このシリーズではE資格対策として、シラバスの内容を項目別にまとめています。
ResNet
ResNetの概要
ResNet、または残差ネットワークは、2015年にKaiming Heらによって提案された深層学習のモデルです。このネットワークは、深いニューラルネットワークの学習における一般的な問題である勾配消失問題を解決するために開発されました。
これまでモデルでは、ネットワークの層を深くすることで性能を向上させる試みが行われていました。しかし、層を増やすほど、勾配消失の問題が発生し、学習が困難になるという課題がありました。勾配消失は、ネットワークが深くなると逆伝播の際に勾配が小さくなってしまい、重みの更新がほとんど行われなくなる現象です。
この問題を解決するために、ResNetはスキップ接続という独特の構造を採用しています。これは、ある層の入力を直接、それより上位の層の出力に加算する方法で、深いネットワークでも効率的に学習が進行するように設計されています。
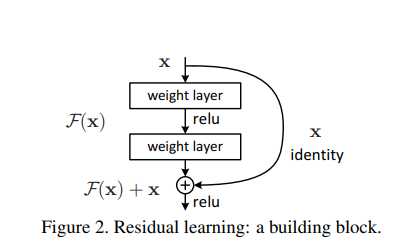
具体的には、ResNetでは各層で残差関数を学習します。入力値をx、従来のCNNの出力をH(x)とした場合、ResNetではF(x)=H(x)−xを学習し、xとF(x)を加算します。この方法により、重みの更新もF(x)を出力するように学習され、勾配消失問題が解消されます。
この画期的なアプローチにより、100層以上のネットワークを構成できるようになり、画像認識の精度が向上しました。実際に、ResNetは2015年に開催されたILSVRCのImageNetコンペティションで152層のネットワークを重ね、優勝モデルとなりました。
ResNetのアイデアはシンプルながら、深層学習の多くの課題を解決しました。コンピュータの計算力の向上とインフラの発展により、更に深いネットワークの訓練が可能となりましたが、ResNetの登場が、より深いネットワークの訓練を実現し、更に精度を向上させる重要な一歩となりました。
残差ブロック(Residual Block)
残差ブロックは、ResNetの核となる部分で、このブロックを繰り返し組み合わせることでネットワーク全体が形成されます。
- 畳み込み層とSkip Connection
残差ブロックは主に2つの枝から構成されており、一方の枝は畳み込み層の組み合わせで、もう一方の枝はIdentity関数となります。これらの枝の出力を足し合わせることで、新しい特徴が形成されます。 - Bottleneckアーキテクチャ
通常の残差ブロックとは別に、Bottleneckアーキテクチャと呼ばれる構造も存在します。この構造では、1×1と3×3のConvolution層を用いて出力のDepthの次元を小さくしてから、最後の1×1のConvolution層でDepthの次元を復元します。これにより、同等の計算コストで、より多くの層を持つことが可能になります。 - 信号の逆方向の伝播
従来のネットワークでは、信号が逆方向に送られる際に勾配が特定の関数を通過する必要がありましたが、ResNetでは、入力を直接出力に加える形でショートカットを形成します。この構造は数式でH(x)=F(x)+xと表され、入力xと畳み込み層などの出力F(x)を足し合わせる形になります。
この“+ x”がショートカットを意味し、残差学習を可能にします。つまり、手前の層で学習できなかった誤差の部分を次の層で学習することが可能になり、結果として層の深度を増やすことなく、精度の向上が図られます。
ResNetの種類
- ResNet-18: 18層のアーキテクチャで、シンプルなタスクに使われることが多い。
- ResNet-34: 34層の構造を持ち、中程度の複雑なタスクに適しています。
- ResNet-50, ResNet-101, ResNet-152: これらはそれぞれ50層、101層、152層の構造を持ち、非常に複雑なタスクや大規模なデータセットに使用されます。
WideResNet
WideResNetの概要
WideResNetは、ニューラルネットワークの深さ(層の数)と幅(各層のチャネル数)をうまく組み合わせることで、計算効率と性能の向上を目指すモデルです。以下は、その概要と特性についての解説です。
深いネットワークが強力である一方で、勾配消失問題などの学習上の課題があります。浅いネットワークでは、深いネットワークに比べて多くのコンポーネントが必要になる可能性があります。このバランスを取るために、ResNetはResidual BlockとIdentity mappingを導入しました。しかし、これによって「特徴再利用の減少」という問題が生じました。
WideResNetのアプローチは、この問題を解決するためのもので、Residual Block内の畳み込み層のチャネル方向を広げるという戦略を採用しています。具体的には、層の深さを減らし、チャネル方向の幅を増やすことで、計算効率の向上を図りました。さらに、ブロック内にドロップアウトを加えることで性能の向上も実現しました。
この幅を広げる方針は、ResNetのボトルネックブロックの導入をさらに進化させたもので、層を深くするだけでなく、その幅も適切に広げることで、性能と効率のバランスを改善しました。このアプローチによって、深さと幅の間のトレードオフをうまく調整し、高い計算効率と良好な性能を同時に達成することができたのです。
WideResNetの構成
まず、WideResNetでの改良の方針として、3つの方法が考えられました。
- ブロックにより多くの畳み込み層を加える。
- より多くの特徴平面を加えることで畳み込み層を広げる。
- 畳み込み層のフィルターサイズを大きくする。
このうち、3つ目のフィルターサイズを大きくする方法は、小さいフィルターの方が効率的であるとの理由から採用されませんでした。したがって、3x3よりも大きいフィルターサイズは利用されていません。
WideResNetの主な特徴は、残差ブロック(Residual Block)内に多くの畳み込み層を加えると共に、特徴平面(チャネル数)を増やして畳み込み層を広げることにより、表現力を向上させています。ここで、「l」は畳み込みの数、「k」は特徴平面の数(チャネル数)をk倍すること、「B(M)」はResidual Blockを、「M」はブロック内の畳み込み層のカーネルサイズのリストを表します。
WideResNetの表記「WRN-n-k」は、n層の畳み込みを持ち、幅(チャネル数)をk倍することを意味します。パラメータの数と計算量はkの二乗になる関係で、k=1のときは元のResNetと同一となり、k>1のときにWideResNetとなります。
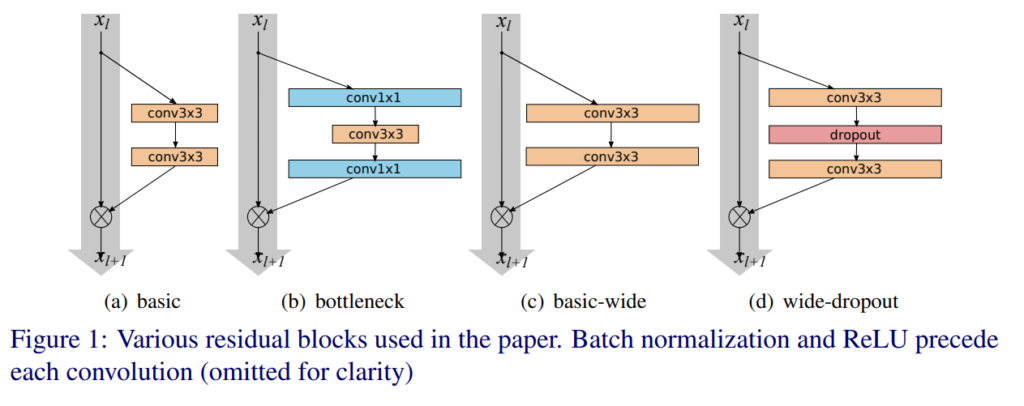
この構成により、以下の結論が導かれています。
- 異なる深さでも、幅を広げることで性能の改良が可能です。
- パラメータの数が多くなりすぎるまで、幅と深さを増やすことが有効に働くとされています。
- 通常のResNetと比較して、WideResNetはより良い表現を学習できるとともに、計算量の増大が抑えられ、効率よく学習できるとされています。
まとめ
最後までご覧いただきありがとうございました。
