このシリーズではE資格対策として、シラバスの内容を項目別にまとめています。
オートエンコーダ
オートエンコーダの概要
オートエンコーダ(Autoencoder)は、ニューラルネットワークの一種で、入力データをより低い次元に圧縮(エンコード)し、その圧縮された表現から元のデータを再構築(デコード)するモデルです。オートエンコーダは、エンコーダとデコーダの2つの主要な部分から構成されます。オートエンコーダの背景には、データの次元削減や特徴抽出の必要性があります。高次元のデータを扱う際に、無駄な情報を削除し、データの本質的な特徴を捉えることが求められるため、オートエンコーダは非常に重要な役割を果たしています。
オートエンコーダの応用分野は多岐にわたります。以下はその主な例です。
- 画像の圧縮: オートエンコーダは、画像データを効率的に圧縮し、元の画像を可能な限り忠実に再構築するために使用されます。
- 異常検知: 正常なデータのみを使用してオートエンコーダを訓練すると、異常なデータはうまく再構築できないため、異常検知に応用されます。
- 特徴抽出: 圧縮された表現 z は、元のデータの重要な特徴を捉えるため、分類など他のタスクでの特徴として使用することができます。
オートエンコーダはこれらの応用だけでなく、生成モデル、強化学習など、多岐にわたる分野で使用されています。
オートエンコーダの構造
オートエンコーダの構造はエンコーダとデコーダの2つの主要な部分から成り立っています。それぞれの部分について詳細に見ていきましょう。
エンコーダ:入力データを低次元の隠れ表現に変換する役割を果たします。この隠れ表現は、データの重要な特徴を捉えることができるように設計されています。
デコーダ:エンコーダによって生成された隠れ表現から、元の入力データを再構築する役割を果たします。この再構築プロセスは、データの重要な特徴を保持しながら、不要な情報を取り除くことが目的です。
オートエンコーダの訓練
オートエンコーダの訓練は、エンコーダとデコーダのパラメータを最適化するプロセスで、入力データの再構築を目指します。
オートエンコーダの訓練の際、損失関数は元の入力データと再構築されたデータとの差異を測定します。一般的な損失関数は平均二乗誤差(MSE)です。
オートエンコーダの訓練プロセスは以下の手順で行われます。
- 前向きパス: 入力データをエンコーダに通し、隠れ表現を得る。次に、隠れ表現をデコーダに通し、再構築されたデータを得る。
- 損失計算: 元の入力データと再構築されたデータとの間の損失を計算する。
- 後ろ向きパス: 損失に基づいて、勾配降下法やその派生(例:Adam、SGD)を使用してパラメータを更新する。
訓練データ全体を何度か繰り返し処理することで、エンコーダとデコーダのパラメータが最適化され、入力データを効果的に再構築できるようになります。
オートエンコーダの実装
MNISTデータセットを使用して、オートエンコーダモデルを訓練し、損失をプロットするものです。最初にデータのロードと変換が行われ、次にモデルの定義、訓練、検証が行われます。最後に損失がプロットされます。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import pandas as pd
# データのロードと変換
transform = transforms.Compose([
transforms.ToTensor(), # テンソルに変換
transforms.Lambda(lambda x: torch.flatten(x)) # データを平坦化
])
# MNISTデータセットの訓練データのロード
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
# MNISTデータセットのテストデータのロード
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)
# 訓練データとテストデータのローダーを作成
train_loader = DataLoader(train_dataset, batch_size=256, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=256, shuffle=False)
# オートエンコーダのクラス定義
class Autoencoder(nn.Module):
def __init__(self, encoding_dim=36):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential( # エンコーダ部分の定義
nn.Linear(784, encoding_dim),
nn.ReLU()
)
self.decoder = nn.Sequential( # デコーダ部分の定義
nn.Linear(encoding_dim, 784),
nn.Sigmoid()
)
def forward(self, x): # 順伝播の定義
x = self.encoder(x)
x = self.decoder(x)
return x
# 訓練部分
encoding_dim = 36
autoencoder = Autoencoder(encoding_dim)
criterion = nn.BCELoss() # 損失関数の定義
optimizer = optim.Adam(autoencoder.parameters()) # オプティマイザの定義
train_loss = []
test_loss = []
# 20エポックの訓練
for epoch in range(20):
# 訓練フェーズ
autoencoder.train()
epoch_train_loss = 0
for data, _ in train_loader:
optimizer.zero_grad() # 勾配の初期化
output = autoencoder(data) # モデルの出力を計算
loss = criterion(output, data) # 損失の計算
loss.backward() # 勾配の計算
optimizer.step() # パラメータの更新
epoch_train_loss += loss.item() * len(data)
train_loss.append(epoch_train_loss / len(train_loader.dataset))
# 検証フェーズ
autoencoder.eval()
epoch_test_loss = 0
with torch.no_grad():
for data, _ in test_loader:
output = autoencoder(data)
loss = criterion(output, data)
epoch_test_loss += loss.item() * len(data)
test_loss.append(epoch_test_loss / len(test_loader.dataset))
# 損失のプロット
df_log = pd.DataFrame({'train_loss': train_loss, 'val_loss': test_loss}) # 損失のデータフレーム
df_log.plot(style=['r--', 'r-'])
plt.ylabel("Loss") # y軸のラベル
plt.xlabel("epochs") # x軸のラベル
plt.show() # グラフの表示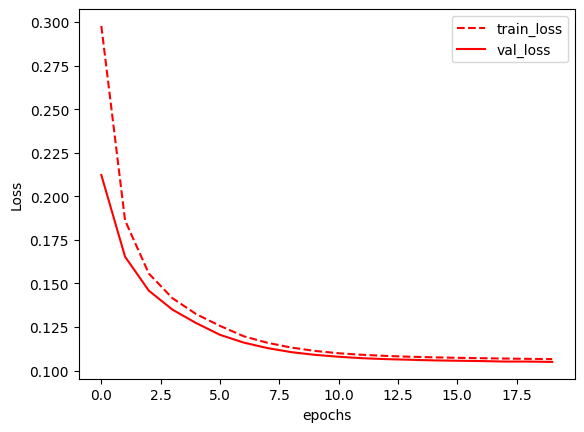
次に、テストデータを使用してエンコードとデコードを行い、元の画像、エンコードされた画像、デコードされた画像を表示しています。エンコードされた画像の形状は、エンコード次元に応じて変更する必要があります。
# エンコーダモデルの定義
class Encoder(nn.Module):
def __init__(self, encoding_dim=36):
super(Encoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, encoding_dim), # 入力層からエンコード層への線形変換
nn.ReLU() # ReLU活性化関数
)
def forward(self, x):
x = self.encoder(x)
return x
# デコーダモデルの定義
class Decoder(nn.Module):
def __init__(self, encoding_dim=36):
super(Decoder, self).__init__()
self.decoder = nn.Sequential(
nn.Linear(encoding_dim, 28 * 28), # エンコード層から出力層への線形変換
nn.Sigmoid() # Sigmoid活性化関数
)
def forward(self, x):
x = self.decoder(x)
return x
# 初期化
encoder_model = Encoder()
decoder_model = Decoder()
# オートエンコーダからの重みのコピー
encoder_model.encoder[0].weight = autoencoder.encoder[0].weight
encoder_model.encoder[0].bias = autoencoder.encoder[0].bias
decoder_model.decoder[0].weight = autoencoder.decoder[0].weight
decoder_model.decoder[0].bias = autoencoder.decoder[0].bias
# エンコードされた画像とデコードされた画像の予測
with torch.no_grad():
test_data, _ = next(iter(test_loader))
test_data = test_data.view(test_data.size(0), -1)
encoded_imgs = encoder_model(test_data) # エンコード
decoded_imgs = decoder_model(encoded_imgs) # デコード
# 画像の表示
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# 元の画像
ax = plt.subplot(3, n, i + 1)
plt.imshow(test_data[i].numpy().reshape(28, 28), cmap='gray')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# エンコードされた画像
ax = plt.subplot(3, n, i + 1 + n)
plt.imshow(encoded_imgs[i].numpy().reshape(6, 6), cmap='gray') # エンコード次元に合わせて形状を変更
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# デコードされた画像
ax = plt.subplot(3, n, i + 1 + 2 * n)
plt.imshow(decoded_imgs[i].numpy().reshape(28, 28), cmap='gray')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show() # グラフの表示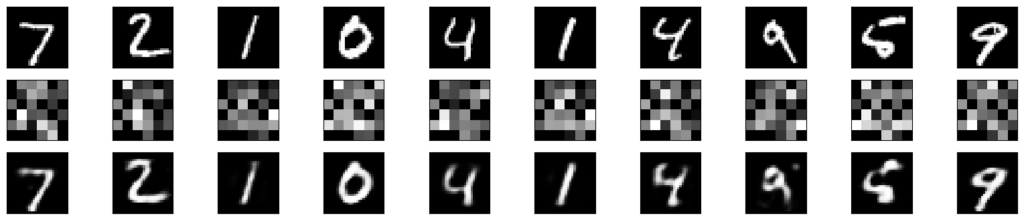
まとめ
最後までご覧いただきありがとうございました。
