今回は2022年9月に公開された、音声認識モデルである「Whisper」を実装する方法を紹介します。
基本的な操作から、YouTube動画の文字起こしまでを実装してみましょう。
Google colabを使用して簡単に実装することができますので、ぜひ最後までご覧ください。
Google Colaboの使い方はこちら
今回の目標
・Whisperとは
・Whisperの実装方法(チュートリアル)
・WhisperによるYouTube動画の文字起こし
(最新版はこちら)
【音声認識2023】音声からテキストへ変換する「Faster Whisper」でYouTube動画の文字起こしを実装する
今回はOpenAI の Whisper モデルを再実装した高速音声認識モデルである「Faster Whisper」を実装する方法を紹介します。 基本的な操作から、YouTube動画の文字起こしまで…

Whisperとは
概要
「Whisper」は2022年9月にOpenAIが発表した、音声認識モデルです。
インターネット上から収集された合計68万時間におよぶ音声データでトレーニングされており、認識した音声をもとに文字起こしをすることができます。
つまり、例えば「.mp3」などの音声ファイルから文字起こしをして、テキストに保存することができます。
また、これらはMITラインセンスとなっており、誰でも無料で簡単に使用することが可能です。
OpenAIの公式ブログ記事には「早口のセールストーク」「K-POPの曲」「フランス語」「独特なアクセントの会話」といった音声のサンプルが用意されており、「REVEAL TRANSCRIPT」をクリックするとWhisperで文字起こした結果を確認できます。
このモデルは多様な音声の大規模なデータセットでトレーニングされており、多言語の音声認識、音声翻訳、言語識別を実行できるマルチタスク モデルでもあります。
日本語にも対応しているため、日本語のまま使用することができます。
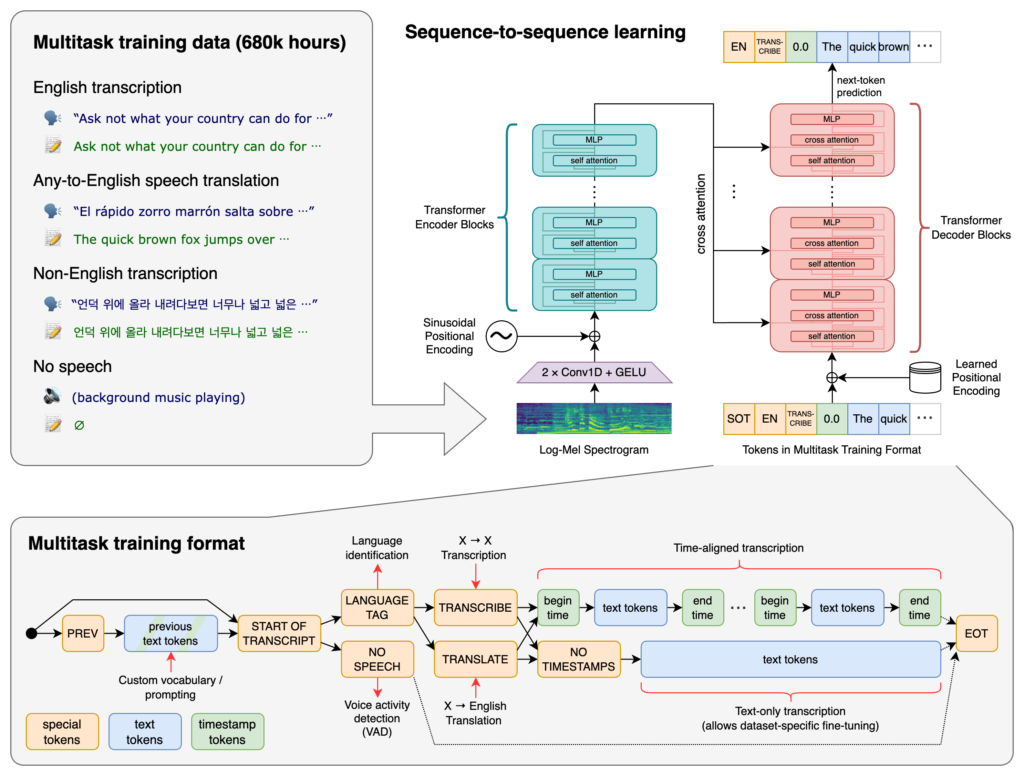
詳細はリンク先からご確認ください。
Github:https://github.com/openai/whisper
論文: https://cdn.openai.com/papers/whisper.pdf
公式サイト:https://openai.com/blog/whisper
モデル
公開されているモデルにはいくつか種類があります。
多言語モデルは日本語にも対応しています。
| モデルサイズ | パラメータ数 | 英語専用 モデル | 多言語モデル | 必要なVRAM | 相対速度 |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1GB | ~32x |
| base | 74M | base.en | base | ~1GB | ~16x |
| small | 244M | small.en | small | ~2GB | ~6x |
| medium | 769M | medium.en | medium | ~5GB | ~2x |
| large | 1550 M | なし | large | ~10GB | 1x |
サンプルコードの実装
まずは公式のページにあるサンプルコードによる、文字起こしを実装してみましょう。
今回紹介するコードは以下のリンクからもご覧いただけます。
![]()
準備
ここからは、Google colab環境で進めていきます。
はじめに、GPUを使用できるように設定をします。
「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をGPUに変更
設定が終わったら、まずはgoogleドライブをマウントします。
from google.colab import drive
drive.mount('/content/drive')
%cd '/content/drive/My Drive/'次に公式からクローンします。
!git clone https://github.com/openai/whisper
%cd whisper必要なライブラリをインストールします。
!pip install -r requirements.txt以上で準備が完了しました。
実装
まずは音声データを用意します。
今回はこちらの楽曲をお借りして、文字起こしを行ってみましょう。
まずは入力する音声データファイルと出力するテキストファイルを指定します。
ここでは、先程の楽曲を「sample.mp3」として、アップしました。
import whisper
input_file = "sample.mp3"
output_file = "result.txt"次にモデルのタイプを指定します。
今回は標準的な「base」を使用します。
model = whisper.load_model("base")あとは、以下のとおり実行しましょう。
なお、サンプルコードでは30秒までの音声を出力する事ができます。
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio(input_file)
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# save text
txt_path = output_file
with open(txt_path,mode='w') as f:
f.write(result.text)
# print the recognized text
print(result.text)実行すると、以下のような結果が出力されます。
星が変えるこの日は僕ら二人だけさんきっと優しい雨のような光が降る君と片も並べて寂しくはないこんなさても繋いで終わりの空を見よう音声ファイルから文字起こしをすることができました。
通常の会話のような音声だけでなく、楽曲の場合でも使用することができることがわかります。
YouTube動画から文字起こし
次に、YouTube動画から文字起こしを実装してみましょう。
まずは、YouTube動画を音声ファイルに変更した後、さきほど同様に文字起こしを行います。
なお、今回は筆者のYouTube動画の中で唯一音声が入っている、以下の動画で文字起こしを行います。
YouTube動画→音声ファイル
YouTube動画を変換するライブラリとして、「yt-dlp」があります。
このライブラリの詳細は、こちらの記事で紹介しておりますので合わせてご覧下さい。
【Python活用】「yt-dlp」を使ってYouTube動画や音楽をダウンロードする
このシリーズでは、Pythonの様々な活用の方法を紹介しています。 今回は、PythonでYouTube動画を簡単にダウンロードする方法を紹介します。 Google colabを使用して簡単に…

まずは「yt-dlp」をインストールします。
# YouTubeからファイルをダウンロードするライブラリをインストール
!python -m pip install -U yt-dlpYouTube動画から音声ファイルへの変換します。
引数には変換したい動画と、出力する音声ファイル名を指定します。
# YouTube動画から音声ファイルをダウンロード
# 「https://youtu.be/5wEtefq9VzM」という動画から「input.mp3」を出力する
!yt-dlp -x --audio-format mp3 https://youtu.be/5wEtefq9VzM -o "input.mp3"音声ファイルから文字起こし
あとはサンプルコードと同様に実装します。
import whisper
input_file = "input.mp3"
output_file = "result_yt.txt"
model = whisper.load_model("base")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio(input_file)
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# save text
txt_path = output_file
with open(txt_path,mode='w') as f:
f.write(result.text)
# print the recognized text
print(result.text)実行すると、以下のような結果が出力されます。
画像処理の機械学習のドイヤム1つである 超解像について初心者向けに紹介します 今回は2021年で発表されたリアルESRガムの公式チュートリアルに沿って 実装する方法を紹介したいと思います実際に改造度の低い画像を公開像の 化しています超解像ツーパーリストリューションとは 画像には動画の改造度を美術的に今回の動画の音声はボイスメーカーによる合成音声ですが、概ね文字起こしができていることがわかります。
YouTube動画から文字起こし(実用編)
最後に、ループ処理を加えて、時間制限なしで実行できるようにしたものを紹介します。
このままでコピーして使用すれば、簡単にYouTubeから文字起こしができるようになります。
from google.colab import drive
drive.mount('/content/drive')
%cd '/content/drive/My Drive/'
#!git clone https://github.com/openai/whisper
%cd whisper
!pip install -r requirements.txt
!python -m pip install -U yt-dlp!yt-dlp -x --audio-format mp3 https://youtu.be/5wEtefq9VzM -o "input2.mp3"
import whisper
input_file = "input2.mp3"
output_file = "result_yt_all.txt"
model = whisper.load_model("base")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio(input_file)
outputTextsArr = []
while audio.size > 0:
tirmedAudio = whisper.pad_or_trim(audio)
# trimedArray.append(tirmedAudio)
startIdx = tirmedAudio.size
audio = audio[startIdx:]
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(tirmedAudio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
# print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
outputTextsArr.append(result.text)
outputTexts = ' '.join(outputTextsArr)
print(outputTexts)
# Write into a text file
with open(output_file, "w") as f:
f.write(outputTexts)YouTube動画からの文字起こしが簡単にできるようになりました。
まとめ
最後までご覧いただき、ありがとうございました。
今回は2022年9月に公開された、音声認識モデルである「Whisper」を実装する方法を紹介しました。
YouTube動画の文字起こしによる字幕作成の自動化をはじめ、議事録の作成など業務においても、活用が期待できそうです。

