このシリーズではE資格対策として、シラバスの内容を項目別にまとめています。
分散表現
分散表現の概要
自然言語を計算機で扱う際の一つの課題は、記号である「単語」をどのように数学的に表現するかということです。この問題に対する解決策として、単語の分散表現があります。
まず、単語を数学的に表現する最も単純な方法はワンホットベクトルでの表現です。この方法では、語彙に含まれる単語ごとに一意のベクトルが割り当てられます。しかし、この方法にはいくつかの欠点があります。ベクトル同士の演算が意味をなさないため、単語間の関連性や類似性を表現することができません。また、語彙数が増えると非常に高次元なベクトルになってしまうため、計算コストが高くなります。
これらの問題を解決するために、分散表現が提案されました。分散表現(特に単語を強調する場合は単語分散表現と呼ばれることもあります)は、単語を計算機上で扱うための方法の一つで、単語埋め込みとも呼ばれます。この方法では、単語間の関連性や類似度を考慮したベクトル(埋め込みベクトル)で単語を表現します。
埋め込みベクトルの利点は、ベクトルどうしで足し算や引き算が可能であることです。また、ワンホットベクトルが数万次元になるのに対して、埋め込みベクトルは数百次元くらいに設定することが一般的です。このような低次元の表現によって、単語の情報が効率的に埋め込まれるため、計算コストの削減とともに、単語間の類似度を計算する目的で使われたり、回帰モデルやクラス分類モデルの入力として活用されるなど、多岐にわたる応用が可能になります。
単語埋め込み行列を求めるには、word2vecなどの手法が用いられます。これによって、単語の意味的な関係を反映したベクトルが生成され、自然言語処理のさまざまなタスクで使用されるようになります。
word2vec
word2vecは、自然言語処理における単語の埋め込み行列を学習するための有名な手法で、Continuous Bag-of-Words(CBOW)とskip-gramの2つのニューラルネットワークが用意されています。以下、これらのモデルについて詳しく解説します。
Continuous Bag-of-Words (CBOW)
CBOWモデルは、ある単語の前後の単語(文脈)から、その単語自体を予測するためのニューラルネットワークです。例えば、”the cat sleep on the mat”という文章がある場合、"cat"と"on"という前後の単語から"sleep"を予測するように学習を行います。CBOWは文脈の単語を平均して隠れ層に渡し、ターゲットとなる単語を予測する構造を持っています。
Skip-gram
skip-gramモデルは、CBOWとは逆のアプローチを取ります。ある単語が与えられたときに、その周辺の単語を予測するためのニューラルネットワークです。同じ文章であれば、"sleep"という単語から"cat"と"on"という周辺の単語を予測するように学習を行います。skip-gramは一つの単語から周囲の文脈を予測するため、より多くの文脈情報を学習します。
分布仮説との関連
CBOWとskip-gramの両モデルは、分布仮説を用いて分散表現を獲得していると解釈できます。分布仮説とは、「単語の意味はその周囲の単語によって形成される」という考え方で、この仮説に基づいて単語のベクトルが学習されます。
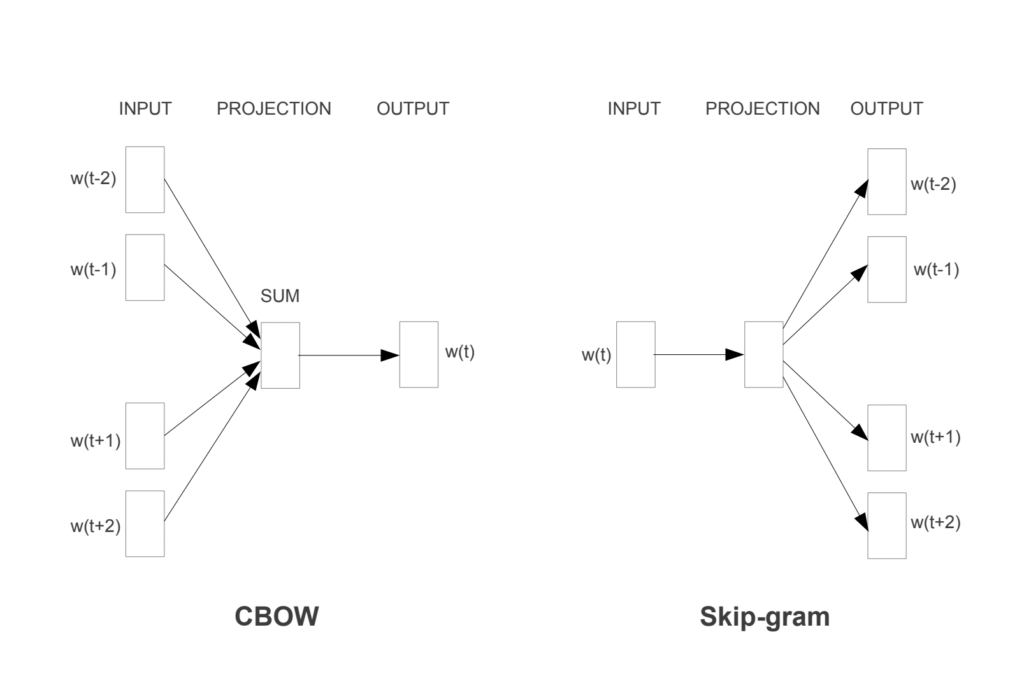
Continuous Bag-of-Words (CBOW)
CBOWは、ある単語の周囲の単語(前後の単語)から、その対象の単語自体を予測するためのニューラルネットワークモデルです。このモデルの名前が示すように、周囲の単語はバッグ(袋)のように取り扱われ、その順序は考慮されません。このため、文脈の単語の平均ベクトルが隠れ層に渡され、対象となる単語を予測します。
CBOWの特徴として、学習にかかる時間がskip-gramよりも短いという点があります。これはCBOWが一度に複数の文脈の単語を考慮するため、学習が効率的に進むためです。一方で、skip-gramは一つの単語から周囲の文脈を予測するため、より細かい文脈の捉え方が可能ですが、学習には時間がかかります。
CBOWの利用は、大量のテキストデータに対して高速に単語の埋め込みを学習したい場合や、文脈の細かな違いを重視しないタスクに特に適しています。対象の単語とその周囲の単語の関係を捉えることで、単語の分散表現を得ることができ、この表現は自然言語処理のさまざまな応用に利用されます。
Skip-gram
skip-gramは、ある単語が与えられた時に、その周辺の単語を予測します。例えば、"the cat sleep on the mat"という文章がある場合、"sleep"から"cat"と"on"などの周辺の単語を予測するように学習を行います。このプロセスは、単語の分散表現を得るために使用されます。
skip-gramモデルは、CBOWに比べて学習に時間がかかる傾向があります。これは、skip-gramが一つの単語から複数の文脈の単語を予測するため、より多くの計算が必要となるためです。しかし、この学習の仕方によって、より精密な単語の文脈の捉え方が可能になります。
この精度の向上は、特に少ないデータ量や罕用語の表現において顕著であり、そうした状況下でのタスクにおいてskip-gramがよく選ばれます。
まとめ
最後までご覧いただきありがとうございました。
