このシリーズでは、自然言語処理において主流であるTransformerを中心に、環境構築から学習の方法までまとめます。
今回の記事ではHuggingface Transformersの入門として、データセットの基本的な扱い方を紹介します。
「datasets」ライブラリの実装を通じて、データセットの理解を深めましょう。
Google colabを使用して、簡単に最新の自然言語処理モデルを実装することができますので、ぜひ最後までご覧ください。
【前回】
【🔰Huggingface Transformers入門②】トークナイザーの概要と使い方
このシリーズでは、自然言語処理において主流であるTransformerを中心に、環境構築から学習の方法までまとめます。 今回の記事ではHuggingface Transformersの入門として…
今回の内容
・Huggingface Transformers Datasetsの導入
・Huggingface Transformers Datasetsの基本操作
・データセットの可視化
・ローカルのデータセットを使用する
- 1. huggingface datasets とは
- 1.1. Huggingface Transformersとは
- 1.2. Huggingface Transformers Datasetsとは
- 2. Huggingface Transformers Datasetsの導入
- 2.1. Google colabによる導入
- 2.2. Huggingface Transformersのデータセットの概要を確認
- 3. Huggingface Transformers Datasetsの基本操作
- 3.1. データセットの概要を確認
- 3.2. 「train」データの確認
- 3.3. データセットのN番目の内容を確認
- 3.4. データセットのデータ型を確認
- 4. データセットの可視化
- 4.1. 表形式で出力
- 4.2. データセットのラベルの分布を可視化する
- 4.3. 各データの単語数を可視化する
- 5. ローカルのデータセットを使用する
- 6. まとめ
huggingface datasets とは
Huggingface Transformersとは
Hugging Faceとは米国のHugging Face社が提供している、自然言語処理に特化したディープラーニングのフレームワークです。
Huggingface Transformersは「自然言語理解」と「自然言語生成」の最先端の汎用アーキテクチャ(BERT、GPT-2など)と、何千もの事前学習済みモデルを提供しており、Transformerによる自然言語処理を簡単に実装することができます。
Huggingface Transformers Datasetsとは
Huggingface Transformersでは学習済みモデルだけでなく、自然言語処理に関する言語のデータセットを提供しています。
学習を実装する際には多くのデータが必要となりますが、公開されているものを活用することで、すぐに学習を実装することができます。
このデータセットを簡単に扱えるようにするライブラリが「huggingface datasets 」です。
コードを実行するたびに前処理をやり直す必要がなくなるキャッシュ機能やメモリ制限を回避するメモリマッピングという機能を備えています。
Hugging Face:https://huggingface.co
Hugging Face datasets :https://huggingface.co/datasets
Huggingface Transformers Datasetsの導入
Google colabによる導入
ここからはGoogle colabを使用して実装していきます。
今回紹介するコードは以下のボタンからコピーして使用していただくことも可能です。
![]()
まずはGoogleドライブをマウントして、作業フォルダを作成します。
from google.colab import drive
drive.mount('/content/drive')
!mkdir -p '/content/drive/My Drive/huggingface_transformers_demo/'
%cd '/content/drive/My Drive/huggingface_transformers_demo/'!git clone https://github.com/huggingface/transformers
%cd transformers「datasets」ライブラリをインストールします。
!pip install datasetsHuggingface Transformersのデータセットの概要を確認
まずはどんなデータセットがあるのかを表示してみます。
from datasets import list_datasets
all_datasets = list_datasets()
print(f"There are {len(all_datasets)} datasets currently available on the Hub")
print(f"The first 10 are: {all_datasets[:10]}")実行すると、以下のように表示されます。
There are 11347 datasets currently available on the Hub
The first 10 are: ['acronym_identification', 'ade_corpus_v2', 'adversarial_qa', 'aeslc', 'afrikaans_ner_corpus', 'ag_news', 'ai2_arc', 'air_dialogue', 'ajgt_twitter_ar', 'allegro_reviews']この記事の執筆時点では、公開されているデータセットは11,347セットあることがわかりました。
また、最初の10件のデータセット名を取得しています。
Huggingface Transformers Datasetsの基本操作
データセットの概要を確認
ここからは「emotions」というデータセットを読み込んで、情報を見ていきます。
このデータセットは感情検出器作成のため、英語のツイートに対して、どのような感情表現に分類されるかを調査した論文のデータセットです。
分類器作成のデータのため、ツイート(文章)とそれに対する6種類の感情(['sadness', 'joy', 'love', 'anger', 'fear', 'surprise'])がラベルとして与えられています。
まずは表示してみましょう。
from datasets import load_dataset
emotions = load_dataset("emotion")
emotions実行すると、以下のように表示されます。
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 16000
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
})「train」が16000件、「validation」と「test」が2000件のデータで構成されていることがわかります。
「train」データの確認
次に「train」の詳細を確認します。
train_ds = emotions["train"]
train_ds
len(train_ds)実行すると、以下のように表示されます。
Dataset({
features: ['text', 'label'],
num_rows: 16000
})
16000辞書形式のように、データを取り出すことができます。
先ほど確認したように、trainデータは16000件です。
「validation」と「test」も同様に扱うことができます。
データセットのN番目の内容を確認
インデックスを指定すると、N番目のデータの取得することができます。
train_ds[0]
train_ds.column_names実行すると、以下のように表示されます。
{'text': 'i didnt feel humiliated', 'label': 0}
train_ds.column_names1つの行が辞書として表現され、キーが列名に対応していることがわかります。
データセットのデータ型を確認
データセット内のデータの型を確認することができます。
print(train_ds.features)実行すると、以下のように表示されます。
{'text': Value(dtype='string', id=None), 'label': ClassLabel(num_classes=6, names=['sadness', 'joy', 'love', 'anger', 'fear', 'surprise'], id=None)}このデータセットは['sadness', 'joy', 'love', 'anger', 'fear', 'surprise']の6種類の感情のラベル付けがされていることが確認できました。
データセットの可視化
次にデータセットの可視化について紹介します。
表形式で出力
まずは、先ほどのデータセットを表形式で出力してみます。
import pandas as pd
from datasets import load_dataset
emotions = load_dataset("emotion")
emotions.set_format(type="pandas")
df = emotions["train"][:]
df.head()実行すると、以下のように表示されます。
| index | text | label |
|---|---|---|
| 0 | i didnt feel humiliated | 0 |
| 1 | i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake | 0 |
| 2 | im grabbing a minute to post i feel greedy wrong | 3 |
| 3 | i am ever feeling nostalgic about the fireplace i will know that it is still on the property | 2 |
| 4 | i am feeling grouchy | 3 |
データセットを表形式で出力することができました。
なお、データのラベルの整数値に対応するラベル名を合わせて出力することもできます。
def label_int2str(row):
return emotions["train"].features["label"].int2str(row)
df["label_name"] = df["label"].apply(label_int2str)
df.head()実行すると、以下のように表示されます。
| index | text | label | label_name |
|---|---|---|---|
| 0 | i didnt feel humiliated | 0 | sadness |
| 1 | i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake | 0 | sadness |
| 2 | im grabbing a minute to post i feel greedy wrong | 3 | anger |
| 3 | i am ever feeling nostalgic about the fireplace i will know that it is still on the property | 2 | love |
| 4 | i am feeling grouchy | 3 | anger |
データセットのラベルの分布を可視化する
今回例にしている「emotions」というデータセットは6種類のラベルで構成されています。
このラベルの分布を可視化することができます。
import matplotlib.pyplot as plt
df["label_name"].value_counts(ascending=True).plot.barh()
plt.title("Frequency of Classes")
plt.show()実行すると、以下のように表示されます。
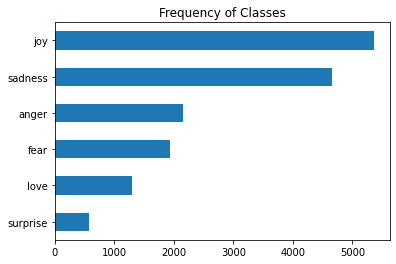
データセット内のラベルの分布が可視化されました。
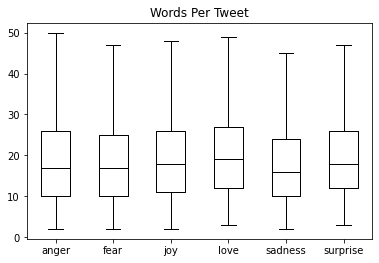
各データの単語数を可視化する
データセット内の各データの単語数をカウントして、表示してみます。
df["Words Per Tweet"] = df["text"].str.split().apply(len)
df.boxplot("Words Per Tweet", by="label_name", grid=False, showfliers=False,
color="black")
plt.suptitle("")
plt.xlabel("")
plt.show()実行すると、以下のように表示されます。
ローカルのデータセットを使用する
Huggingface TransformersのDatasetsに登録されていないデータセットの扱いについて紹介します。
他所で公開されているデータセットや自作したデータセットも同様に使用することができます。
CSVファイル、JSONファイル、TEXTファイルの使用例を以下に示します。
from datasets import load_dataset
#CSVファイルを読み込む
dataset = load_dataset('csv', data_files='test.csv')
#複数のCSVファイルを読み込む
dataset = load_dataset('csv', data_files=['test1.csv', 'test2.csv'])
#JSONファイルを読み込む
dataset = load_dataset('json', data_files='test.json')
#TEXTファイルを読み込む
dataset = load_dataset('text', data_files={'train': ['test1.txt', 'tese2.txt'], 'test': 'test3.txt'})ここでは具体的な実装例は紹介しませんが、各タスクの学習時において、データの読み込む方法を紹介しています。
詳しくは、下のリンクの「自然言語処理まとめ」から、興味があるタスクの学習方法に関する記事を参照してください。
まとめ
最後までご覧いただきありがとうございました。
今回の記事ではHuggingface Transformersの入門として、データセットの基本的な扱い方を紹介しました。
次回はパイプラインによるタスクを紹介します。
このシリーズでは、自然言語処理全般に関するより詳細な実装や学習の方法を紹介しておりますので、是非ご覧ください。
【次回】
【🔰Huggingface Transformers入門④】 pipelineによるタスク実装紹介
このシリーズでは、自然言語処理において主流であるTransformerを中心に、環境構築から学習の方法までまとめます。 今回の記事ではHuggingface Transformersの入門として…