このシリーズではE資格対策として、シラバスの内容を項目別にまとめています。
EfficientNet
EfficientNetの概要
EfficientNetは、2019年5月に登場した深層学習のモデルで、その名の通り効率的に高精度な結果を出力することが可能なモデルです。少ないパラメータで非常に高い精度を達成するため、NFNetなどの最新のモデルと比較されることが多い特徴があります。
従来の深層学習モデルでは、精度向上のために層の数(depth)やチャンネル数(width)を増やす、または画像の解像度(resolution)を上げる方法が一般的でした。これらは手作業で行われるため、時間と労力がかかる割に精度の向上が限定的であったことが問題でした。さらに、モデルが大きくなることで、コンピュータのメモリに収めることが難しくなる場合も出てきました。
EfficientNetの登場によって、これらの課題への解決の道筋が開かれました。特に、小さなモデルの効率化に用いられるNeural architecture search(NAS)のような手法を、大きなモデルにも応用する可能性が示されました。EfficientNetは、画像向けCNNの「深さ」、「幅」、「入力画像の解像度」の3要素をバランスよく調整する方法を提案しました。
この方法では、複合係数を設定し、3要素をそれぞれ特定の倍数で調整することでネットワークを最適化することが可能です。結果として、従来の手法よりも大幅に軽量で、より高精度な予測が可能になりました。また、転移学習に対しても高い精度を示しています。
Compound Model Scaling
従来のディープラーニングモデルにおいて、ネットワークの深さ(d)、幅(w)、画像の解像度(r)のうち1つの側面だけを拡大するアプローチが一般的でした。しかし、これらの要素のうち一つだけを調整することでは、画像の複雑な特徴を捉える能力に限界があります。そこでEfficientNetでは、これら3つの要素を同時に調整する「Compound Model Scaling」という手法を採用しています。
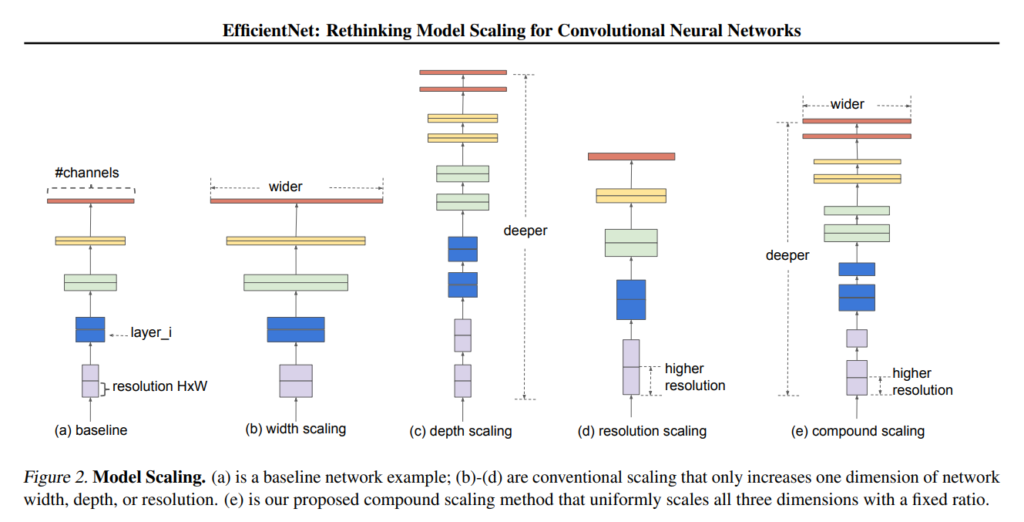
Compound Model Scalingの手法では、まずφが1の時に最適なα、β、γの値を求めます。これらの値は、深さ(d)、幅(w)、解像度(r)をそれぞれ調整する係数で、モデルのスケールアップに使用されます。具体的には、以下の式でこれらの値が決定されます。
- 深さ(d): α^φ
- 幅(w): β^φ
- 解像度(r): γ^φ
ここで、計算量をコントロールするための特別な条件があります。深さ(d)を2倍にすると計算量も2倍になりますが、幅(w)と解像度(r)を2倍にすると計算量はそれぞれ4倍になるため、αだけ2乗の形がついていません。
Neural Architecture Search(NAS)を使用して最適な値を求めた結果、α=1.2、β=1.1、γ=1.15となりました。この時の基礎モデルをEfficientNet-B0と呼び、φを徐々に大きくすることで、EfficientNet-B1からB7のモデル群を作成しています。
EfficientNet-B7
EfficientNet-B7は、既存のモデルに比べて非常に小さく、計算効率が高い構造を持っています。具体的には、8.4倍小さく、6.4倍速いという特性を備えております。この高い計算効率にもかかわらず、驚異的な正答率84.3%を達成し、当時の最先端技術(State-of-the-Art、SOTA)を更新しました。この結果は、Compound Model Scalingの効果を如実に示すものであり、モデルの精度と効率のバランスをうまく取ることができる証左です。
さらに、転移学習という手法を用いてEfficientNetを試す実験も行われました。転移学習は、あらかじめ訓練済みのモデルを使用し、異なるデータセットに対して精度を高めるための方法です。この手法を用いたEfficientNetは、CIFAR-100など5つの有名なデータセットにおいても、当時の最先端技術を更新しました。
まとめ
最後までご覧いただきありがとうございました。
