ルールベース機械翻訳
ルールベース機械翻訳の基本概念
ルールベース機械翻訳は、機械翻訳の手法の中で最も長い歴史を持つアプローチです。この方法は、人間が事前に定義した言語規則と辞書情報を基に翻訳を行います。1970年代後半まで広く使用されていたこの手法は、言語学的な知識を直接的に翻訳プロセスに組み込むことを特徴としています。
ルールベース機械翻訳では、原文の文法構造を解析し、その構造に基づいて目標言語の文を生成します。例えば、「I am a human」という英文を日本語に翻訳する場合、システムはまず文の各要素(主語、動詞、目的語など)を特定します。次に、これらの要素を日本語の文法規則に従って並べ替え、適切な助詞を挿入し、「私は人間です」という訳文を生成します。
このプロセスは一見単純に見えますが、実際には膨大な数の文法規則と語彙情報が必要となります。さらに、言語表現の多様性や曖昧性に対応するために、例外処理や文脈理解のためのルールも組み込む必要があり、システムの構築には莫大な時間と労力が要求されます。
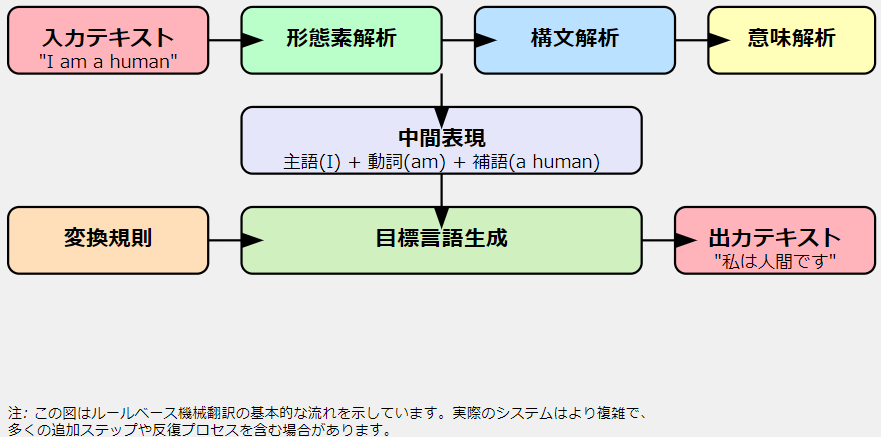
ルールベース機械翻訳の長所と短所
ルールベース機械翻訳の最大の利点は、その透明性と制御可能性にあります。翻訳の各ステップが明確に定義されているため、出力結果の解釈や修正が比較的容易です。また、特定の分野や文体に特化したルールを追加することで、専門的な文書の翻訳精度を向上させることができます。
さらに、この手法は大量の言語データ(コーパス)を必要とする統計的機械翻訳や、高度な計算能力を要するニューラル機械翻訳と比較して、計算量が少なく済むという利点があります。これは、リソースが限られた環境での使用に適しているということを意味します。
一方で、ルールベース機械翻訳には重大な欠点も存在します。最も顕著な問題は、言語表現の多様性や例外的な用法に柔軟に対応することが困難な点です。自然言語は複雑で曖昧さを含むため、全ての可能性を網羅するルールを作成することは事実上不可能です。そのため、特に口語表現や文学作品などの翻訳では、不自然な訳文が生成されることが少なくありません。
また、新しい表現や専門用語に対応するためには、常にルールや辞書を手動で更新する必要があります。これは非常に労力のかかる作業であり、翻訳システムの維持管理コストを押し上げる要因となります。
ルールベース機械翻訳の現代的位置づけ
現在の機械翻訳の主流は統計的手法やニューラル・ネットワークを用いた手法に移行していますが、ルールベース機械翻訳の考え方は完全に過去のものとなったわけではありません。特に、文法的な正確さが重視される法律文書や技術マニュアルなどの分野では、ルールベースのアプローチが依然として有効です。
また、最新の機械翻訳システムでは、ルールベースの手法を統計的手法やニューラル・ネットワークと組み合わせたハイブリッドアプローチが採用されることもあります。これにより、各手法の長所を生かしつつ、短所を補完することが可能となります。
ルールベース機械翻訳は、その限界が明らかになった今でも、機械翻訳の基礎を築いた重要な技術として認識されています。この手法の研究を通じて得られた言語処理に関する知見は、現代の高度な翻訳システムの開発にも大きく貢献しています。

