FacebookAIが開発した、PyTorchベースの物体検出・セグメンテーションのためのプラットフォームであるDetectron2について操作方法をまとめます。
Detectron2の発展版であるDeticもこの手法をベースにしていますので、ぜひ基本操作をおさえておきましょう。
Google colabを使用して簡単に実装することができますので、ぜひ最後までご覧ください。
今回の目標
・Detectron2の概要
・物体検出・セグメンテーション・その他の視覚認識タスクの実装方法を学ぶ
・検出スコア・座標の出力、セグメンテーションの輪郭とマスク画像の出力
Dectron2の概要は
Detectron2は、物体検出・セグメンテーションアルゴリズムを提供するFacebook AIResearchの次世代ライブラリです。
Detectron とmaskrcnn-benchmarkの後継となります。
Detectron2を使うことで、下の例のように物体検出やセグメンテーションを簡単に実装することができます。





なお、公式の実装は以下のリンクよりご確認いただけます。
Dectron2の導入
早速、Dectron2使用するための準備をしていきましょう。
ここからはGoogle colabを使用して実装していきます。
まずはGPUを使用できるように設定をします。
「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をGPUに変更
今回紹介するコードは以下のボタンからコピーして使用していただくことも可能です。
![]()
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive今回はDeticの使用を前提としているため、Deticをクローンします。
!git clone https://github.com/facebookresearch/Detic.git --recurse-submodules
%cd Detic次に必要なライブラリをインストールします。
!pip install pyyaml==5.1
import torch
TORCH_VERSION = ".".join(torch.__version__.split(".")[:2])
CUDA_VERSION = torch.__version__.split("+")[-1]
print("torch: ", TORCH_VERSION, "; cuda: ", CUDA_VERSION)
!pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/$CUDA_VERSION/torch$TORCH_VERSION/index.htmlimport detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
import numpy as np
import os, json, cv2, random
import pandas as pd
from google.colab.patches import cv2_imshow
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog, DatasetCatalogこれでDectron2を使用する準備が完了しました。
サンプル画像でInstance Segmentation
ここからは公式のチュートリアルに沿って、サンプル画像でInstance Segmentationを実装してみましょう。
まずは画像をダウンロードして、表示させてみます。
!wget http://images.cocodataset.org/val2017/000000439715.jpg -q -O input.jpg
im = cv2.imread("./input.jpg")
cv2_imshow(im)
次にInstance Segmentationを実行します。
なお、cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5とすることで検出スコアの閾値を0.5としています。
# モデルを指定してテストを実行
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")
predictor = DefaultPredictor(cfg)
outputs = predictor(im)最後に結果を表示してみましょう。
# テスト結果の画像を表示
v = Visualizer(im[:, :, ::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(out.get_image()[:, :, ::-1])
簡単にセグメンテーションが実装できました。
精度良く判定ができています。
なお、出力結果を出力することもできます。
# テスト結果を表示
print(outputs["instances"].pred_classes)
print(outputs["instances"].pred_boxes)
検出された対象のリスト番号や座標を確認することができます。
tensor([17, 0, 0, 0, 0, 0, 0, 0, 25, 0, 25, 25, 0, 0, 24],
device='cuda:0')
Boxes(tensor([[126.6035, 244.8977, 459.8291, 480.0000],
[251.1083, 157.8127, 338.9731, 413.6379],
[114.8496, 268.6864, 148.2352, 398.8111],
[ 0.8217, 281.0327, 78.6072, 478.4210],
[ 49.3954, 274.1229, 80.1545, 342.9808],
[561.2248, 271.5816, 596.2755, 385.2552],
[385.9072, 270.3125, 413.7130, 304.0397],
[515.9295, 278.3744, 562.2792, 389.3802],
[335.2409, 251.9167, 414.7491, 275.9375],
[350.9300, 269.2060, 386.0984, 297.9081],
[331.6292, 230.9996, 393.2759, 257.2009],
[510.7349, 263.2656, 570.9865, 295.9194],
[409.0841, 271.8646, 460.5582, 356.8722],
[506.8767, 283.3257, 529.9403, 324.0392],
[594.5663, 283.4820, 609.0577, 311.4124]], device='cuda:0'))なお、詳細な扱い方は次章以降で紹介します。
オリジナル画像で物体検出・セグメンテーションを実装
ここからはオリジナル画像で実装を進めていきましょう。
まずは画像を用意してGoogleドライブの「Detic」フォルダにアップしましょう。
アップが終わったら、画像を表示してみます。
im = cv2.imread("office.png")
cv2_imshow(im)Object Detection
まずは物体検出からです。
学習済みモデルは変更することも可能ですので、変更したい場合は公式からご確認ください。
# Faster R-CNNで物体検出
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.3
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml")
predictor = DefaultPredictor(cfg)
outputs = predictor(im)
v = Visualizer(im[:,:,::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(v.get_image()[:, :, ::-1])
物体検出ができました。
Instance Segmentation
次にインスタンスセグメンテーションです。
# Instance Segmentation
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.3
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")
predictor = DefaultPredictor(cfg)
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(v.get_image()[:, :, ::-1])こちらも簡単に実装することができました。
Keypoint Detection
次にKeypoint Detectionを実装します。
この技術は人体の骨格検出や姿勢推定などに利用されます。
# Keypoint Detection
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.3
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml")
predictor = DefaultPredictor(cfg)
outputs = predictor(im)
v = Visualizer(im[:,:,::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(v.get_image()[:, :, ::-1])座っている人や立っている人の姿勢がわかりました。
Panoptic Segmentation
最後にPanoptic Segmentationです。
これは、ピクセル単位でクラスと物体番号を推定するタスクです。
つまり、壁や床など個数を数えることができない物体も検出対象とします。
# Panoptic Segmentation
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml"))
cfg.MODEL.PANOPTIC_FPN.COMBINE.INSTANCES_CONFIDENCE_THRESH = 0.7
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml")
predictor = DefaultPredictor(cfg)
panoptic_seg, segments_info = predictor(im)["panoptic_seg"]
v = Visualizer(im[:, :, ::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
v = v.draw_panoptic_seg_predictions(panoptic_seg.to("cpu"), segments_info)
cv2_imshow(v.get_image()[:, :, ::-1])オフィスの中の床や壁などの領域もしっかりと判定できていますね。
結果表示
ここまで紹介した処理の結果を表示してみます。
物体検出の検出スコア出力
# Faster R-CNNで物体検出
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.3
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml")
predictor = DefaultPredictor(cfg)
outputs = predictor(im)
v = Visualizer(im[:,:,::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(v.get_image()[:, :, ::-1])# 結果を表形式で出力する
classes_list= MetadataCatalog.get(cfg.DATASETS.TRAIN[0]).thing_classes
objects = []
for id in outputs["instances"]._fields["pred_classes"].cpu().numpy():
obj = classes_list[id]
objects.append(obj)
# 推定した物体名のリスト
object_est = [(k,i) for k,i in zip(objects,outputs["instances"]._fields["scores"].cpu().numpy())]
import pandas as pd
df = pd.DataFrame(object_est, columns = ['pred_classes','scores'])
df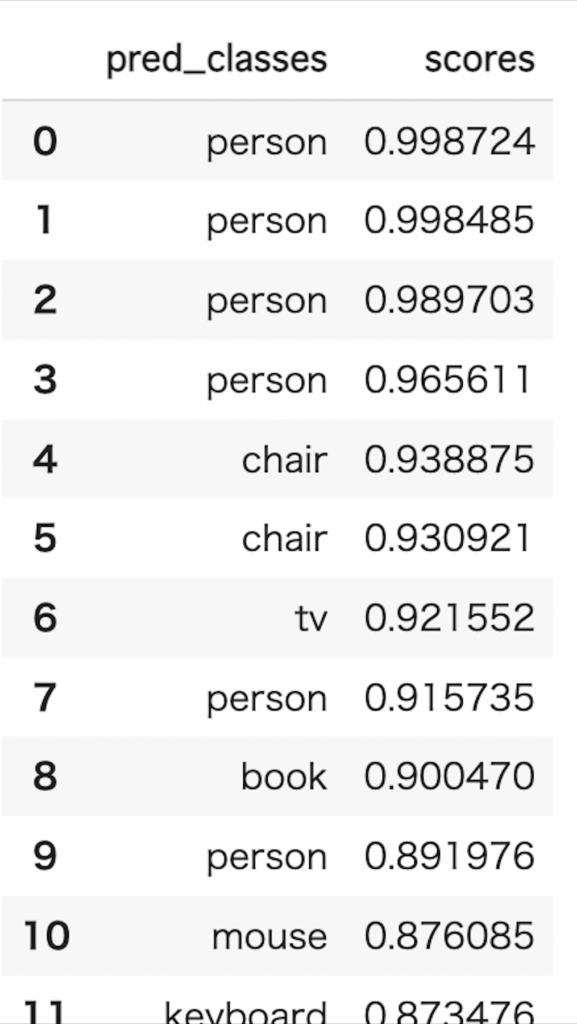
各検出対象のクラスとスコアを表示することができました。
検出座標なども同様に出力することが可能です。
物体検出の出力結果を画像に記述
画像の中に番号を記述してみます。
# 画像に結果を記述してみる
bounding_boxes = outputs["instances"]._fields["pred_boxes"].tensor.cpu().numpy()
img_copy = im
for i in range(len(bounding_boxes)):
left_pt = tuple(bounding_boxes[i][0:2])
right_pt = tuple(bounding_boxes[i][2:4])
cv2.putText(img_copy, f'{i}', left_pt, cv2.FONT_HERSHEY_PLAIN, 4, (255, 255, 255), 5, cv2.LINE_AA)
cv2.rectangle(img_copy,left_pt,right_pt,(0,0,155),1)
cv2_imshow(img_copy)
例えば人数を数えるなどのタスクに使えそうですね。
セグメンテーションの輪郭とマスク画像
最後にマスク画像の出力方法を紹介します。
# Instance Segmentation
im = cv2.imread("office.png")
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.3
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")
predictor = DefaultPredictor(cfg)
outputs = predictor(im)
対象を「人間」のみとします。
target = MetadataCatalog.get(cfg.DATASETS.TRAIN[0]).thing_classes.index("person")の部分を変更することで、検出対象の変更ができます。
target = MetadataCatalog.get(cfg.DATASETS.TRAIN[0]).thing_classes.index("person")
classes = np.asarray(outputs["instances"].to("cpu").pred_classes)
masks = np.asarray(outputs["instances"].to("cpu").pred_masks)[classes==target].astype("uint8")
contours = [ cv2.findContours(m, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0] for m in masks]
con =np.asarray(contours)[0]
for i in range(1,len(masks)):
con =con+np.asarray(contours)[i]
im_con = im.copy()
output =cv2.drawContours(im_con, con, -1, (0,255,0), 2)
cv2_imshow(output)
draw_campus = np.zeros_like(im_con, dtype=np.uint8)
cv2.fillPoly(draw_campus, con, color=(255,255,255))
from PIL import Image
Image.fromarray(draw_campus)
無事にマスク画像を出力することができました。
このマスク画像を使うことで、画像修復技術に活用することもできます。
【画像修復】Lamaによる写真から人物や自動車を消すInpainting(画像修復)の実装
この記事では2021年9月に登場した、Inpainting(画像修復)のモデルであるLaMaを紹介します。 まずは下の画像をご覧ください。 Inpainting(画像修復)よって、画像の中か…
まとめ
最後までご覧いただきありがとうございました。
今回はFacebookAIが開発した、PyTorchベースの物体検出・セグメンテーション・その他の視覚認識タスクのためのプラットフォームであるDetectron2について操作方法をまとめます。
今回紹介した技術の発展版にDeticがありますので、ぜひ合わせてご覧ください。
【物体検出】2万種類の物体検出ができるDeticを使って物体検出結果のCSV出力とマスク画像作成をする
Meta(旧 Facebook)が2022年1月に発表した新しい物体検出器であるDetic(Detecting Twenty-thousand Classes using Image-level Supervision) […]


