このシリーズでは物体検出でお馴染みの「YOLOv5」を用いて、物体検出の実装を基礎から学ぶことができます。
環境構築から学習の方法、さらに活用方法までをまとめています。
Google colabを使用して簡単に物体検出のモデルを実装することができますので、ぜひ最後までご覧ください。
第1回目である今回はチュートリアルに沿ってYOLOv5の導入と推論デモの実装を紹介します。
サンプル画像によるチュートリアルの推論デモを通して、YOLOv5の使い方を学びましょう。
今回の内容
・YOLOv5の概要
・YOLOv5に必要な環境構築
・サンプル画像によるチュートリアルの推論デモ
YOLOv5とは
YOLOv5は、YOLOv3の後継にあたり、2020年に公開されたモデルです。
YOLOv4という高精度化したYOLOv3の後継モデルもありますが、YOLOv5は推論処理時間がより速くなっているのが特徴です。
ベンチマーク結果を見ると、高性能であることがわかります。
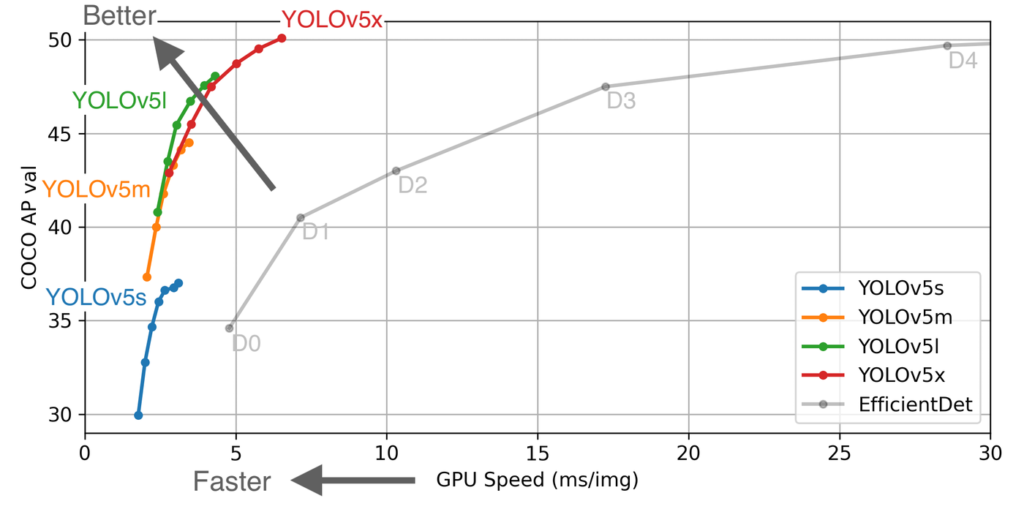
なお、YOLOv5は高性能ながら容易に実装することができます。
このシリーズではYOLOv5を使用して、物体検出の手法を習得していきましょう。
Google Colaboratoryの導入
ここからは、Google Colaboratoryを使用して物体検出の実装を行なっていきましょう。
Google Colaboratoryとは、ブラウザから Pythonのプログラミング を使うことができるサービスです。
通常、Pythonで処理を実行するに高性能なパソコンや種々の環境構築が必要となり、導入には費用や手間がかかるものとなっています。
一方、Google Colaboratoryを使うことで、面倒な設定をすることなく簡単にPythonを使うことができるようになります。
もちろん、無料で利用することができます。
まずはGoogleアカウントがない方は作成しましょう。
すでにお持ちの方は以下のリンクからGoogle Colaboratoryの設定を進めます。
https://colab.research.google.com/notebooks/welcome.ipynb?hl=ja
環境構築
Google colabを立ち上げて、早速実装していきましょう。
まずはGPUを使用できるように設定をします。
「編集」タブから「ノートブックの設定」の中の「ハードウェア アクセラレータ」を「GPU」に設定。
なお、今回紹介するコードは以下のボタンからコピーして使用していただくことも可能です。
![]()
まずはGoogle ドライブのファイルにアクセスするため、マウントします。
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive次にYOLOv5をクローンして、必要なライブラリをインポートします。
!git clone https://github.com/ultralytics/yolov5
%cd yolov5/
!pip install -qr requirements.txt以上で準備は完了です。
サンプル画像で物体検出を実装してみる
サンプル画像として「zidane.jpg」が用意されています。

この画像を使用して物体検出を実装してみましょう。
以下の通り実行すると、物体を検出することができます。
!python detect.py --source data/images/zidane.jpg結果は「yolov5/runs/detect/exp/zidane.jpg」として保存されます。
結果を表示してみましょう。
import matplotlib.pyplot as plt
img = plt.imread('runs/detect/exp/zidane.jpg')
plt.imshow(img)
plt.show()
無事に物体検出することができました。
物体検出結果の見方
物体検出結果の見方を紹介します。
それぞれ検出した範囲にBounding Box(矩形)で囲みます。
Bounding Boxの左上には検出した物体名と確信度が表示されます。
先程の結果では「person」となっていることから、人を検出できたことがわかります。
次に、「person」の横に確信度が表示されています。
これは物体検出の精度がどのくらい確実であるかの示す指標であり、0~1の間の値をとります。
この値が1に近いほど機械が自信を持って判定していることになります。
この指標に閾値を設定する処理を加えることで、検出の精度を自分で調整することができるようになります。
任意の画像で物体検出を実装してみる
今度は自分で用意した画像でも物体検出を実装してみましょう。
画像を用意したら、Googleドライブの中の「yolov5/data/images 」のフォルダ内に画像をアップします。
先ほど使用したサンプル画像の「zidane.jpg」も同じ場所にあることがわかります。
今回は「dog.jpg」をアップしました。
先ほどと同様にコードを実行します。
!python detect.py --source data/images/dog.jpg結果を表示してみます。
import matplotlib.pyplot as plt
img = plt.imread('runs/detect/exp2/dog.jpg')
plt.imshow(img)
plt.show()犬の画像からでも無事に検出できました。

ちなみにYOLOv5の学習済モデルでは「人」「自動車」「犬」など80種類の物体検出が可能です。
他の画像でも様々な物体検出ができますので、色々な画像で試してみてはいかがでしょうか。
まとめ
最後までご覧いただきありがとうございました。
今回はYOLOv5によりGoogle Colaboratory上で物体検出を実装しました。
実際に自分の手で試してみることで、物体検出への理解が深まったかと思います。
年々物体検出の実装は簡単になっており、様々なシーンで活用されています。
ぜひ、活用を検討されてみてはいかがでしょうか。
次回は、データセットを用いた学習について紹介します。
ぜひご覧ください。
🔰YOLOv5で実装する物体検出入門|第2回:マスク着用判定〜カスタムデータの学習〜
このシリーズでは物体検出でお馴染みの「YOLOv5」を用いて、物体検出の実装を基礎から学ぶことができます。 環境構築から学習の方法、さらに活用方法までをまとめています…