2022年11月に登場したセグメンテーションのフレームワークであるOneFormerを紹介します。
Google colabを使用して、簡単に最新のセグメンテーションモデルを実装することができますので、ぜひ最後までご覧ください。
今回の内容
・セグメンテーションとは
・OneFormerとは
・OneFormerの導入
・各モデルの実装
セグメンテーションとは
画像に何が写っているかを機械に理解させようとする画像認識のタスクの中に「セグメンテーション」があります。
セグメンテーションは画像のピクセル単位で何を示しているかを分類する手法です。
単純に各ピクセルが何を表しているかを推定するSemantic Segmentation、画像中から物体とその意味を推定するInstance Segmentation、これらを組み合わせたPanoptic Segmentationの3つに大別されます。
セマンティック セグメンテーション
画像全体や画像の一部分の検出ではなく、ピクセル(画素)ごとに示す意味をラベル付けしていく手法です。
画像のピクセルがどのカテゴリに属するかで分類し、何が写っているかのラベル付けやカテゴリ関連付けを行います。
物体の種類ごとに領域分割し、物体が重なっているときにはそれぞれの区別ができませんが、背景や車、人など不定形の領域を検出することが可能です。
インスタンス セグメンテーション
画像中の全ての物体に対して(物体検出をした領域を対象)クラスラベルを予測し、一意のIDを付与することを目的と手法です。
不定形の領域は扱えませんが、隣接した同種類の物体は区別できます。
例えば、各物体に対して一意のIDを付与するため、1つの画像に複数の人が写っている場合にはそれぞれの車を別々の物体と認識することが可能です。

パノプティック セグメンテーション
セマンティックセグメンテーションとインスタンスセグメンテーションを組み合わせた方法です。
すべてのピクセルにラベルがふられて、数えられる物体に関して個別で認識した結果が出てきます。
個々の物体をそれぞれ分離しつつ、壁や床などはひとまとめにすることがでます。

OneFormerとは
OneFormerは2022年11月に登場しました。
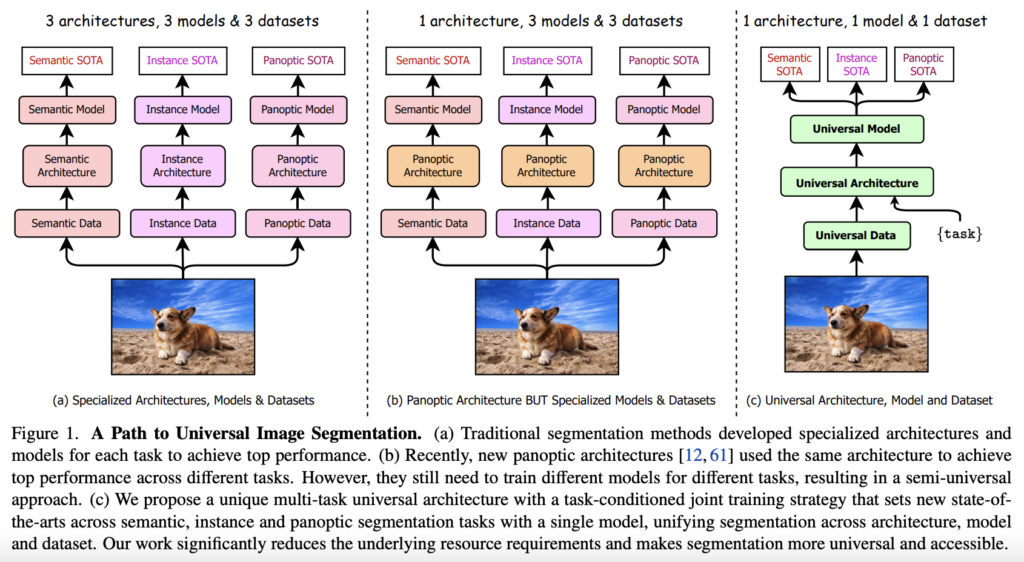
1度の学習で3つのセグメンテーションタスク(セマンティック、インスタンス、パノプティック)の推論を可能とした、マルチタスクユニバーサルイメージセグメンテーションフレームワークです
タスクに応じた共同学習戦略を採用し、異なる基底真理領域(意味、インスタンス、汎光)を一様にサンプリングし、汎光アノテーションからすべてのラベルを導出することで、3つのセグメンテーションタスクを同時に行うことができます。
OneFormerは3つのベンチマーク(ADE20K 、Cityscapes、COCO)において、SoTAを達成しています。
詳細は以下のリンクからご確認ください。
OneFormerの導入
導入
ここからはGoogle colabを使用して実装していきます。
今回紹介するコードは以下のボタンからコピーして使用していただくことも可能です。
![]()
まずはGoogleドライブをマウントします。
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive公式よりcloneしてきます。
!git clone https://github.com/SHI-Labs/OneFormer-Colab.git
! mv OneFormer-Colab OneFormer%cd OneFormer必要なライブラリをインストールします。
## Install Pytorch
!pip install torch==1.9.0 torchvision==0.10.0 --quiet
# # Install opencv (required for running the demo)
!pip install -U opencv-python --quiet
# # # Install detectron2
!python -m pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu102/torch1.9/index.html --quiet
!pip3 install natten==0.14.2 -f https://shi-labs.com/natten/wheels/cu102/torch1.9/index.html --quiet
# # # Install other dependencies
!pip install git+https://github.com/cocodataset/panopticapi.git --quiet
!pip install git+https://github.com/mcordts/cityscapesScripts.git --quiet
!pip install -r requirements.txt --quiet
!pip install ipython-autotime
!pip install imutils
!pip install colormap
!pip install easydev
!pip install timm以上で導入は完了です。
必要な関数の定義とモデルのダウンロード
次に必要な関数の定義とモデルのダウンロードします。
import detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
setup_logger(name="oneformer")
# Import libraries
import numpy as np
import cv2
import torch
from google.colab.patches import cv2_imshow
import imutils
# Import detectron2 utilities
from detectron2.config import get_cfg
from detectron2.projects.deeplab import add_deeplab_config
from detectron2.data import MetadataCatalog
from demo.defaults import DefaultPredictor
from demo.visualizer import Visualizer, ColorMode
# import OneFormer Project
from oneformer import (
add_oneformer_config,
add_common_config,
add_swin_config,
add_dinat_config,
add_convnext_config,
)モデルを指定します。
cpu_device = torch.device("cpu")
SWIN_CFG_DICT = {"cityscapes": "configs/cityscapes/oneformer_swin_large_IN21k_384_bs16_90k.yaml",
"coco": "configs/coco/oneformer_swin_large_IN21k_384_bs16_100ep.yaml",
"ade20k": "configs/ade20k/oneformer_swin_large_IN21k_384_bs16_160k.yaml",}
DINAT_CFG_DICT = {"cityscapes": "configs/cityscapes/oneformer_dinat_large_bs16_90k.yaml",
"coco": "configs/coco/oneformer_dinat_large_bs16_100ep.yaml",
"ade20k": "configs/ade20k/oneformer_dinat_large_IN21k_384_bs16_160k.yaml",}次に必要な関数の定義します。
def setup_cfg(dataset, model_path, use_swin):
# load config from file and command-line arguments
cfg = get_cfg()
add_deeplab_config(cfg)
add_common_config(cfg)
add_swin_config(cfg)
add_dinat_config(cfg)
add_convnext_config(cfg)
add_oneformer_config(cfg)
if use_swin:
cfg_path = SWIN_CFG_DICT[dataset]
else:
cfg_path = DINAT_CFG_DICT[dataset]
cfg.merge_from_file(cfg_path)
cfg.MODEL.DEVICE = 'cpu'
cfg.MODEL.WEIGHTS = model_path
cfg.freeze()
return cfg
def setup_modules(dataset, model_path, use_swin):
cfg = setup_cfg(dataset, model_path, use_swin)
predictor = DefaultPredictor(cfg)
metadata = MetadataCatalog.get(
cfg.DATASETS.TEST_PANOPTIC[0] if len(cfg.DATASETS.TEST_PANOPTIC) else "__unused"
)
if 'cityscapes_fine_sem_seg_val' in cfg.DATASETS.TEST_PANOPTIC[0]:
from cityscapesscripts.helpers.labels import labels
stuff_colors = [k.color for k in labels if k.trainId != 255]
metadata = metadata.set(stuff_colors=stuff_colors)
return predictor, metadata
def panoptic_run(img, predictor, metadata):
visualizer = Visualizer(img[:, :, ::-1], metadata=metadata, instance_mode=ColorMode.IMAGE)
predictions = predictor(img, "panoptic")
panoptic_seg, segments_info = predictions["panoptic_seg"]
out = visualizer.draw_panoptic_seg_predictions(
panoptic_seg.to(cpu_device), segments_info, alpha=0.5
)
return out
def instance_run(img, predictor, metadata):
visualizer = Visualizer(img[:, :, ::-1], metadata=metadata, instance_mode=ColorMode.IMAGE)
predictions = predictor(img, "instance")
instances = predictions["instances"].to(cpu_device)
out = visualizer.draw_instance_predictions(predictions=instances, alpha=0.5)
return out
def semantic_run(img, predictor, metadata):
visualizer = Visualizer(img[:, :, ::-1], metadata=metadata, instance_mode=ColorMode.IMAGE)
predictions = predictor(img, "semantic")
out = visualizer.draw_sem_seg(
predictions["sem_seg"].argmax(dim=0).to(cpu_device), alpha=0.5
)
return out
TASK_INFER = {"panoptic": panoptic_run,
"instance": instance_run,
"semantic": semantic_run}以上で準備は完了です。
ADE20K
ここからはそれぞれのデータセットに対するモデルを使用していきます。
まずは「ADE20K」のものからです。
use_swin = Trueimport os
import subprocess
if not use_swin:
if not os.path.exists("250_16_dinat_l_oneformer_ade20k_160k.pth"):
subprocess.run('wget https://shi-labs.com/projects/oneformer/ade20k/250_16_dinat_l_oneformer_ade20k_160k.pth', shell=True)
predictor, metadata = setup_modules("ade20k", "250_16_dinat_l_oneformer_ade20k_160k.pth", use_swin)
else:
if not os.path.exists("250_16_swin_l_oneformer_ade20k_160k.pth"):
subprocess.run('wget https://shi-labs.com/projects/oneformer/ade20k/250_16_swin_l_oneformer_ade20k_160k.pth', shell=True)
predictor, metadata = setup_modules("ade20k", "250_16_swin_l_oneformer_ade20k_160k.pth", use_swin)次に画像を用意します。
ここでは、サンプル画像を使用して推論を行います。
img = cv2.imread("samples/ade20k.jpeg")
img = imutils.resize(img, width=640)
cv2_imshow(img)
それぞれ行いたいタスクを指定します。
以下はセマンティックセグメンテーションの例です。
task = "semantic"
%load_ext autotime
out = TASK_INFER[task](img, predictor, metadata).get_image()
cv2_imshow(out[:, :, ::-1])
パノプティック セグメンテーションの例です。
task = "panoptic"
%load_ext autotime
out = TASK_INFER[task](img, predictor, metadata).get_image()
cv2_imshow(out[:, :, ::-1])
Cityscapes
次に「Cityscapes」によるモデルです。
use_swin = Trueimport os
import subprocess
if not use_swin:
if not os.path.exists("250_16_dinat_l_oneformer_cityscapes_90k.pth"):
subprocess.run('wget https://shi-labs.com/projects/oneformer/cityscapes/250_16_dinat_l_oneformer_cityscapes_90k.pth', shell=True)
predictor, metadata = setup_modules("cityscapes", "250_16_dinat_l_oneformer_cityscapes_90k.pth", use_swin)
else:
if not os.path.exists("250_16_swin_l_oneformer_cityscapes_90k.pth"):
subprocess.run('wget https://shi-labs.com/projects/oneformer/cityscapes/250_16_swin_l_oneformer_cityscapes_90k.pth', shell=True)
predictor, metadata = setup_modules("cityscapes", "250_16_swin_l_oneformer_cityscapes_90k.pth", use_swin)同様に画像を用意します。
ここでは、サンプル画像を使用して推論を行います。
img = cv2.imread("samples/cityscapes.png")
img = imutils.resize(img, width=512)
cv2_imshow(img)
それぞれタスクを指定して実行します。
以下はセマンティックセグメンテーションの例です。
task = "semantic"
%load_ext autotime
out = TASK_INFER[task](img, predictor, metadata).get_image()
cv2_imshow(out[:, :, ::-1])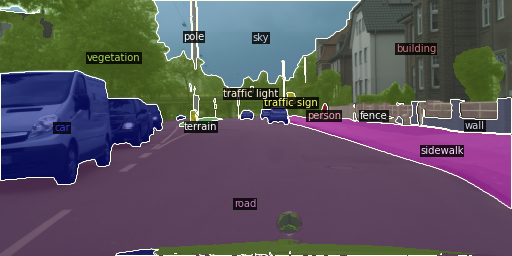
以下はインスタンスセグメンテーションの例です。
task = "instance"
%load_ext autotime
out = TASK_INFER[task](img, predictor, metadata).get_image()
cv2_imshow(out[:, :, ::-1])

パノプティック セグメンテーションの例です。
task = "panoptic"
%load_ext autotime
out = TASK_INFER[task](img, predictor, metadata).get_image()
cv2_imshow(out[:, :, ::-1])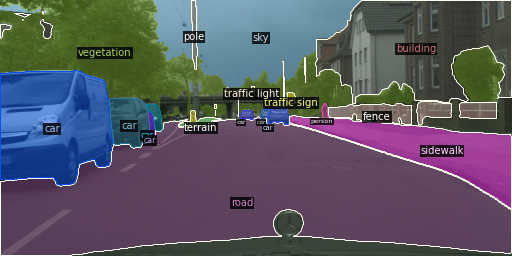
COCO
最後に「COCOデータセット」によるモデルです。
use_swin = Trueimport os
import subprocess
if not use_swin:
if not os.path.exists("150_16_dinat_l_oneformer_coco_100ep.pth"):
subprocess.run('wget https://shi-labs.com/projects/oneformer/coco/150_16_dinat_l_oneformer_coco_100ep.pth', shell=True)
predictor, metadata = setup_modules("coco", "150_16_dinat_l_oneformer_coco_100ep.pth", use_swin)
else:
if not os.path.exists("150_16_swin_l_oneformer_coco_100ep.pth"):
subprocess.run('wget https://shi-labs.com/projects/oneformer/coco/150_16_swin_l_oneformer_coco_100ep.pth', shell=True)
predictor, metadata = setup_modules("coco", "150_16_swin_l_oneformer_coco_100ep.pth", use_swin)同様に画像を用意します。
ここでは、サンプル画像を使用して推論を行います。
img = cv2.imread("samples/coco.jpeg")
img = imutils.resize(img, width=512)
cv2_imshow(img)
それぞれタスクを指定して実行します。
task = "semantic"
%load_ext autotime
out = TASK_INFER[task](img, predictor, metadata).get_image()
cv2_imshow(out[:, :, ::-1]
task = "instance"
%load_ext autotime
out = TASK_INFER[task](img, predictor, metadata).get_image()
cv2_imshow(out[:, :, ::-1])
task = "panoptic"
%load_ext autotime
out = TASK_INFER[task](img, predictor, metadata).get_image()
cv2_imshow(out[:, :, ::-1])
まとめ
最後までご覧いただきありがとうございました。
2022年11月に登場したセグメンテーションのフレームワークであるOneFormerを紹介しました。
高性能なセグメンテーションのモデルを簡単に実装することができました。