。多くの分野について基本的な理解と一般的な知識を提供することは可能ですが、特定の専門分野における最新の研究や高度な議論については、十分な情報を提供できない場合があります。
さらに、ChatGPTは「ハルシネーション」、つまり存在しない事実や情報を生成することがあります。この現象は、AIが確信を持って情報を提供できない時や、ユーザーからの具体的な情報に対する具体的な回答が必要な場合に特に見られます。そのため、重要な意思決定をする際には、必ず複数の情報源から情報を収集し、信頼できる専門家の意見を求めることが推奨されます。これらの制約を理解することで、ChatGPTをより適切に活用することが可能となります。
大規模言語モデルの不得意タスク
- 時系列情報の把握: LLMsはデータが訓練された時点の情報しか持っておらず、その後の時系列的な変化を自動的に把握する能力を持っていません。これは、リアルタイムの天候、株価などの最新情報について適切な回答をすることができないということを意味します。
- 特化した専門知識: LLMsは訓練データに基づく一般的な知識を持っていますが、特定の商用用途や特化した専門分野の知識を深く理解するのは難しいです。業界特有の専門用語やプロセス、規制などについて適切に反応できない場合があります。
- 現実世界での経験に基づく知識: LLMsは物理的な世界と直接的に相互作用する能力がなく、それゆえに物理的な実験や改良の提案について有用な回答を提供することが難しいです。
- 感情的なトーンの設定: LLMsは感情的なトーンを設定するタスク、例えばスピーチ作成やアプリケーションレター作成などにおいて、適切な形式性、創造性、ユーモラーといった「ソフトな」基準に基づいた感情的なトーンを設定することが難しいです。
- 情報の信頼性と公平性: LLMsが生成する情報には信頼性の問題があり、偏った情報を含むことがあります。また、誤った情報や虚偽の情報を含むこともあります。これは人物の評価に影響を及ぼす可能性がありますし、著作権を侵害する可能性もあります。
- 誤ったまたは偏った回答の生成: LLMsは一部の質問に対して正確な回答を提供することができますが、微妙またはあまり微妙でない方法で偏ったまたは誤った回答を生成することもあります。
以下に、これらの手法についての追加の説明と他の可能な対策を示します。
- プロンプトで必要な情報を与える: プロンプト設計は、言語モデルの結果に大きな影響を与えます。明確で具体的なプロンプトは、より良い結果を引き出す可能性があります。一方で、あいまいで広範なプロンプトは、予期しないまたは不適切な応答を引き出す可能性があります。
- Webの検索エンジンや社内データベースなどの外部の情報源からデータを取得: この方法は、言語モデルが持つ情報が最新のものではない、または特定のニッチなトピックに対する知識が不足している場合に特に有効です。
- ファインチューニングなどにより、モデルを調整: これは大規模言語モデルの振る舞いを調整するための一般的な方法で、特定のタスクやデータセットに対するモデルのパフォーマンスを向上させることが可能です。
生成AIには何ができるのか
ケイパビリティ
生成AIは、大量のデータセットを学習し、その結果としてテキスト、画像、音楽など新しいコンテンツを生成することができる人工知能の一種です。これらのシステムは、入力データのパターンと構造を学習し、その特性に基づいて新しい、創造的な出力を生成します。
生成AIの学習方法としては、「教師なし学習」または「自己教師付き学習」が一般的であり、使用されるデータセットの種類や形式により、その機能が決まります。生成AIは「ユニモーダル」システムと「マルチモーダル」システムの二つの形式を取り得ます。ユニモーダルシステムは一種類の入力のみを扱い、マルチモーダルシステムは複数種類の入力を扱うことができます。例えば、OpenAIのGPT-4の一部のバージョンは、テキストと画像の両方の入力を受け付けるマルチモーダルシステムです。
さまざまな生成AIシステムが存在し、その中にはOpenAIのGPT-3やGPT-4を利用したチャットボットのChatGPT、GoogleのLaMDA基盤モデルを使用して構築されたBardなどが含まれます。また、AIアートシステムのStable Diffusion、Midjourney、DALL-Eなども存在します。
生成AIは広範な業界での応用が見込まれており、その中にはアート、ライティング、ソフトウェア開発、ヘルスケア、金融、ゲーム、マーケティング、ファッションなどが含まれます。しかし、その一方で、フェイクニュースやディープフェイクの作成など、生成AIの悪用に関する懸念も存在します。
生成AIは人間の創造的プロセスを模倣し、人と協調する同志としての役割を果たす可能性があります。最も大きな可能性の一つは、人間の創造性を補完し、イノベーションを民主化することです。これにより、生成AIは単にタスクを自動化するだけでなく、人間の創造的な能力を増強し、新たなイノベーションを生み出す可能性を秘めています。
生成AIをどのように使うのか
生成AIの活用事例
「PwC Japanの2023年AI予測調査日本版」に基づくと、2023年に生成AIを活用しているまたはその予定がある日本企業は全体の54%に上る。これらの企業の中で生成AIの使用が特に顕著な分野は次のように分布している:
AI用学習データの生成: 62%
問い合わせ対応のチャットボット: 60%
ドキュメント作成の自動化: 55%
研究開発: 55%
しかし、この調査はまた、日本企業の生成AIの利用が、米国企業と比較して遅れていることも明らかにしている。この遅れの主な要因として、生成AIの利用に伴うリスクの認識に差があると考察されている。具体的には、生成AIの使用に何らかのリスクが存在すると評価する日本企業は90%にも上り、その中でも特に心配されているリスクは次の通りである:
品質の不安定性: 50%
高コスト: 47%
プロセスのブラックボックス化や責任の所在の不明確さ: 44%
なりすましやフェイクコンテンツ: 43%
さらに、生成AIの適用範囲について、日本企業は主にドキュメントの下書き、要約、情報収集の高度化、および問い合わせ対応に集中している。しかし、生成AIの可能性を考慮すると、専門知識やノウハウに基づいて意思決定や判断を支援するような活用が推奨されている。
Bing AI Chat
Bing AI Chatは、Microsoftが開発し、2023年2月にリリースしたAIベースの会話型チャットツールです。このツールはAI技術を使用してユーザーからの質問に答えたり、各種情報を収集、抽出することができます。Bing AI ChatとOpenAIのChatGPTとはいくつかの違いがあります。まず、Bing AI Chatはより基本的な自然言語処理(NLP)技術を使用しています。これに対してChatGPTはより高度なNLP技術を活用します。さらに、Bing AI Chatはより単純な会話を生成することが可能で、それに対してChatGPTはより複雑な会話の生成が可能です。
GitHub Copilot
GitHub Copilotは、AIによる自動コーディング支援ツールであり、GitHubとOpenAIが共同で開発したものです。GitHub Copilotは、コーディング中にAIがコードの提案をしてくれる機能を持っています。何かコードを書き始めるか、コードで何をしたいかを説明する自然言語のコメントを書くことで、GitHub Copilotがコードの提案をしてくれるようになります。
NotionAI
NotionAI は、タスクを自動化し、より高度なタスク管理を可能にするために Notion ワークスペース内で使用できる AI アシスタントです。文章の要約、翻訳、ライティング、アイデア創出などのタスクに使用できます。NotionAI は Notion の機能と統合されており、より高度な自動化が可能です。
Midjourney
MidjourneyはAIを活用した画像生成サービスで、高度なアルゴリズムを使用してユーザーのリクエストに基づいてリアルで鮮やかな画像を作成します。これにより、広告デザイン、Webデザイン、アート制作など、様々な領域でその活用が可能となります。サービスは個人から法人まで幅広いユーザーに向けて提供されています。このサービスはチャットサービスのDiscordを通じてアクセス可能で、ユーザーはテキストを入力することで希望のスタイルやテーマに合った画像を生成することができます。この柔軟性により、ユーザーは自分の具体的なニーズやビジョンに基づいたビジュアルを簡単に作成することができます。
Adobe Firefly
Adobe Fireflyは、Adobeが開発した生成AIツールで、クリエイターが自然言語で指示を与えることで画像やテキスト効果を生成できます。この新しいツールはクリエイティブプロセスを効率化し、クリエイターがコンテンツをより迅速かつ簡単に生成するのを助けることを目指しています。現在、Adobe Fireflyはプライベートベータ版として提供されており、Adobeは将来的にこのツールをAdobe Creative Cloudなどのクラウドサービスに統合する計画を持っています。この統合により、クリエイターはAdobeの他のクリエイティブツールと同様に、Fireflyを自分のワークフローに簡単に組み込むことができるでしょう。
生成AIの性能を拡張する使い方
プロンプトエンジニアリング
プロンプトエンジニアリングとは、AIに対する指示や命令(プロンプト)を最適化するための学問分野であり、大規模言語モデル(LLM)を効率的に利用するための一部となっています。この学問分野は、AIに対して明示的なタスクの説明を与えるのではなく、質問形式などで入力を組み込むことが可能にします。プロンプトエンジニアリングを機能させるためには、タスクをプロンプト(命令)に基づいたデータセットに変換し、「プロンプトベース学習」または「プロンプト学習」という手法で言語モデルを訓練する必要があります。
プロンプトエンジニアリングは、ChatGPTやNotionAIなどの自然言語処理(NLP)を必要とするAIに対して、適切な回答を得るための重要なプロセスです。このテクニックにより、AIとの協働がスムーズになり、業務効率が向上します。
基礎的なレベルでは、プロンプトエンジニアリングは対話型AI(例:ChatGPT)からユーザーが求める回答やアウトプットを得るための指示や命令の設計技術です。AIに与える指示や命令は通常の言語形式、例えば日本語となるため、これはエンジニア専門のスキルが必須ではないという特徴があります。
応用の面では、プロンプトエンジニアリングはChatGPTを用いた自動応答システム、自動要約システム、文章生成システム、自動翻訳システム、自動校正システム、自動分類システム、自動タグ付けシステム、自動要件定義システムなど、多くのシステム開発に活用されます。これらの応用には、より高度な技術や実践的なアプローチが求められます。
プロンプトエンジニアリングを学ぶための書籍やガイドも提供されており、初心者から上級者まで幅広く学ぶことができます。これは、ChatGPTなどの自然言語処理AIを効率的に活用し、業務効率化を実現するための重要な技術であり、AIとのコミュニケーションを円滑に進め、さらなる成果を引き出すことが可能です。
プロンプトエンジニアリングの役割は、AIのパフォーマンスを最大限に引き出し、効果的なプロンプトを検証・設計することで、AIとの協働をスムーズに進め、業務効率化を実現することです。大規模言語モデル(LLM)の利用において必要となるスキルであり、プロンプトエンジニアの役割と重要性が高まっています。
生成AIの新たな活用方法を生み出すためのアプローチ
ハッカソン
ハッカソンとは、"ハック"と"マラソン"を組み合わせた言葉で、一定期間、集中的にソフトウェアやサービスの開発を行い、その成果を競うイベントです。このイベントは通常、プログラマーやデザイナーなどの専門家が参加し、数日から数週間にわたって行われます。
ハッカソンの目的は新たなビジネスアイデアの創出や製品/サービスのプロトタイピングです。ハッカソンの中には生成AIを活用した開発を行うものもあります。生成AIを活用することで、新しいアイデアやユースケースを迅速にプロトタイプ化し、具現化することが可能です。
ハッカソンにおける主な手法として、ブレインストーミングやフューチャーセッションが取り入れられることがあります。これらの手法は新たなアイデアを生み出すためのもので、参加者全員が自由に意見やアイデアを出し合います。また、付箋を使ったワークショップなど、視覚的なツールを活用してアイデアを組織化し、開発の方向性を決定します。
生成AIを活用するハッカソンでは、以下のスキルや知識が必要となります。
- ビジネスの知識: ハッカソンでは、プロトタイプを作成する際に必要なビジネスの知識が求められます。これには、市場分析や戦略立案、製品開発などが含まれます。
- データサイエンスの知識: データサイエンスの知識を持つことで、データを効果的に解析し、AIモデルのトレーニングや最適化を行うことが可能です。
- AIの知識: AIの基礎的な理解はもちろんのこと、特定のAI技術やツール、フレームワークなどについての知識が必要となります。
- プログラミングのスキル: AIを活用するためには、プログラミングのスキルが必要です。PythonやJavaScriptなどのプログラミング言語に習熟していることが重要です。
- データ分析のスキル: データ分析のスキルを持つことで、AIを活用して得られる大量のデータを理解し、有用な情報を抽出することが可能になります。
これらのスキルや知識は、ハッカソンに参加することで磨くことができます。また、ハッカソンはチームで行われることが多く、他の参加者と協力しながら各々の専門知識を深める機会にもなります。
自主的なユースケース開発
個人でもAPIを活用することでシンプルなアプリケーショを作ることができます。Pythonの実装が未経験の場合でも、ノーコード開発ツールも登場しています。
インターネット・書籍、活用の探索
Qiitaやnoteなどサイトを活用して、生成AIの新たな活用方法に関する情報や事例を収集し、知識を深めることができます。
活用の探索
まずは自分の手で簡単なアプリを作ってみることから始めると良いでしょう。
生成AIの活用を制限する要因
生成AIの学習データ
学習データにない情報やデータが少ない場合、データセットの情報に偏りがある場合には、出力結果は不正確になる場合がああります。モデルの学習内容を把握し、適切なモデルを使用することが重要です。専門領域などの情報に対応するには、ファインチューニングなどの手段も検討するようにします。
生成AIの性能評価
生成AIの性能は様々な面から評価する必要があるため、一律に性能評価することは容易ではありません。
生成AIの言語能力
誤った回答や不正確な出力をすることがあります。また、専門知識に対しては十分に性能が発揮できない場合や、偏った回答を生成することがあります。最終的には、出力結果の判断は人間が行うことが重要です。
業界に特化した生成AIの活用方法
ChatGPT・Bard
- 農林水産省: ChatGPTは補助金申請マニュアルの改訂・修正に使用されています。つまり、GPTは法規制や手順を理解し、それを基に補助金申請者が理解しやすい形で情報を再構築します。
- 教育: 文部科学省は教室でのChatGPTの使用について議論中です。これは学生が質問をし、その質問に対して自動的に質の高い回答を提供するシステムを作り上げることが考えられます。
- 政府: デジタル庁は、ChatGPTを政府の業務目的で使用することを認めていますが、機密情報の取り扱いについては使用を禁じています。これは、AIの理解力と一般的な業務効率を向上させるための取り組みです。
- 事業内容: ChatGPTは、顧客対応システムの開発、製品名の生成、自動翻訳システムやチャットボットの開発など、様々なビジネス領域で活用されています。
- 法務: 法的文書の自動翻訳や契約書の生成にChatGPTを使用しています。これにより、高度な法的知識が必要な作業を自動化し、時間とコストを節約することが可能になります。
- マーケティング: 営業メールの自動化、Webサイトのコンテンツ生成、ニュースレターの生成、顧客の旅行マップの作成など、様々なマーケティング活動にChatGPTが利用されています。
- ヘルスケア: 医療関連の質問に回答するAIチャットボットの開発にChatGPTが使用されています。これにより、患者が疑問や不安を24時間365日いつでも質問できるようになります。
- 財務: ChatGPTは財務レポートの生成や販売レポートの作成を自動化するために使用されています。これにより、一貫した報告と迅速な分析が可能になります。
Google BardとChatGPTの主な用途の違い
GoogleBard:
- ウェブ上のコンテンツ情報を利用して、即時性の高い回答を提供する。
- 文章生成能力が高く、創造性と生産性を高めるパートナーとされる。
ChatGPT:
- 対話アプリケーション向けに設計され、様々な自然言語処理タスクを実行できるより汎用的なモデル。
- 回答のスピードが速く、より自然な会話を楽しんだり、人間が書いたに近い文章を作成することができます。
Google Bard は、ウェブ上の情報を利用して当面の高い回答を提供することができます。また、文章生成能力が高く、創造性と生産性を高めることができます。一方、ChatGPT は、対話アプリケーションに設計され、様々な自然言語処理タスクを実行できるより汎用的なモデルです。回答の速度が速く、より自然な会話を楽しんで、人間が書いたに近い文章を作成することができます。
広告クリエイティブへの応用
広告業界におけるAIの活用は多岐に渡ります。以下に詳細な使用例を解説します。
- クリエイティブ制作: AIを使用してターゲット視聴者に関するデータと洞察に基づいて画像やビデオなどの広告コンテンツを作成することができます。これにより、顧客が興味を持つ可能性が高いコンテンツを精度高く作成することが可能になります。
- マーケティングの最適化: AIは顧客の行動や好みに関するデータを分析し、広告のターゲティングと配信を最適化できます。これにより、広告効果を最大限に引き出すことが可能になります。
- オーディエンスのセグメンテーション: 人口統計や興味などのさまざまな基準に基づいてオーディエンスをセグメント化し、よりパーソナライズされた広告を配信することができます。これにより、広告はより関連性の高い内容となり、顧客エンゲージメントを高めることができます。
- 広告の効果測定: AIを使用して広告の効果を測定し、パフォーマンスを向上させるための調整を行うことができます。これはリアルタイムのフィードバックを提供し、より効果的なキャンペーン戦略を計画するための基礎を提供します。
- 広告作成: AIを使用してターゲット視聴者の共感を呼びやすい広告コピーや見出しを作成することが可能です。これにより、メッセージはよりパーソナライズされ、エンゲージメントが増加します。
- 広告の配置: AIを使用して広告の最適な配置を決定します。これにより、広告は最も効果的なチャネルとタイミングで配信されます。
具体的な企業の活用事例としては以下のようなものがあります。
- サイバーエージェント: 同社は「究極ヨソクAI」というAIツールを活用し、AIが生成したさまざまなモデルをフィーチャーした広告コンテンツを制作しています。このツールはクリックスルー率を122%改善することが証明されています。
- Google: GoogleはAIを使用して広告コンテンツと配信を最適化するさまざまな自動広告作成サービスを提供しています。これにより、広告主は広告キャンペーンの効果を最大化することができます。
- Media Radar: この会社は、SEO記事の作成、バイヤーペルソナの開発、競合他社の調査の実施などのタスクを支援できるChatGPTと呼ばれるAIを活用したチャットボットを提供しています。これにより、広告企業は効率的なマーケティング戦略を展開することが可能になります。
ドメイン固有
Med-PaLM 2
- 医療の質問応答に向けた改善された大規模言語モデル
- MedQAデータセットにおいて86.5%のスコアを達成し、オリジナルのMed-PaLMを19%以上上回る結果を出し、新たなパフォーマンスのベンチマークを確立した。
- Med-PaLM 2は、MedQA以外にも、MedMCQA、PubMedQA、MMLUといった他のデータセットにおいても、基礎となる大規模言語モデルの改良、医療領域の微調整、革新的なアンサンブル精緻化戦略などを用いて、同等または優れた結果を示した。
- 人間による評価では、様々な臨床的利便性の側面で千を超える医療問題について比較ランキングした結果、医師たちはMed-PaLM 2の回答を医師の回答よりも好むことが明らかになった。これは医療の質問応答における医師レベルのパフォーマンス達成への大きな進歩を示しているが、実世界でのさらなる検証が必要となる。
ChatDoctor
- 大規模言語モデル(LLMs)から微調整され、オンライン医療相談サイトからの100kの実際の患者と医師との会話を使用して、特に医療分野に適応されたものです。
- 従来のLLMsとは異なり、ChatDoctorはWikipediaや疾病データベースのようなリソースから自律的な知識検索能力を組み込んでいます。これにより、患者のニーズの理解が改善し、与えるアドバイスの精度が向上します。
- 著者たちはすべてのソースコード、データセット、モデルの重みを公開しており、これにより医療分野の対話モデルの開発がさらに進展することに貢献しています。
生成AIが、技術面・倫理面・法令面・社会面などで多様なリスクを孕むこと
正確性
出力結果が必ずしも正しいとは限らないことに注意します。個人情報などを含む出力結果を誤って使用することで名誉毀損につながる可能性や、医療に誤った情報により健康被害をもたらすリスクがあることにも注意が必要です。
ハルシネーション (Hallucination)
プロンプトに結果がわからない場合には分からないないと答えるように指示することで、ハルシネーション対策をすることができます。
セキュリティ
Large Language Model(LLM)を利用する際のセキュリティ対策は多岐に渡ります。特にプロンプト・インジェクション攻撃というリスクが存在します。これは、ユーザーからの不正な入力、つまり特殊文字や実行可能なコードが含まれたプロンプトを排除するためのフィルタリングやサニタイズ処理が必要となります。これらの処理により、悪意のあるコードやスクリプトを無害化し、システムの安全性を維持することが可能となります。
一方で、ユーザーが入力できるプロンプトを制限することも有効な対策となります。これはホワイトリスト方式と呼ばれ、許可されたプロンプトのみを入力可能とするものです。ただし、この方法はLLMの最大の魅力である体験の自由度を制限してしまう可能性があるため、注意が必要です。
また、システムの学習内容を制限することで、ユーザーに開示する情報の範囲を制御することが可能です。これにより、ユーザーのプライバシー保護や企業の機密情報保護に寄与します。例えば、電話番号やメールアドレスなどの個人情報をユーザーの入力から排除するバリデーションを行うなど、リスクを最小化する方法があります。
しかし、これらの対策にも関わらず、LLMの利用には情報漏洩のリスクが付きものです。特に、LLMに入力された情報がプラットフォーマーによって保持され、それが原因で情報漏洩が発生する可能性があるためです。また、LLMが他のユーザーの質問に対する回答として、その情報を誤って公開してしまうケースもあり得ます。
個人情報保護や企業機密の漏洩のリスクも重要な課題です。法的な観点からも、LLMを利用する際は個人情報や企業機密の扱いについて注意する必要があります。
加えて、LLMが出力する内容の適切性に関するリスクも存在します。不適切な言葉遣いや差別的な表現、煽動的な内容、個人情報の開示など、LLMの出力がユーザーや社会に悪影響を及ぼす可能性があります。これらのリスクを管理し、LLMをビジネスに適用する際は、その出力を適切に制御することが重要となります。
プロンプトインジェクション
プロンプトインジェクションとは、AIチャットボットの脆弱性を悪用して特定のコードやコマンドを実行させる攻撃手法の一つです。これは、ユーザーが入力フォームや検索バーなどに入力するデータを不正に操作し、開発者の意図しない動作を引き出すことを目的としています。具体的には、ChatGPTなどのAI/機械学習モデルに対して、悪意をもって指示(プロンプト)を送り込む行為を指します。それにより、ユーザーのチャットボットへの問いかけに対するレスポンスが盗まれたり、不適切な結果が出力されるリスクがあります。
この問題に対する対策方法はいくつかあります:
- プロンプトの制限: AIチャットボットのシステムにプロンプトの制限を設けることで、攻撃者が不正なプロンプトを入力することを防ぐことができます。具体的には、一部の危険な語彙やコマンドを制限するといった措置が考えられます。
- 入力データの検証: 入力フォームや検索バーなどに入力されるデータを事前に検証することで、不正なコードやコマンドを実行することを防ぐことができます。検証方法としては、正規表現や入力値のチェック、AIを使った自動検証などがあります。
- ログの収集: ログを集めることで、不正利用に迅速に気づいたり、サイバー攻撃が受けた後の証拠を残したり、具体的な手口に応じた対策を考えることができます。
- AIの監視: AIの動作を定期的に監視し、不正なプロンプトが入力された場合には、即座に対応することができます。
- セキュリティ意識の向上: プロンプトインジェクション対策は、セキュリティ意識の高いコミュニティの存在によって強化されます。セキュリティに関する情報や知見を共有し、常に最新の脅威と対策を学ぶことで、より効果的な対策が可能になります。
公平性
Large Language Model(LLM)の活用に際しては、公平性の観点から重要な考慮事項がいくつか存在します。まず一つ目は、データセットの偏りの問題です。例えば、特定の人種や性別に偏ったデータセットを使用すると、その偏りがモデルの結果に反映される可能性があります。これは、モデルが全体的に公平な結果を出すために、データセットが全体的に多様であることを意味します。
次に、個人情報の保護も重要な問題となります。LLMの訓練に用いられるデータセットには、場合によっては個人情報が含まれることがあります。このような情報を適切に保護するための対策が必要となります。これは、個々のデータ主体のプライバシーを尊重し、同時にデータ使用の法的な要件を満たすことを意味します。
そして最後に、AIの責任問題です。AIが誤った結果を出した場合や、AIが自己指示型学習や拡散生成モデルなどを用いて自己生成したデータを学習した場合、その結果に対する責任はどのように分配されるべきかという問題があります。これは、AIが生成した情報に対する責任を明確にすることで、ユーザーや利害関係者がAIの利用に対して信頼感を持てるようにすることを意味します。
これらの要素を考慮に入れることで、LLMを公平で透明な方法で使用し、その結果に対する信頼性を向上させることができます。
プライバシー
データプライバシーの保護が求められます。これには、モデルの訓練に使用されるデータだけでなく、モデルが生成するデータの保護も含まれます。個人データを保護するためのポリシーと手順を整備することが重要です。
また、セキュリティ対策が必要です。LLMシステムへの不正なアクセスを防ぐための対策を講じることが求められます。これには、アクセス制御、暗号化、監視などの手段が考えられます。
透明性
データ収集について考慮する必要があります。LLMはインターネットを含む様々な源からデータを収集しますが、その過程は必ずしも透明であるとは限らず、また明確な許可が得られているわけでもありません。データ収集の合法性と倫理性を考え、透明で許可された形で行われるようにすることが重要です。
次に、訓練データの透明性も問題となります。LLMが訓練に使用するデータが、透明で許可された方法で収集されたものであるかどうか確認することが大切です。
さらに、LLMの解釈可能性、すなわち「説明可能性」についても重視すべきです。LLMはその動作や意思決定プロセスを解釈・説明することが難しいことがあります。したがって、LLMの設計は説明可能であることが求められ、またその意思決定プロセスは透明であるべきです。
また、LLMを使用する際には、透明性を求める法令遵守も求められます。例えば、日本の「AI規制法」にはAIの使用についての開示を求める「透明性の義務」が含まれています。適用される可能性のあるすべての規制について認識し、法令遵守を確保することが重要です。
さらに、LLMの透明性と倫理性を確保するためのガバナンス枠組みを設立することも重要です。これには、データ収集、訓練、意思決定についての方針と手続きを確立することが含まれます。
最後に、LLMの使用に際してのコミュニケーションが重要となります。LLMの使用や意思決定プロセスについて明確かつオープンにコミュニケーションを行うことが大切です。これには、LLMがどのように使用され、意思決定がどのように行われているのかを、顧客や従業員などのステークホルダーに対して伝えることが含まれます。
生成AIの入力(データ)と出力(生成物)について注意すべき事項
著作権
著作権法は作成者の知的な労働を保護するための法律であり、それにより作成者は自分の作品を複製、公開、改変するなどの権利を有しています。そのため、LLM(Language Learning Model)のようなAI技術を使用する際には、著作権の観点から注意すべきいくつかの点があります。
- 他者の著作物をLLMに入力する場合の問題:LLMに他者の著作物を入力し、それに基づく結果を出力する行為は、著作権法における「複製」に該当する可能性があります。ただし、著作権法には「情報解析」や「非享受利用」など一定の例外的な状況が存在し、その範囲内であれば著作権侵害とはなりません。それでも、他者の著作物をランダムに入力して結果を得ると、その結果が元の著作物と同一又は類似する可能性があり、それが第三者に利用されると著作権侵害を助長する可能性があります。そのため、無闇に他者の著作物を入力するのは避けるべきです。
- 他者の著作物がLLMから出力される場合の問題:LLMの出力が他者の著作物(全体や一部)であったり、二次的著作物(翻訳や要約など)である場合、これは著作権侵害のリスクが高いです。これは、著作権者が有する「翻案権」を侵害する可能性があるからです。出力が他者の著作物である場合、AIの提供者は他者の著作物を送信可能化することにより著作権侵害になり得ます。また、ユーザーも、出力された他者の著作物を知っていてそれを利用すると、同様に著作権侵害となります。
個人情報
個人情報保護委員会による生成AIサービスの利用に関する注意喚起等について(令和5年6月2日)
- 個人情報取扱事業者: 事業者がAIサービスに個人情報を含むプロンプトを入力する場合、その利用は特定された目的の達成に必要な範囲内であることを確認する必要があります。また、事前に本人の同意を得ずに個人データを入力し、そのデータが出力以外の目的で使用される場合、個人情報保護法に違反する可能性があります。したがって、AIサービス提供者が個人データを機械学習に使用しないことを確認する必要があります。
- 行政機関: 行政機関がAIサービスに個人情報を含むプロンプトを入力する場合も、その利用は特定された目的を達成するための最小限度でなければなりません。また、保有個人情報が出力以外の目的で利用される場合、個人情報保護法に違反する可能性があります。したがって、AIサービス提供者が保有個人情報を機械学習に使用しないことを確認する必要があります。
- 一般の利用者: AIサービスでは、入力された個人情報が機械学習に使用され、その結果他の情報と結びつけられる可能性があります。このことは、AIサービスから出力される情報が不正確である可能性を示します。したがって、利用者はAIサービスに個人情報を入力する際には、これらのリスクを踏まえた判断を行う必要があります。また、AIサービス提供者の利用規約やプライバシーポリシーを十分に確認し、入力する情報の内容を考慮に入れてAIサービスの利用について適切に判断することが求められます。
機密情報
大規模言語モデル(Large Language Models、LLM)を活用する際の機密情報の管理について考察すると、その中心には契約義務の順守、プライバシー義務、知的財産権のリスク管理、そしてこれらのリスクを軽減するための戦略が存在します。
まず、契約義務については、特に秘密保持が注目されます。ユーザーがLLMに入力するデータが顧客や第三者から取得した情報を含む場合、その情報の使用が契約義務を違反する可能性があります。そのため、機密情報または個人情報をLLMに入力する際には、その情報の出所と、その情報の使用または共有がデータのLLMでの使用と矛盾する契約が存在しないかを慎重に確認する必要があります。
次に、プライバシー義務については、個人データや顧客データをLLMに入力するユーザーが対象となります。使用される情報が対象となる任意のプライバシー法にどのように影響を及ぼすかを理解し、その使用がプライバシーポリシーに適合していることを確認する必要があります。必要に応じて、プライバシーポリシーを更新し、LLMの使用と情報開示の情報源として特定したり、ユーザーに対して削除やオプトアウトの権利を提供したりすることも重要です。
また、知的財産権のリスクについても考慮する必要があります。LLMで生成されたドキュメントやコードが法的保護に値するかどうかは、複雑で未解決の問題であることが多いです。さらに、LLMが生成した作品が元の著作物から派生したものであると見なされ、元の著作物を侵害しているとみなされる可能性もあります。専有的な情報や営業秘密をLLMに入力すると、その情報の開示や保護に関する問題が生じる可能性もあります。
商用利用
大規模言語モデル(LLM)の商用利用を考える際、以下の点に注目することが重要です。
- オープンソースかどうか:モデルがオープンソースであるか否かは、その利用可能性に大きく影響します。オープンソースであれば、そのソースコードを誰でも利用、改変、再配布できます。
- 商用利用の許可:しかし、オープンソースでも商用利用が許可されているとは限りません。利用する前に、モデルのライセンスを確認し、商用利用が許可されているかを必ず確認してください。
- 特定のライセンス:モデルには、その使用を規定するライセンスが付与されます。Apache 2.0ライセンスやMITライセンスのようなライセンスでは、モデルの商用利用、改変、再配布が可能です。しかし、それぞれのライセンスには独自の制限や義務があり、それらを理解し遵守することが求められます。
- 学習済みモデルとソースコードのライセンス:一部のモデルでは、ソースコードと学習済みモデル(またはその学習データ)のライセンスが異なることがあります。たとえば、ソースコードは商用利用可でも、学習済みモデルは商用利用不可というケースもあります。そのような場合、自分でデータセットを用意し、新たにモデルを学習させる必要があります。
- ライセンス情報の確認方法:GitHub等で公開されているソースコードには、通常、ライセンス情報が明記されています。図のようにリポジトリ内のライセンス名を確認し、ライセンスファイルを参照することで、モデルの利用条件を把握できます。
- 注意すべき点:ライセンスの遵守は、商用利用において極めて重要です。特に、ソースコードと学習済みモデルや学習データのライセンスが異なる場合には注意が必要です。そのようなケースでは、すべてのライセンスを確認し、その条項をすべて満たしていることを確認する必要があります。
利用規約
AIサービスを使用する際、利用規約の理解と順守は極めて重要な課題となります。その背景には、AIの成果物に対する著作権、商用利用の可否、データ保護など、法的な観点から把握するべき要素が多数存在しているためです。
特に、ビジネスの文脈でAIサービスを利用する場合、そのサービスが商用利用を許可しているかどうかは大きなポイントとなります。商用利用の可否は利用規約等によって規定されています。この情報は、サービスを提供しているプラットフォーマーのウェブサイト等で閲覧可能でしょう。OpenAIのような大手プラットフォーマーでは、その利用規約により、ユーザーがサービスのアウトプットを商用利用可能と明示していることがあります。
しかし、商用利用の可否だけでなく、サービスの利用規約その他の規程に記載されている他の重要な条件や制限も十分に理解しましょう。それらは、サービスの使用をどのように制限するか、またはユーザーがどのような義務を負うかを定めています。
例えば、OpenAIの利用規約では、サービスから生成されたコンテンツの知的財産権は全てユーザーに帰属し、商用利用を含め任意の目的で利用可能であると明示されています。これにより、ユーザーはOpenAIが提供するサービス、例えばChatGPTをビジネスの目的で利用することが可能になります。
ただし、このような一般的なガイドラインに加えて、利用規約はプラットフォームや地域、時期によって変わることもあります。したがって、各プラットフォームの最新の利用規約を確認し、必要に応じて専門家の助けを借りることが必要です。
生成AIについて、現時点では認識されていない新たなリスクの出現とそれに伴う規制化の可能性
新たなリスク
生成AIと大規模言語モデル(LLM)に関連するリスクを以下に詳述します。
1. セキュリティリスク
生成AIとLLMは、大量のデータを使用して訓練されます。これらのデータが外部に漏洩した場合、個人情報や企業秘密が危険にさらされる可能性があります。これらのシステムは、個人のユーザー情報や感応性のあるビジネス情報にアクセスすることが可能で、これらの情報が悪意のある第三者に利用されると、重大な結果をもたらす可能性があります。そのため、生成AIとLLMの訓練と運用には、厳重なセキュリティ対策が必要です。
2. 著作権問題
生成AIとLLMは訓練に使用されたデータに基づいて新しいコンテンツを生成します。訓練データが著作権によって保護されている場合、これは著作権侵害のリスクを生じさせます。例えば、著作権で保護されたイラストレーターの作品がAIの訓練データとして無許可で使用され、そのスタイルを模倣するAIが生成される事例が報告されています。
さらに、生成AIの出力自体に対する著作権保護の問題も存在します。AIが自動生成した作品に対する著作権法の適用範囲はまだ確立されていませんが、人間の大きな投入が証明できる場合には著作権保護が適用される可能性があります。
3. 誤った情報の生成
生成AIとLLMは訓練データに基づいて情報を生成します。したがって、訓練データに誤った情報が含まれている場合、その誤りが出力に反映される可能性があります。これにより、ユーザーが間違った情報を受け取るリスクが生じます。また、生成AIによって作成された偽情報のブログや記事などが氾濫するリスクも懸念されています。
4. 倫理的問題
生成AIの使用には、その正確性、安全性、誠実性、エンパワーメント、持続可能性など、倫理的な側面が関わります。組織は使用するデータが最新で適切にラベル付けされていること、人間が意思決定プロセスに参加していること、そしてシステムが定期的にテストと再テストを受けていることを確認する必要があります。
5. 規制問題
生成AIの法的地位はまだ明確に定義されていません。これは、著作権法やデータプライバシー法など、生成AIが関与する可能性のある法律の多くがデジタル技術の急速な進歩を反映していないためです。これらのリスクを管理するためには、法制度の整備が求められます。
規制化
知的財産推進計画2023
日本政府が公表した「知的財産推進計画2023」は、知的財産の保護と活用に関する政策の新たな方向性を示すものです。この計画の特徴的な部分は、生成型AIとそれに関連する著作権侵害問題に焦点を当てている点です。目的は、知的財産の創出を奨励しながら、同時に生成型AI技術の利用を促進するための方策を探求することです。
この計画には、スタートアップや大学を対象とした知的財産エコシステムの強化も含まれています。これは、新しい技術やアイデアを生み出すことが期待されるこれらの機関が、知的財産権の保護と活用によって十分な報酬を得られる環境を整備することを目指しています。
政府は、この計画の策定にあたり活発な議論を行っており、生成型AIと著作権問題についての新たなガバナンスモデルの確立に向けた取り組みが進められています。このモデルが具体化されれば、AIが創造したコンテンツに対する著作権の扱いや、それに起因する著作権侵害の問題に対する新たな解決策が示される可能性があります。
学校現場での対話型AI「ChatGPT」の活用方法と注意点
文部科学省は、学校現場での対話型AI「ChatGPT」の活用方法と注意点をまとめる方針を決定しました。教育現場における新たなテクノロジーとしてのAI活用は、利益の追求と学生の育成の両方をバランス良く考慮することが重要であるとの視点から、ChatGPTをどのように適切に活用すべきかを示すガイドラインが考えられています。
ChatGPTの活用方法については、デジタルスキルの育成という観点での有効な利用方法が強調されています。それは、AIを活用したプログラムの学習や、自然言語処理の理解といった面で、生徒の学習経験を豊かにすることが期待されています。しかし、その一方で、AIを感想文の作成などに悪用しないための対策も必要とされています。生成系AIであるChatGPTが文章を自動生成する能力を誤用すると、学生自身の思考や表現の能力が育たないという懸念があるからです。
また、ChatGPTの利用に際しては、ただ単に有害な存在として排除するのではなく、どのようにして生徒たちが安全かつ効果的に活用できるかを理解し、指導することが求められています。これは、AIとデジタル技術がますます社会に浸透していく中で、それらを理解し、適切に使いこなす能力が重要であるという視点からです。
さらに、ChatGPTを活用する際には、生徒の年齢に応じた適切な指導や、著作権の遵守という法的な観点にも留意することが必要です。生徒の年齢によっては、ChatGPTの内容理解やその適切な使用方法を十分に理解できない可能性があります。また、ChatGPTが生成する内容についての著作権は、複製や再利用の際には適切な扱いが求められます。
情報収集
| AI戦略会議 | https://www8.cao.go.jp/cstp/ai/ai_senryaku/ai_senryaku.html |
| AI戦略チーム(関係省庁連携) | https://www8.cao.go.jp/cstp/ai/ai_team/ai_team.html |
| 一般社団法人 日本ディープラーニング協会 | https://www.jdla.org/ |
| 自民党AIの進化と実装に関するプロジェクトチーム | https://note.com/akihisa_shiozaki/n/n4c126c27fd3d |
生成AIの活用に伴うリスクを自主的に低減するための方法
自主対策
AI(人工知能)の活用には、確かに多くのリスクが存在します。その中でも代表的なものには、プライバシー侵害、不正確な予測、バイアスの増幅、セキュリティ問題、そしてAIによる自動化による雇用の影響などが挙げられます。これらのリスクを自主的に低減するための具体的な方法を以下に示します。
- プライバシー保護: AIシステムは大量のデータを必要とし、その中には個人情報が含まれることがあります。データを匿名化したり、個人を特定できないようにする技術(例えば、差分プライバシー)を用いることで、プライバシー侵害のリスクを低減することが可能です。
- 予測の精度向上: AIの予測が不正確な場合、重大な結果を招く可能性があります。そのため、AIのモデルを訓練する際には、バリデーションデータやテストデータを使ってモデルの性能を評価し、予測の精度を向上させる必要があります。また、異なるモデルやアプローチを組み合わせて予測のロバスト性を高めるアンサンブル学習も有効です。
- バイアスの除去: AIの訓練データがバイアスを含んでいると、AIの結果もバイアスが反映される可能性があります。バイアスを低減するためには、AIを訓練する際のデータセットが公正で多様性のあるものであることが重要です。また、AIのアルゴリズム自体を公正性を考慮したものにする手法(例えば、公平性を重視した機械学習)も開発されています。
- セキュリティ対策: AIシステムはサイバーセキュリティの攻撃を受ける可能性があります。そういったリスクを低減するためには、AIシステムのセキュリティ設定を適切に管理し、最新のセキュリティパッチを適用するなどの対策が必要です。また、AIシステム自体が不正な行動をとらないよう、その設計段階で適切な制約を設けることも大切です。
- 雇用への影響: AIによる自動化が進むと、一部の職種がなくなる可能性があります。このリスクを低減するためには、AIと人間が共存する社会の在り方を模索するとともに、職業訓練や教育の機会を提供し、新たなスキルやキャリアパスを開発することが重要です。
まとめ
最後までご覧いただきありがとうございました。
