このシリーズでは、自然言語処理において主流であるTransformerを中心に、環境構築から学習の方法までまとめます。
今回の記事ではHuggingface Transformersの入門として、livedoor ニュース記事のデータセットによる文章分類モデルの学習方法を紹介します。
Google colabを使用して、簡単に最新の自然言語処理モデルを実装することができますので、ぜひ最後までご覧ください。
【前回】
【🔰Huggingface Transformers入門⑥】文章分類モデルを作成する(1) 〜CSVからデータセットを作成する〜
このシリーズでは、自然言語処理において主流であるTransformerを中心に、環境構築から学習の方法までまとめます。 今回の記事ではHuggingface Transformersの入門として…

今回の内容
・Huggingface Transformersとは
・学習データの準備
・学習
・評価
Huggingface Transformersとは
Transformerの概要
「Transformer」は2017年にGoogleが「Attention is all you need」で発表した深層学習モデルです。
現在では、自然言語処理に利用する深層学習モデルの主流になっています。
これまでの自然言語処理分野で多く使われていた「RNN」(Recurrent Neural Network)や「CNN」(Convolutional Neural Network)を利用せず、Attentionのみを用いたEncoder-Decoder型のモデルとなっています。
「Transformer」が登場して以降、多くの自然言語処理モデルが再構築され、過去を上回る成果を上げています。
最近では自然言語処理だけでなく、ViTやDETRなどといった画像認識にも応用されています。
Huggingface Transformersの概要
「Hugging Face」とは米国のHugging Face社が提供している、自然言語処理に特化したディープラーニングのフレームワークです。
「Huggingface Transformers」は、先ほど紹介したTransformerを実装するためのフレームワークであり、「自然言語理解」と「自然言語生成」の最先端の汎用アーキテクチャ(BERT、GPT-2など)と、何千もの事前学習済みモデルを提供しています。
ソースコードは全てGitHub上で公開されており、誰でも無料で使うことができます。
学習データの準備
今回の記事では、文章分類問題のデータセットとして有名なlivedoor ニュース記事による分類モデルの作成を行います。
(livedoor ニュースコーパス(https://www.rondhuit.com/download.html)より引用)
それぞれのニュース記事のタイトルから分類の学習を行います。
学習データの準備
まずは学習に使用するデータを準備します。
詳細は前回の記事で紹介していますので、合わせてご覧ください。
【🔰Huggingface Transformers入門⑥】文章分類モデルを作成する(1) 〜CSVからデータセットを作成する〜
このシリーズでは、自然言語処理において主流であるTransformerを中心に、環境構築から学習の方法までまとめます。 今回の記事ではHuggingface Transformersの入門として…
ここからはGoogle colabを使用して実装していきます。
今回紹介するコードは以下のボタンからコピーして使用していただくことも可能です。
![]()
Googleドライブをマウントして、作業フォルダを作成します。
from google.colab import drive
drive.mount('/content/drive')
!mkdir -p '/content/drive/My Drive/huggingface_transformers_demo/'
%cd '/content/drive/My Drive/huggingface_transformers_demo/'必要なライブラリをインストールします。
!pip install transformers fugashi ipadic sentencepiece datasetslivedoor ニュースコーパスをインストールします。
!wget https://www.rondhuit.com/download/ldcc-20140209.tar.gz
!tar zxvf ldcc-20140209.tar.gzダウンロードしたデータから学習データを作成します。
import os
import pandas as pd
# タイトルリストの取得
def get_title_list(path):
title_list = []
filenames = os.listdir(path)
for filename in filenames:
# ファイルの読み込み
with open(path+filename) as f:
title = f.readlines()[2].strip()
title_list.append(title)
return title_list# データセットの生成(各ニュース記事のタイトルを取得)
df = pd.DataFrame(columns=['label', 'sentence'])
#0
title_list = get_title_list('text/dokujo-tsushin/')
for title in title_list:
df = df.append({'label':0 , 'sentence':title}, ignore_index=True)
#1
title_list = get_title_list('text/it-life-hack/')
for title in title_list:
df = df.append({'label':1 , 'sentence':title}, ignore_index=True)
#2
title_list = get_title_list('text/sports-watch/')
for title in title_list:
df = df.append({'label':2 , 'sentence':title}, ignore_index=True)
#3
title_list = get_title_list('text/kaden-channel/')
for title in title_list:
df = df.append({'label':3 , 'sentence':title}, ignore_index=True)
#4
title_list = get_title_list('text/livedoor-homme/')
for title in title_list:
df = df.append({'label':4 , 'sentence':title}, ignore_index=True)
#5
title_list = get_title_list('text/movie-enter/')
for title in title_list:
df = df.append({'label':5 , 'sentence':title}, ignore_index=True)
#6
title_list = get_title_list('text/peachy/')
for title in title_list:
df = df.append({'label':6 , 'sentence':title}, ignore_index=True)
#7
title_list = get_title_list('text/smax/')
for title in title_list:
df = df.append({'label':7 , 'sentence':title}, ignore_index=True)
#8
title_list = get_title_list('text/topic-news/')
for title in title_list:
df = df.append({'label':8 , 'sentence':title}, ignore_index=True)
# データをシャッフルする
df = df.sample(frac=1)
# 上記で取得したデータを学習用と検証用に分割してCSV出力
num = len(df)
df[:int(num*0.8)].to_csv('./text/news_train.csv', sep=',', index=False)
df[int(num*0.8):].to_csv('./text/news_val.csv', sep=',', index=False)以上で学習データの準備が完了しました。
Transformerのファインチューニング
学習データの読み込み
ここからは先ほど用意したデータセットを学習していきます。
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from transformers import TrainingArguments
from transformers import Trainer
from datasets import Dataset
from sklearn.metrics import accuracy_score, f1_score
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
import torch
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd先ほど作成したデータセットを読み込みます。
train_df = pd.read_csv("./text/news_train.csv",encoding='UTF-8')
validation_df = pd.read_csv("./text/news_val.csv",encoding='UTF-8')
train_dataset = Dataset.from_pandas(train_df)
validation_dataset = Dataset.from_pandas(validation_df)
from datasets import DatasetDict
dataset = DatasetDict({
"train": train_dataset,
"validation": validation_dataset,
})データの一部を表示してみます。
train_df| index | label | sentence |
|---|---|---|
| 0 | 2 | ダル実戦デビューに「あれが本物のダルビッシュだと思ったら大きな間違い」 |
| 1 | 7 | 日本エイサー、1920×1200ドットのWUXGAディスプレイ搭載Android 4.0タブレット「ICONIA TAB A700」を7月20日に発売 |
| 2 | 7 | NTTドコモ、Xperia GX SO-04Dの発売時期を2012年8月と再案内!8月上旬〜中旬に発売へ |
| 3 | 1 | 少し古いマシンに向くSSD登場! マイクロンよりSATA2.0に最適化されたSSD |
| 4 | 3 | コンパスを使うのは年に1度? iPhoneで一番不要な機能とは【話題】 |
| 5 | 5 | ジョニデが常識はずれのヴァンパイアに! 『ダーク・シャドウ』予告映像に注目 |
| 6 | 4 | “新たな一歩を願って”チヨダが靴などを宮城県災害対策本部に寄付 |
| 7 | 5 | 15歳の天才空手美少女が映画デビュー「気分はシンデレラ」 |
| 8 | 2 | 仲田歩夢と似ていると話題、ベンチで一際可愛いヤングなでしこ |
| 9 | 3 | ソニーは過去最大の赤字で1万人リストラ... 家電業界の凋落はとまらないのか【話題】 |
| 10 | 3 | 【話題】NTTドコモ「おくだけ充電」が「てもみん」や「PRONTO」に設置!無料で利用できる |
| 11 | 7 | ASUS、3万円台で買えるTegra3+Android 4.0搭載タブレット「ASUS Pad TF300T」を日本で6月以降発売!シリーズ名称も変更 |
| 12 | 7 | おっ!懐かしい!賞金はでないけどね・・・。「電流イライラ棒 3D」【Androidアプリ】 |
| 13 | 3 | 企業戦士の鎧を脱いだら光の戦士になろう! スター・ウォーズ ライトセーバールームライト【売れ筋チェック】 |
| 14 | 3 | 【話題】ジョブズのための端末だった? iPhone4Sの予約が本日スタート |
事前学習済みモデルのロード
トークナイザをAutoTokenizerで呼び出します。
# トークナイザの取得
tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking")モデルを取得します。
今回のデータセットは9種類のラベルがあることから、num_labels = 9とします。
これにより、分類ヘッドが持つ出力の数が決まります。
# モデルの取得
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_labels = 9
model = (AutoModelForSequenceClassification
.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking", num_labels=num_labels)
.to(device))データセット全体に処理を適用するには、バッチ単位で処理する関数を定義しmapを使って実施します。
・padding=True:バッチ内の最も長い系列長に合うようpaddingする処理を有効にします。
・truncation=True:後段のモデルが対応する最大コンテキストサイズ以上を切り捨てます。
# トークナイザ処理
def tokenize(batch):
return tokenizer(batch["sentence"], padding=True, truncation=True)
dataset_encoded = dataset.map(tokenize, batched=True, batch_size=None)性能指標の定義
学習時に性能指標を与える必要があるため、関数化して定義しておきます。
これにより、F1スコアとモデルの正解率を計算することができます。
# 評価指標の定義
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
f1 = f1_score(labels, preds, average="weighted")
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1}学習の設定
学習用のパラメータをTrainingArgumentsクラスを用いて設定します。
# 学習の準備
batch_size = 16
logging_steps = len(dataset_encoded["train"]) // batch_size
model_name = f"classification"
training_args = TrainingArguments(
output_dir=model_name,
num_train_epochs=2,
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
evaluation_strategy="epoch",
disable_tqdm=False,
logging_steps=logging_steps,
push_to_hub=False,
log_level="error",
)学習
学習はTrainerクラスで実行します。
# 学習
trainer = Trainer(
model=model, args=training_args,
compute_metrics=compute_metrics,
train_dataset=dataset_encoded["train"],
eval_dataset=dataset_encoded["validation"],
tokenizer=tokenizer
)trainer.train()学習が終わると結果が表示されます。
| Epoch | Training Loss | Validation Loss | Accuracy | F1 |
|---|---|---|---|---|
| 1 | 0.962600 | 0.467524 | 0.850271 | 0.849660 |
| 2 | 0.357600 | 0.391786 | 0.879404 | 0.879821 |
評価
評価はpredictにより得ることができます。
混同行列で結果を表示します。
preds_output = trainer.predict(dataset_encoded["validation"])
y_preds = np.argmax(preds_output.predictions, axis=1)
y_valid = np.array(dataset_encoded["validation"]["label"])
labels =['dokujo', 'it', 'sports-','kaden','homme','movie','peachy','smax','topic-news']
def plot_confusion_matrix(y_preds, y_true, labels):
cm = confusion_matrix(y_true, y_preds, normalize="true")
fig, ax = plt.subplots(figsize=(6, 6))
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot(cmap="Blues", values_format=".2f", ax=ax, colorbar=False)
plt.title("Normalized confusion matrix")
plt.show()
plot_confusion_matrix(y_preds, y_valid,labels)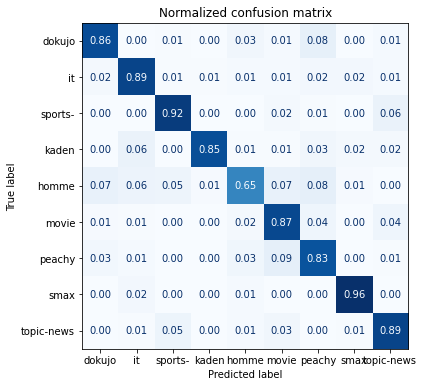
学習したモデルを保存することができます。
trainer.save_model('./text/model')まとめ
最後までご覧いただきありがとうございました。
今回の記事ではHuggingface Transformersの入門として、livedoor ニュース記事のデータセットによる文章分類モデルの学習方法を紹介しました。
次回は今回学習したモデルの推論を紹介します。
是非ご覧ください。