このシリーズではE資格対策として、シラバスの内容を項目別にまとめています。
LSTM
ゲート付きRNNの概要
リカレントニューラルネットワーク(RNN)は、時系列データの処理に使用されるニューラルネットワークの一種です。時系列データを順番に処理し、過去の情報を現在の入力に組み合わせることで、シーケンス全体のパターンを捉えることができます。
しかし、基本的なRNNは、長いシーケンスを処理する際に勾配消失または勾配爆発の問題が生じることがあります。この問題を解決するために、ゲート付きRNNが開発されました。
ゲート付きRNNは、情報の流れを制御するための特別な構造を持っており、それを「ゲート」と呼びます。ゲートは、各時点でどの情報を記憶し、どの情報を忘れるかを学習します。これにより、シーケンスの中で重要な情報を選択的に記憶することが可能となります。
ゲート付きRNNの主要な2つのタイプは、LSTM(Long Short-Term Memory)とGRU(Gated Recurrent Unit)です。
LSTMの概要
LSTM(Long Short-Term Memory)は、リカレントニューラルネットワーク(RNN)の一種で、時系列データの処理に特化した構造を持っています。通常のRNNが長期の依存関係をうまく学習できない問題を解決するために開発されました。
LSTMの特徴的な部分は、ゲートと呼ばれる構造で、情報の流れを制御する役割を果たします。主に以下の3つのゲートから構成されます。
- 入力ゲート:新しい情報をどれだけセル状態に取り込むかを制御
- 忘却ゲート:古い情報をどれだけ忘れるかを制御
- 出力ゲート:セル状態からどれだけ情報を取り出すかを制御
これにより、LSTMは長期の依存関係をうまく捉えることができ、多様なタスクに適用されています。
LSTMの構造
LSTMの主要な構成要素は以下の通りです。
- セル状態(Cell State): セル状態は、ネットワークの"記憶"を保持する部分で、情報の長期的な流れを制御します。
- ゲート(Gate): ゲートは、情報の流れを選択的に制御する構造で、入力ゲート、忘却ゲート、出力ゲートの3つが存在します。
入力ゲート(Input Gate): 新しい情報をセル状態にどれだけ取り込むかを決定します。入力ゲートの計算は以下の数式で表されます。
忘却ゲート(Forget Gate): セル状態から古い情報をどれだけ忘れるかを決定します。数式で表すと以下のようになります。
出力ゲート(Output Gate): セル状態から取り出す情報の量を制御します。数式は以下の通りです。
セル状態の更新:
隠れ状態の計算:
LSTMの実装
LSTMの順伝播と逆伝播を実装しています。
class LSTM:
def __init__(self, Wx, Wh, b):
# LSTMのパラメータを初期化
self.params = [Wx, Wh, b] # 入力重み、隠れ状態の重み、バイアス
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)] # 各パラメータの勾配
self.cache = None # 順伝播時の中間値を保存するためのキャッシュ
def forward(self, x, h_prev, c_prev):
Wx, Wh, b = self.params # 重みとバイアスの取り出し
N, H = h_prev.shape # 前の隠れ状態の形状取得
# アフィン変換
A = np.dot(x, Wx) + np.dot(h_prev, Wh) + b
# ゲートの計算
f = A[:, :H] # 忘却ゲート
g = A[:, H:2*H] # セル候補
i = A[:, 2*H:3*H] # 入力ゲート
o = A[:, 3*H:] # 出力ゲート
# ゲートの活性化関数適用
f = sigmoid(f)
g = np.tanh(g)
i = sigmoid(i)
o = sigmoid(o)
# 次のセル状態と隠れ状態の計算
c_next = f * c_prev + g * i
h_next = o * np.tanh(c_next)
# 中間値の保存
self.cache = (x, h_prev, c_prev, i, f, g, o, c_next)
return h_next, c_next
def backward(self, dh_next, dc_next):
Wx, Wh, b = self.params
x, h_prev, c_prev, i, f, g, o, c_next = self.cache
tanh_c_next = np.tanh(c_next)
# セル状態の勾配計算
ds = dc_next + (dh_next * o) * (1 - tanh_c_next ** 2)
# 前のセル状態への勾配
dc_prev = ds * f
# 各ゲートの勾配計算
di = ds * g
df = ds * c_prev
do = dh_next * tanh_c_next
dg = ds * i
# シグモイドとtanhの勾配
di *= i * (1 - i)
df *= f * (1 - f)
do *= o * (1 - o)
dg *= (1 - g ** 2)
# 勾配の連結
dA = np.hstack((df, dg, di, do))
# 重みとバイアスの勾配
dWh = np.dot(h_prev.T, dA)
dWx = np.dot(x.T, dA)
db = dA.sum(axis=0)
# 勾配の保存
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
# 前の層への勾配
dx = np.dot(dA, Wx.T)
dh_prev = np.dot(dA, Wh.T)
return dx, dh_prev, dc_prev
LSTMの構造
このクラスは、時系列データの処理に適したLSTM層を実装しています。T個分の時系列データをまとめて処理します。
class TimeLSTM:
def __init__(self, Wx, Wh, b, stateful=False):
# LSTMのパラメータの初期化
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None # LSTM層のリスト
# 隠れ状態とセル状態
self.h, self.c = None, None
self.dh = None # 隠れ状態の勾配
self.stateful = stateful # 状態を保持するかどうか
def forward(self, xs):
Wx, Wh, b = self.params
N, T, D = xs.shape # 入力データの形状
H = Wh.shape[0]
self.layers = []
hs = np.empty((N, T, H), dtype='f') # 出力の格納
# 状態の初期化
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype='f')
if not self.stateful or self.c is None:
self.c = np.zeros((N, H), dtype='f')
# 時間方向にLSTMを適用
for t in range(T):
layer = LSTM(*self.params)
self.h, self.c = layer.forward(xs[:, t, :], self.h, self.c)
hs[:, t, :] = self.h
self.layers.append(layer)
return hs
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D = Wx.shape[0]
dxs = np.empty((N, T, D), dtype='f') # 勾配の格納
dh, dc = 0, 0
grads = [0, 0, 0]
# 時間方向に逆伝播
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh, dc = layer.backward(dhs[:, t, :] + dh, dc)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
# 勾配の更新
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h, c=None):
# 隠れ状態とセル状態の設定
self.h, self.c = h, c
def reset_state(self):
# 隠れ状態とセル状態のリセット
self.h, self.c = None, None
PTBデータセットによる学習
参考:https://github.com/oreilly-japan/deep-learning-from-scratch-2/tree/master
import numpy
import time
import matplotlib.pyplot as plt
import os
def eval_perplexity(model, corpus, batch_size=10, time_size=35):
print('evaluating perplexity ...')
corpus_size = len(corpus)
total_loss = 0
max_iters = (corpus_size - 1) // (batch_size * time_size)
jump = (corpus_size - 1) // batch_size
for iters in range(max_iters):
xs = np.zeros((batch_size, time_size), dtype=np.int32)
ts = np.zeros((batch_size, time_size), dtype=np.int32)
time_offset = iters * time_size
offsets = [time_offset + (i * jump) for i in range(batch_size)]
for t in range(time_size):
for i, offset in enumerate(offsets):
xs[i, t] = corpus[(offset + t) % corpus_size]
ts[i, t] = corpus[(offset + t + 1) % corpus_size]
try:
loss = model.forward(xs, ts, train_flg=False)
except TypeError:
loss = model.forward(xs, ts)
total_loss += loss
print('')
ppl = np.exp(total_loss / max_iters)
return ppl
def clip_grads(grads, max_norm):
total_norm = 0
for grad in grads:
total_norm += np.sum(grad ** 2)
total_norm = np.sqrt(total_norm)
rate = max_norm / (total_norm + 1e-6)
if rate < 1:
for grad in grads:
grad *= rate
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for i in range(len(params)):
params[i] -= self.lr * grads[i]
class LSTM:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev, c_prev):
Wx, Wh, b = self.params
N, H = h_prev.shape
A = np.dot(x, Wx) + np.dot(h_prev, Wh) + b
f = A[:, :H]
g = A[:, H:2*H]
i = A[:, 2*H:3*H]
o = A[:, 3*H:]
f = sigmoid(f)
g = np.tanh(g)
i = sigmoid(i)
o = sigmoid(o)
c_next = f * c_prev + g * i
h_next = o * np.tanh(c_next)
self.cache = (x, h_prev, c_prev, i, f, g, o, c_next)
return h_next, c_next
def backward(self, dh_next, dc_next):
Wx, Wh, b = self.params
x, h_prev, c_prev, i, f, g, o, c_next = self.cache
tanh_c_next = np.tanh(c_next)
ds = dc_next + (dh_next * o) * (1 - tanh_c_next ** 2)
dc_prev = ds * f
di = ds * g
df = ds * c_prev
do = dh_next * tanh_c_next
dg = ds * i
di *= i * (1 - i)
df *= f * (1 - f)
do *= o * (1 - o)
dg *= (1 - g ** 2)
dA = np.hstack((df, dg, di, do))
dWh = np.dot(h_prev.T, dA)
dWx = np.dot(x.T, dA)
db = dA.sum(axis=0)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
dx = np.dot(dA, Wx.T)
dh_prev = np.dot(dA, Wh.T)
return dx, dh_prev, dc_prev
class RnnlmTrainer:
def __init__(self, model, optimizer):
self.model = model
self.optimizer = optimizer
self.time_idx = None
self.ppl_list = None
self.eval_interval = None
self.current_epoch = 0
def get_batch(self, x, t, batch_size, time_size):
batch_x = np.empty((batch_size, time_size), dtype='i')
batch_t = np.empty((batch_size, time_size), dtype='i')
data_size = len(x)
jump = data_size // batch_size
offsets = [i * jump for i in range(batch_size)] # バッチの各サンプルの読み込み開始位置
for time in range(time_size):
for i, offset in enumerate(offsets):
batch_x[i, time] = x[(offset + self.time_idx) % data_size]
batch_t[i, time] = t[(offset + self.time_idx) % data_size]
self.time_idx += 1
return batch_x, batch_t
def fit(self, xs, ts, max_epoch=10, batch_size=20, time_size=35,
max_grad=None, eval_interval=20):
data_size = len(xs)
max_iters = data_size // (batch_size * time_size)
self.time_idx = 0
self.ppl_list = []
self.eval_interval = eval_interval
model, optimizer = self.model, self.optimizer
total_loss = 0
loss_count = 0
start_time = time.time()
for epoch in range(max_epoch):
for iters in range(max_iters):
batch_x, batch_t = self.get_batch(xs, ts, batch_size, time_size)
loss = model.forward(batch_x, batch_t)
model.backward()
params, grads = remove_duplicate(model.params, model.grads)
if max_grad is not None:
clip_grads(grads, max_grad)
optimizer.update(params, grads)
total_loss += loss
loss_count += 1
if (eval_interval is not None) and (iters % eval_interval) == 0:
ppl = np.exp(total_loss / loss_count)
elapsed_time = time.time() - start_time
print('| epoch %d | iter %d / %d | time %d[s] | perplexity %.2f'
% (self.current_epoch + 1, iters + 1, max_iters, elapsed_time, ppl))
self.ppl_list.append(float(ppl))
total_loss, loss_count = 0, 0
self.current_epoch += 1
def plot(self, ylim=None):
x = numpy.arange(len(self.ppl_list))
if ylim is not None:
plt.ylim(*ylim)
plt.plot(x, self.ppl_list, label='train')
plt.xlabel('iterations (x' + str(self.eval_interval) + ')')
plt.ylabel('perplexity')
plt.show()
def remove_duplicate(params, grads):
params, grads = params[:], grads[:]
while True:
find_flg = False
L = len(params)
for i in range(0, L - 1):
for j in range(i + 1, L):
if params[i] is params[j]:
grads[i] += grads[j]
find_flg = True
params.pop(j)
grads.pop(j)
elif params[i].ndim == 2 and params[j].ndim == 2 and \
params[i].T.shape == params[j].shape and np.all(params[i].T == params[j]):
grads[i] += grads[j].T
find_flg = True
params.pop(j)
grads.pop(j)
if find_flg: break
if find_flg: break
if not find_flg: break
return params, grads
try:
import urllib.request
except ImportError:
raise ImportError('Use Python3!')
import pickle
import numpy as np
url_base = 'https://raw.githubusercontent.com/tomsercu/lstm/master/data/'
key_file = {
'train':'ptb.train.txt',
'test':'ptb.test.txt',
'valid':'ptb.valid.txt'
}
save_file = {
'train':'ptb.train.npy',
'test':'ptb.test.npy',
'valid':'ptb.valid.npy'
}
vocab_file = 'ptb.vocab.pkl'
dataset_dir = os.getcwd()
def _download(file_name):
file_path = dataset_dir + '/' + file_name
if os.path.exists(file_path):
return
print('Downloading ' + file_name + ' ... ')
try:
urllib.request.urlretrieve(url_base + file_name, file_path)
except urllib.error.URLError:
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
urllib.request.urlretrieve(url_base + file_name, file_path)
print('Done')
def load_vocab():
vocab_path = dataset_dir + '/' + vocab_file
if os.path.exists(vocab_path):
with open(vocab_path, 'rb') as f:
word_to_id, id_to_word = pickle.load(f)
return word_to_id, id_to_word
word_to_id = {}
id_to_word = {}
data_type = 'train'
file_name = key_file[data_type]
file_path = dataset_dir + '/' + file_name
_download(file_name)
words = open(file_path).read().replace('\n', '<eos>').strip().split()
for i, word in enumerate(words):
if word not in word_to_id:
tmp_id = len(word_to_id)
word_to_id[word] = tmp_id
id_to_word[tmp_id] = word
with open(vocab_path, 'wb') as f:
pickle.dump((word_to_id, id_to_word), f)
return word_to_id, id_to_word
def load_data(data_type='train'):
if data_type == 'val': data_type = 'valid'
save_path = dataset_dir + '/' + save_file[data_type]
word_to_id, id_to_word = load_vocab()
if os.path.exists(save_path):
corpus = np.load(save_path)
return corpus, word_to_id, id_to_word
file_name = key_file[data_type]
file_path = dataset_dir + '/' + file_name
_download(file_name)
words = open(file_path).read().replace('\n', '<eos>').strip().split()
corpus = np.array([word_to_id[w] for w in words])
np.save(save_path, corpus)
return corpus, word_to_id, id_to_word
class BaseModel:
def __init__(self):
self.params, self.grads = None, None
def forward(self, *args):
raise NotImplementedError
def backward(self, *args):
raise NotImplementedError
def save_params(self, file_name=None):
if file_name is None:
file_name = self.__class__.__name__ + '.pkl'
params = [p.astype(np.float16) for p in self.params]
if GPU:
params = [to_cpu(p) for p in params]
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name=None):
if file_name is None:
file_name = self.__class__.__name__ + '.pkl'
if '/' in file_name:
file_name = file_name.replace('/', os.sep)
if not os.path.exists(file_name):
raise IOError('No file: ' + file_name)
with open(file_name, 'rb') as f:
params = pickle.load(f)
params = [p.astype('f') for p in params]
if GPU:
params = [to_gpu(p) for p in params]
for i, param in enumerate(self.params):
param[...] = params[i]
class Rnnlm:
def __init__(self, vocab_size=10000, wordvec_size=100, hidden_size=100):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.layers = [
TimeEmbedding(embed_W),
TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True),
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layer = self.layers[1]
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs):
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts):
score = self.predict(xs)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
self.lstm_layer.reset_state()
class TimeEmbedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.layers = None
self.W = W
def forward(self, xs):
N, T = xs.shape
V, D = self.W.shape
out = np.empty((N, T, D), dtype='f')
self.layers = []
for t in range(T):
layer = Embedding(self.W)
out[:, t, :] = layer.forward(xs[:, t])
self.layers.append(layer)
return out
def backward(self, dout):
N, T, D = dout.shape
grad = 0
for t in range(T):
layer = self.layers[t]
layer.backward(dout[:, t, :])
grad += layer.grads[0]
self.grads[0][...] = grad
return None
class TimeLSTM:
def __init__(self, Wx, Wh, b, stateful=False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None
self.h, self.c = None, None
self.dh = None
self.stateful = stateful
def forward(self, xs):
Wx, Wh, b = self.params
N, T, D = xs.shape
H = Wh.shape[0]
self.layers = []
hs = np.empty((N, T, H), dtype='f')
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype='f')
if not self.stateful or self.c is None:
self.c = np.zeros((N, H), dtype='f')
for t in range(T):
layer = LSTM(*self.params)
self.h, self.c = layer.forward(xs[:, t, :], self.h, self.c)
hs[:, t, :] = self.h
self.layers.append(layer)
return hs
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D = Wx.shape[0]
dxs = np.empty((N, T, D), dtype='f')
dh, dc = 0, 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh, dc = layer.backward(dhs[:, t, :] + dh, dc)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h, c=None):
self.h, self.c = h, c
def reset_state(self):
self.h, self.c = None, None
class TimeAffine:
def __init__(self, W, b):
self.params = [W, b]
self.grads = [np.zeros_like(W), np.zeros_like(b)]
self.x = None
def forward(self, x):
N, T, D = x.shape
W, b = self.params
rx = x.reshape(N*T, -1)
out = np.dot(rx, W) + b
self.x = x
return out.reshape(N, T, -1)
def backward(self, dout):
x = self.x
N, T, D = x.shape
W, b = self.params
dout = dout.reshape(N*T, -1)
rx = x.reshape(N*T, -1)
db = np.sum(dout, axis=0)
dW = np.dot(rx.T, dout)
dx = np.dot(dout, W.T)
dx = dx.reshape(*x.shape)
self.grads[0][...] = dW
self.grads[1][...] = db
return dx
class TimeSoftmaxWithLoss:
def __init__(self):
self.params, self.grads = [], []
self.cache = None
self.ignore_label = -1
def forward(self, xs, ts):
N, T, V = xs.shape
if ts.ndim == 3:
ts = ts.argmax(axis=2)
mask = (ts != self.ignore_label)
xs = xs.reshape(N * T, V)
ts = ts.reshape(N * T)
mask = mask.reshape(N * T)
ys = softmax(xs)
ls = np.log(ys[np.arange(N * T), ts])
ls *= mask
loss = -np.sum(ls)
loss /= mask.sum()
self.cache = (ts, ys, mask, (N, T, V))
return loss
def backward(self, dout=1):
ts, ys, mask, (N, T, V) = self.cache
dx = ys
dx[np.arange(N * T), ts] -= 1
dx *= dout
dx /= mask.sum()
dx *= mask[:, np.newaxis]
dx = dx.reshape((N, T, V))
return dx
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
if GPU:
np.scatter_add(dW, self.idx, dout)
else:
np.add.at(dW, self.idx, dout)
return None
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def softmax(x):
if x.ndim == 2:
x = x - x.max(axis=1, keepdims=True)
x = np.exp(x)
x /= x.sum(axis=1, keepdims=True)
elif x.ndim == 1:
x = x - np.max(x)
x = np.exp(x) / np.sum(np.exp(x))
return x
GPU = False
if GPU:
import cupy as np
np.cuda.set_allocator(np.cuda.MemoryPool().malloc)
print('\033[92m' + '-' * 60 + '\033[0m')
print(' ' * 23 + '\033[92mGPU Mode (cupy)\033[0m')
print('\033[92m' + '-' * 60 + '\033[0m\n')
else:
import numpy as np
batch_size = 20
wordvec_size = 100
hidden_size = 100
time_size = 35
lr = 20.0
max_epoch = 4
max_grad = 0.25
corpus, word_to_id, id_to_word = load_data('train')
corpus_test, _, _ = load_data('test')
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]
model = Rnnlm(vocab_size, wordvec_size, hidden_size)
optimizer = SGD(lr)
trainer = RnnlmTrainer(model, optimizer)
trainer.fit(xs, ts, max_epoch, batch_size, time_size, max_grad,
eval_interval=20)
trainer.plot(ylim=(0, 500))
model.reset_state()
ppl_test = eval_perplexity(model, corpus_test)
print('test perplexity: ', ppl_test)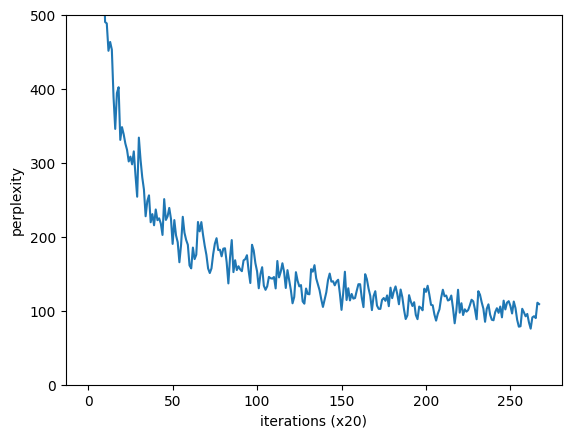
まとめ
最後までご覧いただきありがとうございました。

