主成分分析
データの特徴量間の関係性、相関を分析しデータの構造をつかむ手法。特に特徴量の数が多い場合に用いられ、相関をもつ多数の特徴量から相関のない少数の特徴量へと次元削減することが主たる目的。ここで得られる少数の特徴量を主成分という。 線形な次元削減であり、計算量の削減ができ次元の呪いの回避が可能となる。寄与率を調べれば各成分の重要度が把握でき、主成分を調べれば各成分の意味を推測しデータの可視化が可能となる。
主成分分析以外には、特異値分解(Singular Value Decomposition、SVD)、多次元尺度構成法(Multi-Dimensional Scaling、MDS)がよく用いられる。可視化によく用いられる次元圧縮の手法は、t-SNE(t-distributed Stochastic NeighborEmbedding)がある。t-SNEのtはt分布のtである。
主成分分析
主成分分析 (PCA) は、可能な限り多くの変動性を保持しながら次元を削減することにより、データセットの基になる構造を特定するために使用される一般的な統計手法です。PCA には、主成分と呼ばれるデータの最大分散の方向を特定する線形代数手法を使用して、元のデータセットを変換することが含まれます。
最初の主成分は、データの変動性が最も大きい方向を捉えるために選択されます。2 番目の主成分は、最初の主成分に直交する (垂直な) 最大の変動性の方向を捉えるために選択され、以降の成分についても同様です。保持される主成分の数は、それらがデータで説明する変動の量によって決定され、保持する分散の所定の量、または目的の成分数に基づいて選択できます。
PCA は、データの視覚化、特徴選択、データ圧縮、ノイズ削減など、多くのアプリケーションに使用されます。任意のデータセットに適用できますが、高次元のデータを扱う場合や、変数間の関係がよくわかっていない場合に特に役立ちます。
主成分分析のアルゴリズム
PCA のアルゴリズムは次のとおりです。
- データを標準化する: 元の値から各変数の平均を引き、その結果をその変数の標準偏差で割ります。
- 共分散行列を計算する: 標準化されたデータの共分散行列を計算します。
- 共分散行列の固有ベクトルと固有値を計算します。固有ベクトルはデータの最大分散の方向であり、固有値は各固有ベクトルによってキャプチャされる分散の量を示します。
- 上位 k 個の固有ベクトルを選択: 固有ベクトルを対応する固有値で降順に並べ替え、固有値が最も高い上位 k 個の固有ベクトルを選択します。これらの上位 k 個の固有ベクトルは、データの主成分です。
- データを新しい特徴空間に投影します。元のデータに選択した固有ベクトルを掛けて、新しい特徴空間を取得します。各データ ポイントは、長さ k のベクトルで表されます。ここで、k は選択された主成分の数です。
新しい特徴空間の結果のデータは、重要な情報のほとんどを保持しながら、元のデータよりも次元が少なくなります。主成分はデータの最も重要なパターンを表し、視覚化、クラスタリング、分類などのさまざまな目的に使用できます。
主成分分析の主な用途
主成分分析 (PCA) は、データ サイエンスと機械学習で一般的に使用される教師なし学習手法であり、分散を可能な限り維持しながら大規模なデータセットの次元を削減します。PCA を使用する場合の具体的な例を次に示します。
- 画像処理: PCA を使用すると、多くの情報を失うことなく画像データの次元を削減できます。これは、情報の損失を最小限に抑えて、より小さな主成分セットで元の画像を表すことができる画像圧縮などのタスクで役立ちます。
- 遺伝学: ゲノミクスの分野では、PCA を使用して、類似した遺伝子プロファイルを持つ個人のクラスターを特定できます。これは、研究者が特定の疾患のリスクが高い可能性がある個人のグループや、特定の治療法に対して異なる反応を示す可能性のある個人のグループを特定するのに役立ちます。
- 金融: PCA を金融で使用して、さまざまな株式間の相関関係を特定し、市場の変動の影響を受けにくいポートフォリオを構築できます。
- テキスト分析: PCA を自然言語処理 (NLP) で使用して、テキスト データの大規模なコーパスで最も重要なトピックを特定できます。これは、感情分析やトピック モデリングなどのタスクに役立ちます。
- 信号処理: PCA を使用して、音声データや音声データなど、信号の最も重要な特徴を特定できます。これは、ノイズ削減や音声認識などのタスクに役立ちます。
- マーケティング: PCA をマーケティングで使用して、同様の購買行動を持つ顧客セグメントを特定できます。これにより、企業はマーケティング活動の対象をより効果的に絞り込み、特定の顧客のニーズに合わせて製品やサービスを調整することができます。
これらは、PCA が使用される場合のほんの一例です。一般に、PCA は、大規模なデータセットを分析する必要があり、データを高次元空間で表すことができるアプリケーションで使用できます。
主成分分析と寄与率
主成分分析 (PCA) は、元のデータのほとんどの情報を保持しながら変数の数を減らすことによって、データのパターンを識別するために使用される統計手法です。PCA は、元のデータ セットを新しい座標系に変換することによって機能します。この座標系の軸は、元の変数の線形結合である主成分です。第 1 主成分はデータの分散の最大量を説明し、第 2 主成分は分散の 2 番目に大きな量を説明します。
寄与率は、説明された分散比とも呼ばれ、各主成分によって説明されるデータの総分散の比率です。各主成分の寄与率は、すべての主成分の合計分散に対するその成分の分散の比率として計算されます。言い換えれば、各主成分に起因するデータの合計分散のパーセンテージを表します。
寄与率は、多くの場合、分析で保持する主成分の数を決定するために使用されます。通常、データの合計分散の大部分を説明する主成分のみが保持され、残りは破棄されます。これは、保持された主成分がデータ内の最も重要な情報をキャプチャし、データの分析または視覚化を簡素化するために使用できるためです。
主成分分析の実装
Iris データセットを使用して主成分分析 (PCA) を実行する簡単な例を次に示します。
最初に Iris データセットを読み込み、そこから Pandas DataFrame を作成します。
# import necessary libraries
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# load iris dataset
iris = load_iris()
# create dataframe of iris dataset
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df.head()最初の5行を表示してみます。
| index | sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
次に特徴量を標準化し、各特徴の平均が 0 で標準偏差が 1 になるようにします。
# standardize the features
scaler = StandardScaler()
df_std = scaler.fit_transform(df)次に、最初の 2 つの主成分を抽出するためにPCA を実行します。
# perform PCA
pca = PCA(n_components=2)
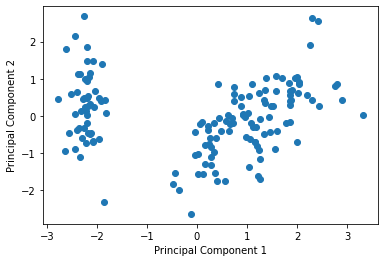
principal_components = pca.fit_transform(df_std)最後に2 つの主成分によって定義される新しい座標系でのデータの分布をプロットします。
# create dataframe of principal components
df_pca = pd.DataFrame(data=principal_components, columns=['PC1', 'PC2'])
# print explained variance ratio
print(pca.explained_variance_ratio_)
# visualize principal components
import matplotlib.pyplot as plt
plt.scatter(df_pca['PC1'], df_pca['PC2'])
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()