このシリーズでは物体検出でお馴染みの「YOLOv5」を用いて、物体検出の実装を基礎から学ぶことができます。
環境構築から学習の方法、さらに活用方法までをまとめています。
Google colabを使用して簡単に物体検出のモデルを実装することができますので、ぜひ最後までご覧ください。
第5回目はPyTorch hubによる物体検出テスト結果の出力方法と自作モデルのテスト方法について紹介します。
PyTorch hubを使ったYOLOv5による物体検出を試してみましょう。
今回の内容
・Torch hubのまとめ
・Torch hubの機能であるYouTube動画から物体検出する方法
YOLOv5の導入
Google colabを立ち上げて、早速実装していきましょう。
まずはGPUを使用できるように設定をします。
「編集」タブから「ノートブックの設定」の中の「ハードウェア アクセラレータ」を「GPU」に設定。
Google ドライブのファイルにアクセスするため、マウントします。
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive今回初めてYOLOv5を使用する方はクローンしましょう。
すでに前回クローンしている方は実行不要です。
!git clone https://github.com/ultralytics/yolov5必要なライブラリをインポートします。
%cd yolov5/
!pip install -qr requirements.txt以上で準備は終了です。
YOLOv5のためのTorch hubの基本操作(テスト)
PyTorch hubを使用することで、yolov5による物体検出を簡単に実装することができます。
公式は以下のリンクからご確認下さい。
まずはPyTorch hubによる物体検出を試してみましょう。
モデルと画像を指定するだけで簡単に実装できます。
画像はパスを指定するか、URLを指定しましょう。

import torch
# モデル
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# 画像
img = 'https://i0.wp.com/tt-tsukumochi.com/wp-content/uploads/2022/01/drive.jpg?w=2078&ssl=1'
# Inference
results = model(img)この結果に対する処理方法を順番に紹介します。
テスト結果の出力
まずはテスト結果を表示します。
results.print()
# image 1/1: 768x1024 7 persons, 3 trains, 1 traffic light
# Speed: 273.3ms pre-process, 75.8ms inference, 1.6ms NMS per image at shape (1, 3, 480, 640)検出された対象の検出数とラベル名が表示されます。
検出にかかった速度も見ることができます。
テスト結果を保存
テスト結果を保存します。
デフォルトでは「runs/detect」フォルダの中に「exp」フォルダが作成され、結果が保存されます。
results.save()
# Saved 1 image to runs/detect/exp
テスト結果を保存(保存先を指定)
出力先を指定して保存することもできます。
results.save(save_dir='runs/detect/car')
# Saved 1 image to runs/detect/carテスト結果の表形式出力
結果を表形式で出力します。
results.xyxy[0]
results.pandas().xyxy[0]| index | xmin | ymin | xmax | ymax | confidence | class | name |
|---|---|---|---|---|---|---|---|
| 0 | 875.2473754882812 | 327.3222351074219 | 1737.8250732421875 | 1120.9964599609375 | 0.9310059547424316 | 6 | train |
| 1 | 439.28424072265625 | 410.6086120605469 | 924.3189697265625 | 996.1290893554688 | 0.922091543674469 | 6 | train |
| 2 | 1856.3125 | 629.8081665039062 | 1901.7957763671875 | 747.9683227539062 | 0.7349188923835754 | 0 | person |
| 3 | 1907.376953125 | 628.1093139648438 | 1950.151611328125 | 746.6908569335938 | 0.7252894639968872 | 0 | person |
| 4 | 1955.5526123046875 | 630.6196899414062 | 1985.5224609375 | 726.0067749023438 | 0.7032561898231506 | 0 | person |
| 5 | 1926.7708740234375 | 564.2162475585938 | 2047.1478271484375 | 680.9027709960938 | 0.44237130880355835 | 6 | train |
| 6 | 1859.0142822265625 | 629.9708251953125 | 1952.890869140625 | 744.4647827148438 | 0.3407197594642639 | 0 | person |
| 7 | 1795.2630615234375 | 695.3111572265625 | 1834.2845458984375 | 742.4089965820312 | 0.3037204444408417 | 28 | suitcase |
| 8 | 1819.098876953125 | 629.0570678710938 | 1848.3270263671875 | 706.0908813476562 | 0.2795644700527191 | 0 | person |
| 9 | 1799.7734375 | 630.826171875 | 1827.2406005859375 | 691.7291259765625 | 0.26140284538269043 | 0 | person |
xmin,ymin,xmax,ymaxはそれぞれ物体の枠線の座標を表しています。
画像の左上が原点(0,0)である事に注意しましょう。
confidenceは検出の確信度であり、0~1の間で1に近いほど機械が自信を持って判定していることになります。

テスト結果のCSVファイル出力
上記の結果一覧をCSVファイルで出力することができます。
results.pandas().xyxy[0].to_csv('result.csv')テスト結果の切り抜き画像を保存
まずは先ほどのテスト結果をご覧ください。
この結果から検出された物体を切り抜くことができます。
crops = results.crop(save=True)「train」のクロップ画像を表示します。


テストの設定
テスト時の設定を変更することができます。
model.conf = 0.25 # NMS confidence threshold
iou = 0.45 # NMS IoU threshold
agnostic = False # NMS class-agnostic
multi_label = False # NMS multiple labels per box
classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
max_det = 1000 # maximum number of detections per image
amp = False # Automatic Mixed Precision (AMP) inference
results = model(imgs, size=320) # custom inference sizeYOLOv5のためのTorch hubの基本操作(その他)
デバイスの設定
モデル読み込み時にうまくいかなった際、既存のキャッシュを破棄しPyTorchHubから最新のYOLOv5バージョンを強制的にダウンロードすることで読み込みができるようになる場合があります。
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # force reloadモデルは作成後に任意のデバイスに転送できます
model.cpu() # CPU
model.cuda() # GPU
model.to(device) # i.e. device=torch.device(0)Youtube動画のテスト
図のようにYouTube上にある動画に対して物体検出を行ないます。
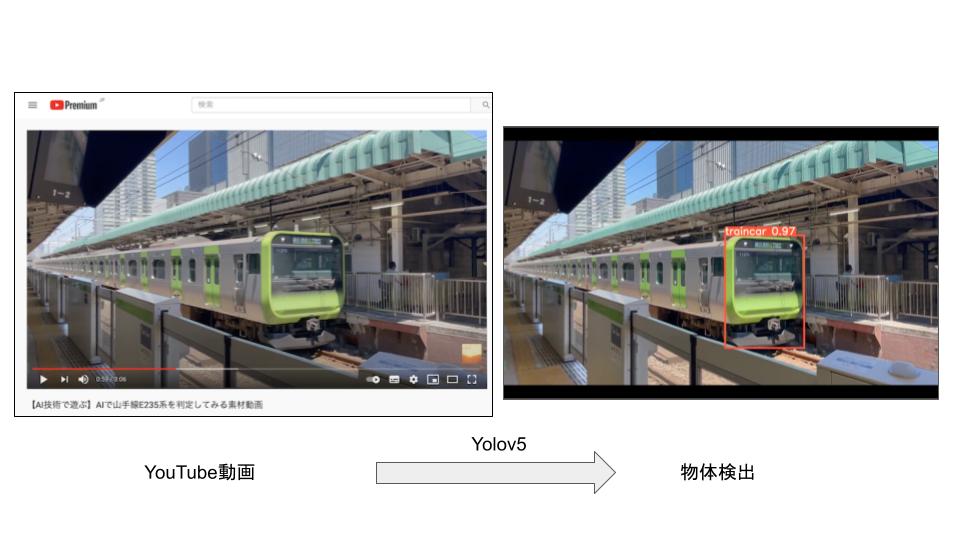
まずはソースとなる動画をご覧ください。
こちらの動画に対して物体検出を実装してみましょう。
以下のように動画のURLを引数に取ります。
!python detect.py --source 'https://youtu.be/igh_evKnkFk'処理が終わると動画として保存されます。
YouTube動画の物体検出ができました。
動画内の解析やデータ収集に役立ちそうですね。
なお、モデルや確信度閾値を指定することもできます。
!python detect.py --source 'https://youtu.be/igh_evKnkFk' --weights best.pt --conf 0.5まとめ
最後までご覧いただきありがとうございました。
今回はPyTorch hubによる物体検出テスト結果の出力方法について紹介しました。
次回の記事ではYOLOv5の活用方法を紹介していきます。
ぜひ、ご覧ください。

