正則化
正則化は、機械学習モデルの過学習を防ぐために使用されます。過学習とは、モデルが訓練データに対して過度に最適化されてしまう現象で、その結果として新しい、未知のデータに対する汎化性能が低下することを指します。
正則化の基本的なアイディアは、モデルの複雑さにペナルティを課すことにより、過度に複雑なモデルを回避することです。これにより、モデルは訓練データに対して過度に適応することなく、未知のデータに対しても良い予測性能を保つことが可能となります。
正則化の手法
- L1 正則化:この方法では、一部のモデルパラメータをゼロにすることで正則化を行います。これにより、無関係または重要でない特徴量に関連するパラメータを除去し、モデルを単純化することができます。L1 正則化を適用した回帰モデルはラッソ回帰と呼ばれます。
- L2 正則化:こちらはパラメータの大きさに応じてそれらをゼロに近づけることで正則化を行います。この方法は、モデルの全ての特徴量が出力に何らかの寄与をするようにしますが、その影響度を小さく抑えます。L2 正則化を適用した回帰モデルはリッジ回帰と呼ばれます。
これらの正則化技術は、モデルが訓練データに過剰に適応することなく、より汎化性の高い予測を行えるようにするために重要です。さらに、L1とL2正則化を組み合わせたElastic Netという手法も存在し、これはラッソ回帰とリッジ回帰の両方の特性を持つことを意識しておくと良いでしょう。
L1正則化
L1正則化は、機械学習モデルの過学習を抑制する手法の一つです。過学習とは、モデルが訓練データに過剰に適応してしまうことで、新しいデータに対する予測精度が低下する現象を指します。L1正則化では、モデルの損失関数にパラメータの絶対値の和を加えることで、パラメータの大きさを制限します。これにより、モデルが複雑になりすぎるのを防ぎ、過学習を抑制することができます。
L1正則化の特徴として、重要でない説明変数の係数(重み)をゼロにすることが挙げられます。この性質により、不要な説明変数を除去する「次元圧縮」が行われます。その結果、モデルの解釈が容易になるとともに、必要な変数だけがモデルに利用されるようになります。ただし、一般的にL2正則化に比べ予測性能は劣る傾向があります。
L2正則化
L2正則化は、損失関数にパラメータの二乗和をペナルティとして加える手法です。
具体的には、L2正則化を適用した機械学習モデルは、損失関数とパラメータの二乗和の和を最小にするパラメータを学習します。この二乗和は、パラメータが大きくなりすぎることを防ぐためのペナルティ項として機能します。数式で表すと、損失関数を、正則化の強度を調整するパラメータをとした場合、L2正則化は以下の式で表されます:
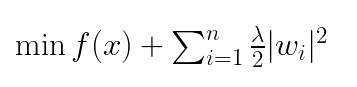
L2正則化の利点は、過学習を抑制し、モデルの予測精度を高めることにあります。特に、L2正則化を適用したモデルはパラメータが滑らかで表現力に優れているとされます。L1正則化と比較して、L2正則化は予測性能が高いと一般に言われています。
重要なのは、L2正則化の強度を調整するパラメータλの設定です。この値が大きいほど、ペナルティの影響が強まり、パラメータの値を小さく保つことが優先されます。ただし、この値を過度に大きくすると、モデルの表現力が損なわれ、結果的にバイアスが大きくなる可能性があります。したがって、λの値は目的に応じて適切に設定する必要があります。
L2正則化を回帰分析に適用したものはリッジ回帰と呼ばれ、L1正則化を適用したものはラッソ回帰と呼ばれます。また、L1正則化とL2正則化の両方を適用した手法はエラスティックネットとして知られています。
