EfficientNetV2によりGoogle Colaboratory上で画像分類を実装していく手順をまとめます。
今回の方法ではGoogleアカウントがあれば誰でも同じように試すことが可能です。
画像認識について名前は聞いたことがあるがよくわからない方、これから学習してみたい方は最後までぜひご覧ください。
今回の目標
今回は、EfficientNetV2による画像分類の実装を紹介します。
実装を通じて画像分類の概要を学びましょう。
今回の内容
・画像分類の概要を学ぶ
・画像分類モデルを実装する
画像分類とは
画像分類とは与えられた画像から特徴をつかみ、対象物を識別するパターン認識技術の一つです。
例えば、画像に映っている物体は何であるかという判断を機械に行わせ、画像を認識させます。
画像認識ではコンピュータに大量の画像を与え、対象物の特徴をコンピュータに自動的に「学習」させます。
画像データから犬の特徴を「理解」し、同じ特徴を持った画像を「犬」だと推測することができるようになります。
近年この画像認識の分野はAIにおける深層学習(ディープラーニング)技術の向上により、急速に発展しました。
EfficientNetV2とは
画像分類の分野では世界中で研究が盛んに行われており、毎年のように新しいモデルが公開されています。
2019年以降に絞ってみても、EfficientNet, Big Transfer, Vision Transformerなど数多くのモデルが提案され、当時最高の予測精度が報告されてきました。今回はその中でも、従来手法より軽量でかつ高精度なモデルであるEfficientNetV2です。
どれくらい高精度なのか定量的に観察してみることにします。
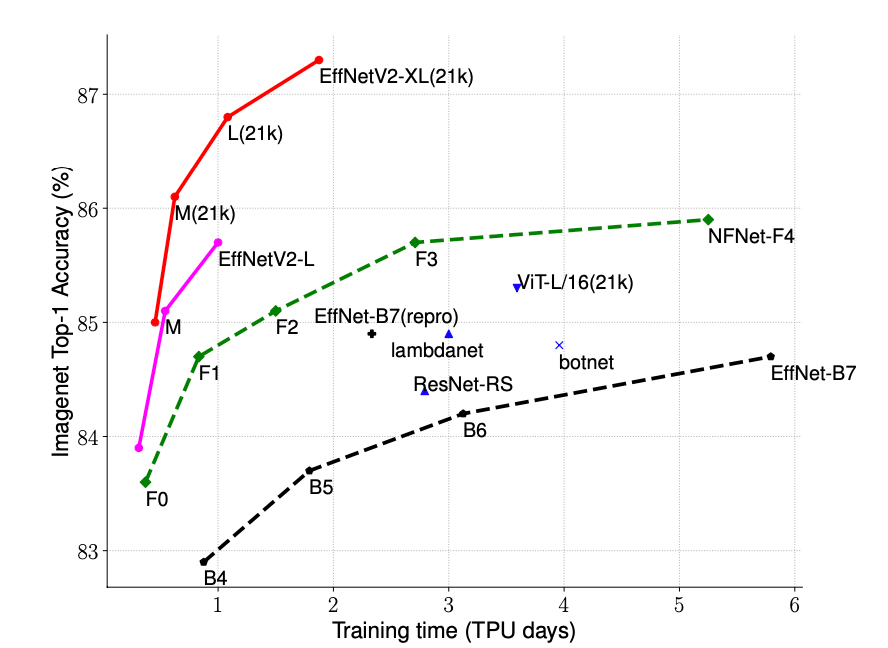
以下にグラフを示します。
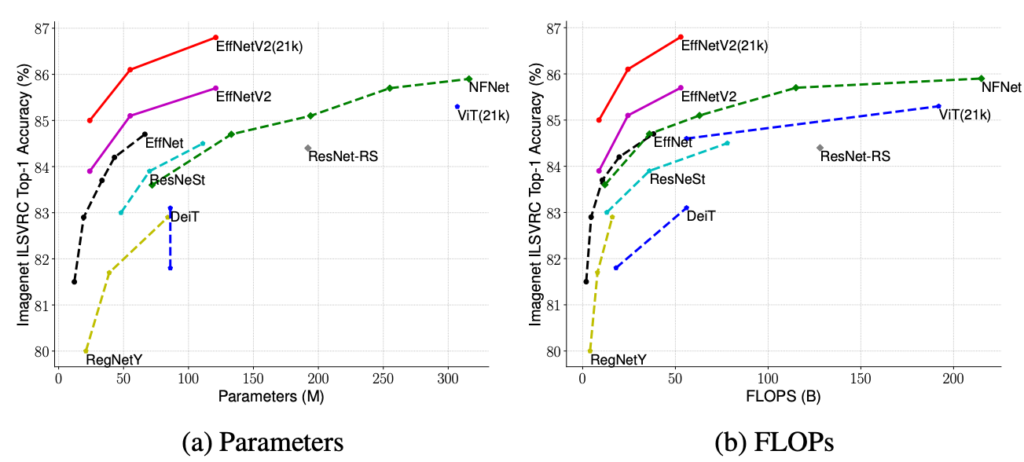
縦軸はモデルの精度であり、上に行くほど精度がいいということになります。
横軸はTPUを使用した場合、モデル作成にどれくらいの日数が必要であるかを示しています。
多くのデータ量を扱う深層学習では、学習時間が短いということも大事な要素となります。
グラフからは今回使用するEfficientNetV2は高精度かつ短時間で学習可能であることがわかります。
Google Colaboratoryの導入
ここからは、実際に画像分類の実装を行なっていきましょう。
今回使用するGoogle Colaboratoryとは、ブラウザから Pythonのプログラミング を使うことができるサービスです。
通常、Pythonで処理を実行するに高性能なパソコンや種々の環境構築が必要となり、導入には費用や手間がかかるものとなっています。
一方、Google Colaboratoryを使うとことで、面倒な設定をすることなく簡単にPythonを使うことができるようになります。
もちろん、無料で利用することができます。
まずはGoogleアカウントを作成しましょう。すでにお持ちの方は以下のリンクからGoogle Colaboratoryの設定を進めます。
https://colab.research.google.com/notebooks/welcome.ipynb?hl=ja
Google Colaboratoryの設定
まずはGoogle Colaboratoryを起動してください。
「ファイル」タブから「ノートブックを新規作成」を押して、新しいノートブックを準備します。
また、「編集」タブから「ノートブックの設定」の中の「ハードウェア アクセラレータ」を「TPU」に設定します。
以上で設定が完了しました。
EfficientNetV2の準備
ここからは実際にコードを実行して、画像認識を進めていきます。
以下のコードをそのままコピペして実行して、画像分類を実装していきましょう。
まずはGoogle Colaboratory上で今回使用するフォルダを作成します。
フォルダ名を変えることも可能ですので、お好みで変更してください。
test_dir = '/content/tmp'
!mkdir $test_dir
%cd $test_dir次にEfficientNetV2で必要な関数を定義します。
合わせて使用するモデルを指定しますが、ここでは最も高性能である「efficientnetv2-xl」を使用することにします。
import itertools
import os
import matplotlib.pylab as plt
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
print('TF version:', tf.__version__)
print('Hub version:', hub.__version__)
print('Phsical devices:', tf.config.list_physical_devices())
def get_hub_url_and_isize(model_name, ckpt_type, hub_type):
ckpt_type = '-' + ckpt_type
hub_url_map = {
'efficientnetv2-xl-21k-ft1k': f'gs://cloud-tpu-checkpoints/efficientnet/v2/hub/efficientnetv2-xl-21k-ft1k/{hub_type}',
}
image_size_map = {
'efficientnetv2-xl': 512,
}
hub_url = hub_url_map.get(model_name + ckpt_type)
image_size = image_size_map.get(model_name, 224)
return hub_url, image_size
def get_imagenet_labels(filename):
labels = []
with open(filename, 'r') as f:
for line in f:
labels.append(line.split('\t')[1][:-1]) # split and remove line break.
return labels
チュートリアルで画像分類
いよいよチュートリアルで画像分類を実行します。画像も公式で用意されているものを使用します。
import tensorflow_hub as hub
model_name = 'efficientnetv2-xl'
ckpt_type = '21k-ft1k'
hub_type = 'classification'
hub_url, image_size = get_hub_url_and_isize(model_name, ckpt_type, hub_type)
tf.keras.backend.clear_session()
m = hub.KerasLayer(hub_url, trainable=False)
m.build([None, 224, 224, 3]) # Batch input shape.
labels_map = '/tmp/imagenet1k_labels.txt'
image_file = '/tmp/panda.jpg'
tf.keras.utils.get_file(image_file, 'https://upload.wikimedia.org/wikipedia/commons/f/fe/Giant_Panda_in_Beijing_Zoo_1.JPG')
tf.keras.utils.get_file(labels_map, 'https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/v2/imagenet1k_labels.txt')画像を読み込んで、予測結果を出力します。
image = tf.keras.preprocessing.image.load_img(image_file, target_size=(224, 224))
image = tf.keras.preprocessing.image.img_to_array(image)
image = (image - 128.) / 128.
logits = m(tf.expand_dims(image, 0), False)
pred = tf.keras.layers.Softmax()(logits)
idx = tf.argsort(logits[0])[::-1][:5].numpy()
classes = get_imagenet_labels(labels_map)
for i, id in enumerate(idx):
print(f'top {i+1} ({pred[0][id]*100:.1f}%): {classes[id]} ')
from IPython import display
display.display(display.Image(image_file))
top 1 (95.1%): giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca
top 2 (0.1%): indri, indris, Indri indri, Indri brevicaudatus
top 3 (0.1%): lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens
top 4 (0.1%): king snake, kingsnake
top 5 (0.1%): skunk, polecat, wood pussy 無事に画像と予測結果が出力されました。
今回は画像に何が写っているか、Top5を出力するようにしています。
結果を見ると、「top 1 (95.1%): giant panda」となっています。
95.1%の確率でジャイアントパンダであると予測していますので正解であることがわかります。
今回のように、モデルの精度が高い場合はTop1以外の結果は確信度が低くなります。
好きな画像で画像分類してみる
ここから任意の画像で画像分類を試してみます。まずはお好きな画像をご用意ください。
画面左にあるフォルダアイコンを開いたら、tmp を選択して、画像をアップロードします。
今回は「test1.jpg」をアップしてから、先ほどと同様にコードを実行します。
画像の名前はご自身でアップしたものに適宜変更してください。
変更箇所は以下のコードで「test1.jpg」となっている箇所です。
tf.keras.utils.get_file(
fname = '/content/tmp/test1.jpg',
origin = '/content/tmp/test1.jpg',
)
image = tf.keras.preprocessing.image.load_img(image_file, target_size=(224, 224))
image = tf.keras.preprocessing.image.img_to_array(image)
image = (image - 128.) / 128.
logits = m(tf.expand_dims(image, 0), False)
pred = tf.keras.layers.Softmax()(logits)
idx = tf.argsort(logits[0])[::-1][:5].numpy()
classes = get_imagenet_labels(labels_map)
for i, id in enumerate(idx):
print(f'top {i+1} ({pred[0][id]*100:.1f}%): {classes[id]} ')
from IPython import display
display.display(display.Image(image_file))
top 1 (96.9%): lakeside, lakeshore
top 2 (0.3%): breakwater, groin, groyne, mole, bulwark, seawall, jetty
top 3 (0.3%): seashore, coast, seacoast, sea-coast
top 4 (0.1%): park bench
top 5 (0.1%): boathouse 同様に画像と予測結果が出力されたかと思います。
今回使用した箇所は千葉県の公園の画像です。
先ほどと同様に画像に何が写っているか、Top5を出力するようにしています。
結果を見ると、「top 1 (96.9%): lakeside, lakeshore」となっています。
96.9%の確率で湖畔であると予測する結果となりした。(画像は東京湾ですが…)
まとめ
最後までご覧いただきありがとうございました。
今回はEfficientNetV2による画像分類の実装を紹介しました。
実際に自分の手で試してみることで、画像認識への理解が深まったかと思います。
年々画像認識の実装は簡単になっており、様々なシーンで活用されています。
このブログでは様々な手法の実装方法を紹介していますので、ぜひご覧ください。
