このシリーズではE資格対策として、書籍「ゼロから作るDeep Learning」を参考に学習に役立つ情報をまとめています。
<参考書籍>
パディング
畳み込み演算の一部として行われるパディングとは、主に画像データなどのマトリクスに対し、境界部分に特定の値(通常は0)を追加して元のマトリクスを囲む操作のことを指します。この操作は特に、ディープラーニングや画像処理のコンボリューション(畳み込み)ニューラルネットワーク(CNN)において一般的です。
パディングの主なメリットは以下の通りです:
- 情報の損失の防止: 畳み込み操作では、入力のマトリクスの端部はカーネル(またはフィルタ)による探索の対象となる回数が中心部に比べて少なくなるため、情報が失われやすいです。パディングを行うことで、これらの端部の情報が次のレイヤーにもしっかりと伝播することを確保します。
- 出力サイズの制御: パディングなし(valid padding)の畳み込みでは、カーネルのサイズによっては出力のサイズが入力のサイズよりも小さくなってしまいます。これを避け、出力のサイズを入力のサイズと一致させたい場合(same padding)、パディングが有用です。
- 畳み込みの自由度の向上: パディングにより、カーネルを元のデータの任意の位置に配置して畳み込むことが可能になります。これにより、畳み込みの自由度が増し、より豊かな特徴抽出が可能となります。
パディングの種類
畳み込みネットワーク(CNN)におけるパディングの種類は、データの性質や問題設定により変わります。以下に具体的な例を交えて解説します:
- "Same" と "Valid" パディング:"Same"パディングは、出力のサイズを入力のサイズと同じに保つためのパディング方法です。例えば、入力が画像であり、その全体の特徴を保持しながら畳み込みを行いたい場合には、"Same"パディングが適しています。一方、"Valid"パディングはパディングを行わない方法で、出力は入力よりも小さくなります。これは情報のダウンサンプリングが必要な場合や、過度なパディングによる過学習を避けたい場合に適しています。
- パディングの量:パディングの量も重要な要素です。パディングが多すぎると、モデルがパディングされた部分(通常はゼロ)に過度に依存する可能性があり、これが過学習を引き起こす可能性があります。一方、パディングが少なすぎると、入力の端部の情報が失われてしまい、モデルの性能が低下する可能性があります。これは特に、端部の情報が重要な役割を果たす画像認識や自然言語処理などのタスクにおいて問題となります。
- パディングの種類:一般的にはゼロパディングが使われますが、場合によっては他の種類のパディングが有用な場合があります。例えば、鏡像パディング(入力の端部を反転したものをパディングとして使用する)は、画像の端部近くで高頻度の情報を保持することが必要な場合に有用です。もう1つのパディング方法は、エッジパディング(入力の端部の値をコピーしてパディングとして使用する)で、これは画像の端部の情報がそのまま重要な場合に適しています。
パディングの実装
PythonのNumPyライブラリを使って2次元配列の畳み込み演算を行うコードを以下に示します。ここでは、配列を0でパディングしてから3x3のカーネルで畳み込みを行います。
import numpy as np
# 入力の2次元配列
input_array = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]])
# カーネル
kernel = np.array([[0, 1, 0],
[1, -4, 1],
[0, 1, 0]])
# パディング
padded_array = np.pad(input_array, pad_width=1, mode='constant', constant_values=0)
# 畳み込み後の結果を格納する2次元配列
output_array = np.zeros_like(input_array)
# 畳み込み演算
for i in range(output_array.shape[0]):
for j in range(output_array.shape[1]):
output_array[i, j] = np.sum(padded_array[i:i+3, j:j+3] * kernel)
print(output_array)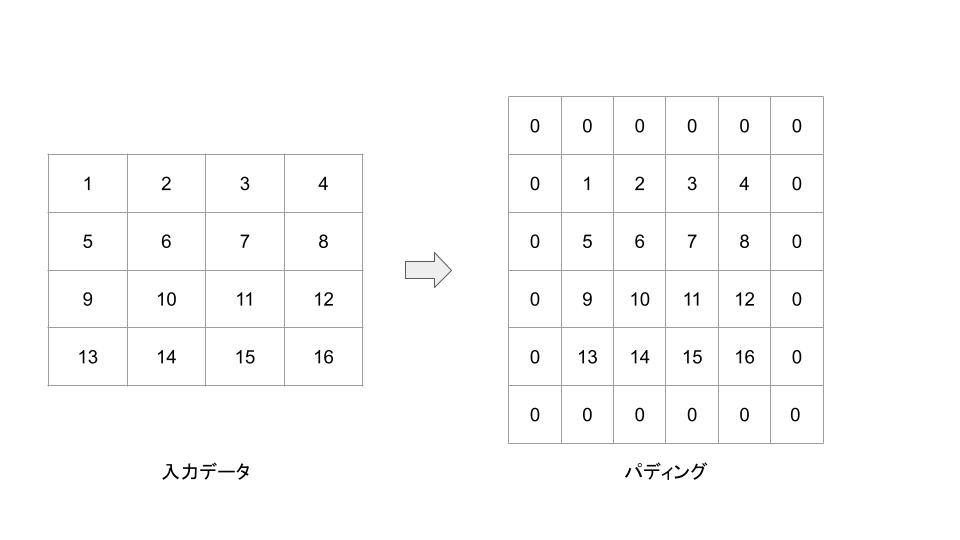
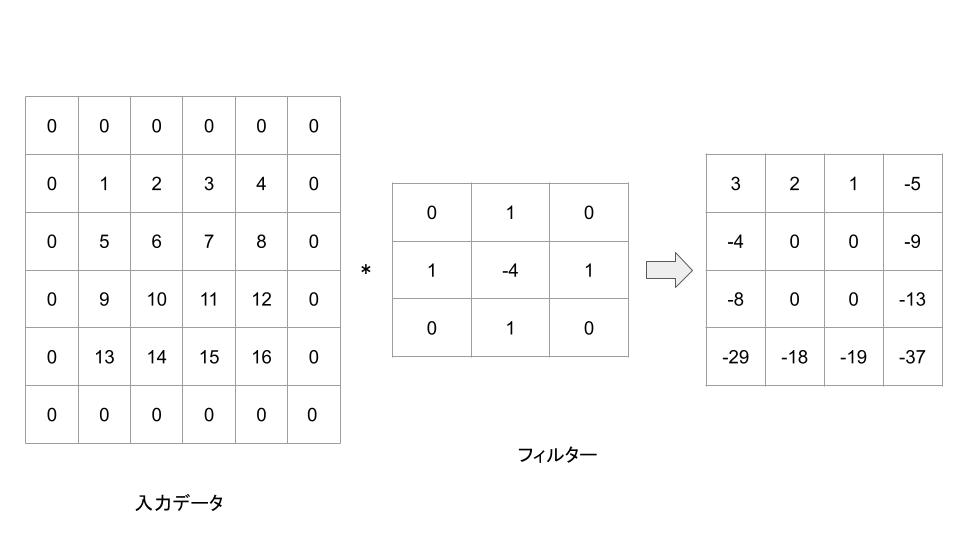
実行結果:
[[ 3 2 1 -5]
[ -4 0 0 -9]
[ -8 0 0 -13]
[-29 -18 -19 -37]]ストライド
畳み込み演算では、入力データ(一般的には画像やそれに類似する2次元または3次元データ)に対してフィルタまたはカーネルを適用します。このフィルタを入力データ上で移動させて各位置での畳み込みを計算しますが、この移動する際のステップ幅がストライドです。
たとえば、ストライドが1の場合、フィルタは入力データ上で1ピクセルごとに移動します。ストライドが2の場合は、2ピクセルごとに移動します。
ストライドを大きくすると、出力データ(畳み込み後の特徴マップ)のサイズは小さくなります。これは、大きいストライドではフィルタが入力データの一部しかカバーしないためです。一方で、ストライドを小さくすると、出力データのサイズは大きくなります。
また、ストライドを変更することは、モデルの容量(パラメータの数)を変更せずに、計算量を減らす一方で、特徴マップの解像度を低下させる効果があります。これは、特に大規模なディープラーニングモデルでの計算効率を上げるために使用されるテクニックです。
出力サイズの計算方法
出力サイズの計算方法は以下の通りです。ここでは、入力サイズを(I_w, I_h)、フィルターサイズを(F_w, F_h)、パディングをP、ストライドをSとします。
出力の幅および高さ(出力サイズ)は次の式を用いて計算できます:
O_w = (I_w - F_w + 2P) / S + 1
O_h = (I_h - F_h + 2P) / S + 1
ここで、
- I_wとI_hは入力画像の幅と高さです。
- F_wとF_hはフィルタ(またはカーネル)の幅と高さです。
- Pはパディングの量で、入力画像の周りに追加される0のレイヤーの数です。
- Sはストライドの量で、フィルタが入力画像を通過する際のステップの大きさです。
この計算は、入力画像が正方形である場合、またはフィルタが正方形である場合に最もよく使用されます。非正方形の画像またはフィルタについては、幅と高さで個別に計算を行います。
ただし、上記の式は出力サイズが整数になることを前提としています。出力サイズが整数でない場合(つまり、フィルタが入力に完全にフィットしない場合)、通常は出力サイズを下に丸めるか、入力やフィルタのパラメータを調整して整数になるようにします。
ストライドの実装
import numpy as np
# 入力の2次元配列を定義します。
input_array = np.array([[0, 1, 2, 0, 1, 2, 0],
[2, 0, 1, 2, 0, 1, 2],
[1, 2, 0, 1, 2, 0, 1],
[0, 1, 2, 0, 1, 2, 0],
[2, 0, 1, 2, 0, 1, 2],
[1, 2, 0, 1, 2, 0, 1],
[0, 1, 2, 0, 1, 2, 0]])
# 3x3のカーネルを定義します。
kernel = np.array([[0, 1, 2],
[2, 0, 1],
[1, 2, 0]])
# ストライドの値を定義します。
stride = 2
# 出力のサイズを計算します。
output_size = (input_array.shape[0] - kernel.shape[0]) // stride + 1
# 出力の2次元配列を初期化します。
output_array = np.zeros((output_size, output_size))
# 畳み込み演算を実行します。
for i in range(0, input_array.shape[0] - kernel.shape[0] + 1, stride):
for j in range(0, input_array.shape[1] - kernel.shape[1] + 1, stride):
output_array[i // stride][j // stride] = np.sum(input_array[i:i+kernel.shape[0], j:j+kernel.shape[1]] * kernel)
print(output_array)実行結果:
[[15. 6. 6.]
[ 6. 15. 6.]
[ 6. 6. 15.]]まとめ
最後までご覧いただきありがとうございました。

