今回はOpenAI の Whisper モデルを再実装した高速音声認識モデルである「Faster Whisper」を実装する方法を紹介します。
基本的な操作から、YouTube動画の文字起こしまでを実装してみましょう。
Google colabを使用して簡単に実装することができますので、ぜひ最後までご覧ください。
Google Colaboの使い方はこちら
※最新モデルはこちら
今回の目標
・Faster Whisperとは
・Faster Whisperの実装方法(チュートリアル)
・Faster WhisperによるYouTube動画の文字起こし
Whisperとは
「Whisper」は2022年9月にOpenAIが発表した、音声認識モデルです。
インターネット上から収集された合計68万時間におよぶ音声データでトレーニングされており、認識した音声をもとに文字起こしをすることができます。
つまり、例えば「.mp3」などの音声ファイルから文字起こしをして、テキストに保存することができます。
また、これらはMITラインセンスとなっており、誰でも無料で簡単に使用することが可能です。
OpenAIの公式ブログ記事には「早口のセールストーク」「K-POPの曲」「フランス語」「独特なアクセントの会話」といった音声のサンプルが用意されており、「REVEAL TRANSCRIPT」をクリックするとWhisperで文字起こした結果を確認できます。
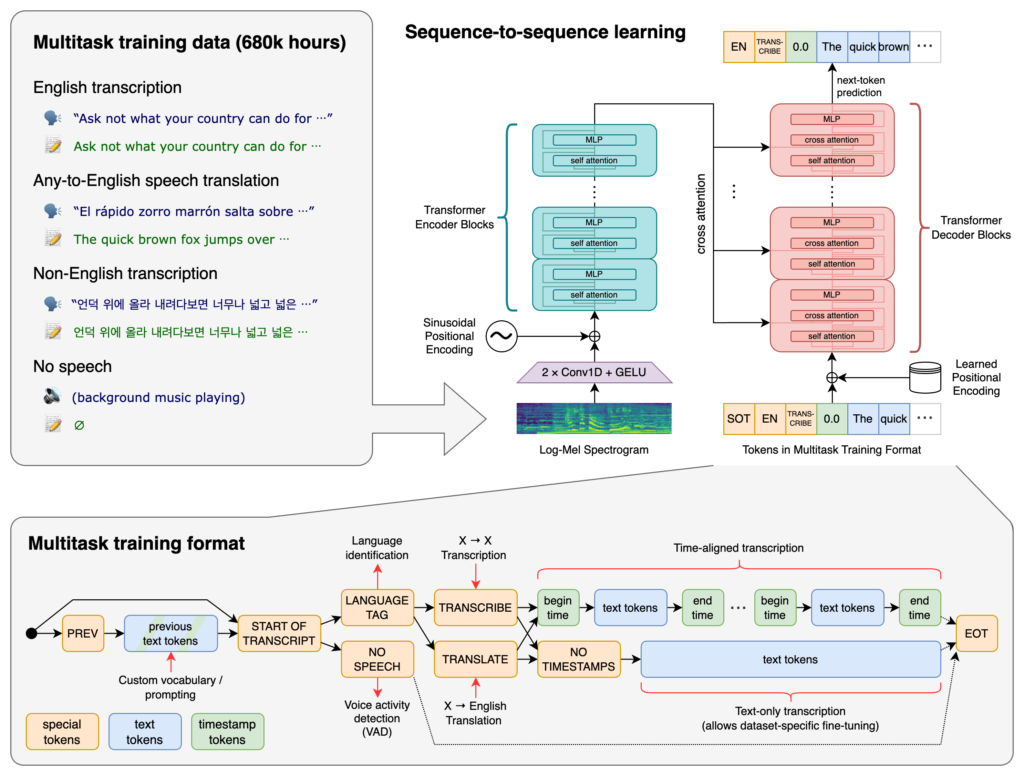
このモデルは多様な音声の大規模なデータセットでトレーニングされており、多言語の音声認識、音声翻訳、言語識別を実行できるマルチタスク モデルでもあります。
日本語にも対応しているため、日本語のまま使用することができます。
詳細はリンク先からご確認ください。
Github:https://github.com/openai/whisper
論文: https://cdn.openai.com/papers/whisper.pdf
公式サイト:https://openai.com/blog/whisper
公開されているモデルにはいくつか種類があります。
多言語モデルは日本語にも対応しています。
| モデルサイズ | パラメータ数 | 英語専用 モデル | 多言語モデル | 必要なVRAM | 相対速度 |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1GB | ~32x |
| base | 74M | base.en | base | ~1GB | ~16x |
| small | 244M | small.en | small | ~2GB | ~6x |
| medium | 769M | medium.en | medium | ~5GB | ~2x |
| large | 1550 M | なし | large | ~10GB | 1x |
Faster Whisperとは
Faster-whisper は、OpenAI の Whisper モデルを再実装した高速推論エンジンで、CTranslate2 という Transformer モデルを活用しています。OpenAI の公式モデルを軽量化し、独自の最適化により最大4倍の高速化が実現されています。また、軽いと評判の Whisper.cpp よりも高速に動作し、GPU による高速化の恩恵を受けることができます。本家のwhisperと比較しても高速度で処理することが可能です。
| Implementation | Precision | Beam size | Time | Max. GPU memory | Max. CPU memory |
|---|---|---|---|---|---|
| openai/whisper | fp16 | 5 | 4m30s | 11325MB | 9439MB |
| faster-whisper | fp16 | 5 | 54s | 4755MB | 3244MB |
| faster-whisper | int8 | 5 | 59s | 3091MB | 3117MB |
開発元は OpenAI ではなく、あくまで OpenAI のモデルをベースに改良・再実装を行ったものである点に注意してください。Faster-whisperを使用するメリットは以下のようにまとめることができます。
- 外部に音声データを送信したくない場合
- 25MB 以上の音声データを送信したい場合
- 無料で利用したい場合
- 他の処理と組み合わせて使用したい場合(例えばYouTube動画をダウンロードしてから文字起こしするなど)
詳細はリンク先からご確認ください。
yt-dlpとは
yt-dlpは、YouTubeをはじめとするオンライン動画サイトから動画や音声をダウンロードするための便利なツールです。かつては「youtube-dl」という同様のツールが人気を博していましたが、近年は開発が停滞し、ダウンロード速度の低下が問題となっていました。そこで登場したのが、youtube-dlの改良版とも言えるyt-dlpです。
yt-dlpの最大の特徴は、youtube-dlと比較してダウンロード速度が格段に速いことです。この速度向上により、ユーザーは手間なく迅速に動画や音声ファイルを入手することができます。また、動画だけでなく、音声ファイルのみを抽出することも可能であり、用途に合わせて選択できる柔軟性も提供しています。
公式の実装は以下のリンクからご覧ください。
【Python活用】「yt-dlp」を使ってYouTube動画や音楽をダウンロードする
このシリーズでは、Pythonの様々な活用の方法を紹介しています。 今回は、PythonでYouTube動画を簡単にダウンロードする方法を紹介します。 Google colabを使用して簡単に…

YouTube動画から文字起こし
早速文字起こしを実装してみましょう。
今回紹介するコードは以下のリンクからもご覧いただけます。
![]()
準備
ここからは、Google colab環境で進めていきます。
はじめに、GPUを使用できるように設定をします。
「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をGPUに変更
必要なライブラリをインストールします。
!pip install faster-whisper
!python -m pip install -U yt-dlp以上で準備が完了しました。
実装
まずは音声データを用意します。
今回はこちらの楽曲をお借りして、文字起こしを行ってみましょう。
この音声データのYouTube動画(https://youtu.be/n_aUYrXre18)から音声のみを「audio.mp3」として保存します。
!yt-dlp -x --audio-format mp3 https://youtu.be/n_aUYrXre18 -o audio.mp3「large-v2」というモデルを使用して、上で保存した音声データから文字起こしを実装します。
from faster_whisper import WhisperModel
model_size = "large-v2"
model = WhisperModel(model_size, device="cuda", compute_type="float16")
segments, info = model.transcribe("audio.mp3", beam_size=5)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))実行すると、以下のような結果が出力されます。
Detected language 'ja' with probability 0.976074
[0.00s -> 6.00s] 星が変える頃には 僕ら二人だけさ
[6.00s -> 12.00s] きっと優しい雨のような 光が降る
[12.00s -> 19.00s] 君と肩を並べて 寂しくはないかな
[19.00s -> 27.00s] さあ手を繋いで 終わりの空を見よう
[27.00s -> 33.00s] 君と肩を並べて 終わりの空を見よう
[34.00s -> 45.00s] 曇り空に 君の歌が溶けたのかな
[45.00s -> 52.00s] 君の歌が溶けたのかな
[52.00s -> 64.00s] 乾いた空に 君の歌が溶けたのかな
[64.00s -> 76.00s] 急に降り出した 雨もきっとすぐ止むよ
[76.00s -> 88.00s] 二つの太陽 一つになって僕ら進む
[88.00s -> 99.00s] 過去の思い出も 明日に綺麗に燃える
[99.00s -> 106.00s] ほら 目指す場所はすぐそこ もう少し歩こう
[106.00s -> 112.00s] 悲しいこと 夢も全部 散ってゆくよ
[112.00s -> 118.00s] だから今は進もう 顔を伏せてゆこう
[118.00s -> 127.00s] この強い風が僕らを 笑ってても
[127.00s -> 139.00s] 湿った匂い 森が霞んで見えない
[139.00s -> 150.00s] もうすぐ夜明け あとは待っていればいい
[150.00s -> 157.00s] ほら 星が変えるときだね 僕ら二人だけさ
[157.00s -> 163.00s] また次の世界で君ときっと会える
[163.00s -> 169.00s] ほら寂しくないよね 今一緒だから
[169.00s -> 176.00s] さあ手を繋いで 終わりの空を見よう
[193.00s -> 203.00s] サブタイトル コレクション音声ファイルから文字起こしをすることができました。
通常の会話のような音声だけでなく、楽曲の場合でも使用することができることがわかります。
まとめ
最後までご覧いただき、ありがとうございました。
今回はOpenAI の Whisper モデルを再実装した高速音声認識モデルである「Faster Whisper」を実装する方法を紹介しました。
YouTube動画の文字起こしによる字幕作成の自動化をはじめ、議事録の作成など業務においても、活用が期待できそうです。

