このシリーズではE資格対策として、シラバスの内容を項目別にまとめています。
損失関数はなぜ必要なのか
損失関数(Loss function)は、機械学習やディープラーニングのモデルが学習する際に必要な要素です。損失関数は、モデルの予測結果と実際の目標値(正解ラベル)との差を数値化し、その差がどれだけ大きいかを評価する指標です。損失関数が必要な理由は以下の通りです。
- モデルのパフォーマンスの評価: 損失関数の値が小さいほど、モデルの予測が正解ラベルに近いことを意味します。損失関数を使って、モデルの性能を定量的に評価し、改善の必要性や方向性を判断することができます。
- パラメータの最適化: 損失関数を最小化するようにモデルのパラメータ(重みとバイアス)を更新することで、学習が進みます。損失関数は、パラメータの調整において目標となる指標であり、最適化アルゴリズム(例:確率的勾配降下法やAdam)が損失関数の勾配情報を利用して、パラメータを更新します。これにより、モデルは予測性能が向上し、データからのパターンや特徴を学習することができます。
- 適切なモデルの選択: 様々なモデルやアルゴリズムが存在しますが、それぞれのモデルに対して損失関数を計算することで、どのモデルが最も良い性能を持っているかを比較することができます。損失関数の値が最も小さいモデルが、最も適切なモデルとして選択されることが一般的です。
- 学習の進行状況の監視: 損失関数の値は、学習プロセス全体を通して監視されます。学習が進むにつれて、損失関数の値は通常減少し、モデルの性能が向上していることを示します。もし損失関数の値が減少しない場合、学習が適切に進行していない可能性があり、モデルのアーキテクチャや学習率などのハイパーパラメータを見直す必要があります。
損失関数は、学習タスクの目的に応じて選択されます。例えば、回帰問題の場合、平均二乗誤差(Mean Squared Error, MSE)がよく使用される損失関数です。一方、分類問題では、クロスエントロピー損失(Cross-Entropy Loss)が一般的に用いられます。
2乗和誤差
2乗和誤差(Squared Sum Error, SSE)は、回帰問題において使用される損失関数の一つです。2乗和誤差は、モデルの予測値と実際の目標値(正解ラベル)との差を二乗し、それらの和を計算します。2乗和誤差の数式は以下のように表されます。
ここで、y は実際の目標値、ŷ はモデルによる予測値です。Σは、すべてのデータポイントに対して和を取ることを示しています。
2乗和誤差は、以下のような特徴があります。
- 値が非負: 差の2乗を計算しているため、2乗和誤差の値は常に非負です。これにより、損失関数の値が0に近いほど予測が正確であることを意味します。
- 外れ値に敏感: 二乗を取っているため、外れ値(大きな誤差を持つデータポイント)はより大きなペナルティを受けます。このため、モデルは外れ値に対して強く適合しようとします。
ただし、2乗和誤差は単純に和を取っているため、データ数の影響を受けやすいです。そのため、データ数によらない評価指標として平均二乗誤差(Mean Squared Error, MSE)がよく使われます。MSEは、2乗和誤差をデータ数で割った値で、以下のように表されます。
MSEの実装(計算過程あり)
以下のMNISTの推論結果を例に、2乗和誤差を実装してみましょう。
この例では、ニューラルネットによる推論結果と実際の正解データの例となります。
# ニューラルネットワークの出力
y = np.array([0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0])
# 正解データ
t = np.array([0, 0, 1, 0, 0, 0, 0, 0, 0, 0])この例をもとに、まずは計算過程がわかるように出力してみます。
import numpy as np
# ニューラルネットワークの出力
y = np.array([0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0])
# 正解データ
t = np.array([0, 0, 1, 0, 0, 0, 0, 0, 0, 0])
# 2乗和誤差を計算する関数
def mean_squared_error(y, t):
# 出力と教師データの差分を計算
diff = y - t
print("差分:", diff)
# 差分を二乗
squared_diff = diff ** 2
print("二乗した差分:", squared_diff)
# 二乗した差分の合計を求め、データ数で割って平均を計算
mse = np.sum(squared_diff) / len(y)
print("二乗和誤差の平均:", mse)
return mse
# 2乗和誤差の計算
mse = mean_squared_error(y, t)実行結果:
差分: [ 0.1 0.05 -0.4 0. 0.05 0.1 0. 0.1 0. 0. ]
二乗した差分: [0.01 0.0025 0.16 0. 0.0025 0.01 0. 0.01 0. 0. ]
二乗和誤差の平均: 0.019500000000000007それぞれの差分を計算し、その2乗の値の総和をとって、最後にデータ数で割っています。
MSEの実装
途中経過を省略してまとめると以下のようになります。
import numpy as np
# ニューラルネットワークの出力を作成
y = np.array([0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0])
# 教師データを作成
t = np.array([0, 0, 1, 0, 0, 0, 0, 0, 0, 0])
# 2乗和誤差を計算する関数
def mean_squared_error(y, t):
# 出力と教師データの差分を計算
diff = y - t
# 差分を二乗
squared_diff = diff ** 2
# 二乗した差分の合計を求め、データ数で割って平均を計算
mse = np.sum(squared_diff) / len(y)
return mse
# 2乗和誤差の計算
mse = mean_squared_error(y, t)
print("Mean Squared Error:", mse)実行結果:
二乗和誤差の平均: 0.019500000000000007交差エントロピー誤差
交差エントロピー誤差はモデルの予測確率分布と正解の確率分布との間の類似度を測るために使用されます。具体的には、交差エントロピー誤差は予測確率分布が正解の確率分布にどれだけ近いかを評価し、その距離を最小化するようにモデルを最適化します。
交差エントロピー誤差は以下の式で表されます:
ここで、p(x) は正解の確率分布を、q(x) はモデルによる予測確率分布を表します。Σは、全てのクラスにわたる和を取ることを示しています。この式により、予測が正解と一致するときに損失が小さくなり、一致しないときに損失が大きくなるため、モデルは損失を最小化するように学習します。確率的な予測と実際のラベルとの間の不一致を効果的に評価できるため、多クラス分類問題やニューラルネットワークの学習に広く利用されています。
交差エントロピー誤差のグラフ
2つの確率分布がどれだけ近いかを視覚的に理解するために、2つのクラスがある場合の交差エントロピー誤差をグラフで表すことができます。以下のコードは、バイナリ分類問題(クラスが2つだけ)に対して、交差エントロピー誤差のグラフを描画する例です。
import numpy as np
import matplotlib.pyplot as plt
# 真の確率分布 (バイナリ分類の場合)
y_true = np.array([1, 0])
# 交差エントロピー誤差関数の定義
def binary_cross_entropy_error(y_true, y_pred):
return -np.sum(y_true * np.log(y_pred + 1e-7))
# 予測確率分布の範囲 (0.01 から 0.99 まで 0.01 刻み)
predictions = np.arange(0.01, 1, 0.01)
# 交差エントロピー誤差を計算
errors = [binary_cross_entropy_error(y_true, np.array([pred, 1 - pred])) for pred in predictions]
# グラフの表示
plt.plot(predictions, errors)
plt.xlabel('Prediction for Class 1')
plt.ylabel('Cross Entropy Error')
plt.title('Cross Entropy Error for Binary Classification')
plt.grid()
plt.show()実行結果:
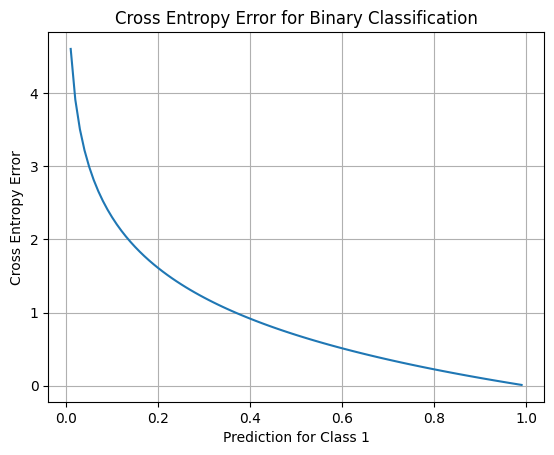
この結果は、バイナリ分類問題(クラスが2つだけ)に対して交差エントロピー誤差のグラフを表示しています。グラフは、予測確率が正解確率分布(クラス1が正解)に近づくと交差エントロピー誤差が小さくなり、遠ざかると大きくなることを示しています。
交差エントロピー誤差の実装(途中経過あり)
以下のMNISTの推論結果を例に、交差エントロピー誤差を実装してみましょう。
この例では、ニューラルネットによる推論結果と実際の正解データの例となります。
# ニューラルネットワークの出力
y = np.array([0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0])
# 正解データ
t = np.array([0, 0, 1, 0, 0, 0, 0, 0, 0, 0])この例をもとに、まずは計算過程がわかるように出力してみます。
import numpy as np
def cross_entropy_error(y, t):
delta = 1e-7 # ゼロ除算を防ぐための微小な値
return -np.sum(t * np.log(y + delta))
y = np.array([0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0])
t = np.array([0, 0, 1, 0, 0, 0, 0, 0, 0, 0])
# ステップ1: t * np.log(y + delta) を計算
step1 = t * np.log(y + 1e-7)
print("Step 1: t * np.log(y + delta):\n", step1)
# ステップ2: ステップ1の結果を合計する
step2 = -np.sum(step1)
print("Step 2: -np.sum(step1):\n", step2)
# エントロピー交差誤差を計算
loss = cross_entropy_error(y, t)
print("Final Loss:\n", loss)実行結果:
Step 1: t * np.log(y + delta):
[-0. -0. -0.51082546 -0. -0. -0. -0. -0. -0. -0.]
Step 2: -np.sum(step1):
0.510825457099338
Final Loss:
0.510825457099338エントロピー交差誤差の計算過程を2つのステップに分けて表示しています。
- ステップ1では、
t * np.log(y + delta)を計算しています。このステップでは、教師データ(t)とニューラルネットワークの出力(y)の各要素ごとに、t_i * log(y_i)を計算します。 - ステップ2では、ステップ1で計算された値の合計を計算します。この合計がエントロピー交差誤差です。
最後に、得られたエントロピー交差誤差の値(loss)を表示しています。
交差エントロピー誤差の実装
途中経過を省略してまとめると以下のようになります。
import numpy as np
def cross_entropy_error(y, t):
delta = 1e-7 # ゼロ除算を防ぐための微小な値
return -np.sum(t * np.log(y + delta))
y = np.array([0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0])
t = np.array([0, 0, 1, 0, 0, 0, 0, 0, 0, 0])
# エントロピー交差誤差を計算
loss = cross_entropy_error(y, t)
print(loss)実行結果:
0.510825457099338エントロピー交差誤差が小さいほど、ニューラルネットワークの出力が教師データに近いことを意味します。逆にエントロピー交差誤差が大きいほど、ニューラルネットワークの出力が教師データから離れている
まとめ
最後までご覧いただきありがとうございました。
