Meta(旧 Facebook)が2022年1月に発表した新しい物体検出器であるDetic(Detecting Twenty-thousand Classes using Image-level Supervision)を試していきます。
今回は物体検出結果のCSV出力とマスク画像作成の方法を紹介します。
Google colabを使用して簡単に物体検出のモデルを実装することができますので、ぜひ最後までご覧ください。
今回の目標
・Deticの基本操作(前回のおさらい)
・Deticによる物体検出のテスト結果出力とCSV出力
・セグメンテーションの結果からマスク画像を作成
Deticとは
Detic(Detecting Twenty-thousand Classes using Image-level Supervision)とはMeta(旧 Facebook)が発表した新しい物体検出器です。
画像分類データセットを使った物体検出器のトレーニングを可能とする事で、物体検出の検出分類数(vocabulary)を大幅に拡張しました。
これにより、物体検出時にアンカーボックスを用いる必要がなく、画像分類のデータセットで物体検出のトレーニングが可能となりました。
なお、公式の実装は以下のリンクよりご確認いただけます。
Deticの概要と基本操作は前回の記事で紹介しておりますので、ぜひ合わせてご覧ください。
【物体検出】2万種類の物体検出ができるDeticを試してみる 〜デモからテストまで〜
Meta(旧 Facebook)が2022年1月に発表した新しい物体検出器であるDetic(Detecting Twenty-thousand Classes using Image-level Supervision) […]

Deticの導入
早速Deticを使用していきましょう。
以下、Google colab環境で進めていきます。
まずはGPUを使用できるように設定をします。
「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をGPUに変更
今回紹介するコードは以下のボタンからコピーして使用していただくことも可能です。
![]()
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDriveimport torch
TORCH_VERSION = ".".join(torch.__version__.split(".")[:2])
CUDA_VERSION = torch.__version__.split("+")[-1]
print("torch: ", TORCH_VERSION, "; cuda: ", CUDA_VERSION)
!pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/$CUDA_VERSION/torch$TORCH_VERSION/index.html公式よりcloneしてきます。
!git clone https://github.com/facebookresearch/Detic.git --recurse-submodules
%cd Detic
!pip install -r requirements.txtimport detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
import sys
import numpy as np
import pandas as pd
import os, json, cv2, random
from google.colab.patches import cv2_imshow
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog, DatasetCatalog
sys.path.insert(0, 'third_party/CenterNet2/projects/CenterNet2/')
from centernet.config import add_centernet_config
from detic.config import add_detic_config
from detic.modeling.utils import reset_cls_test以上で導入が完了しました。
Deticで結果を出力
前回と同様にまずは学習済みモデルをダウンロードします。
# 学習済みモデルをダウンロード
cfg = get_cfg()
add_centernet_config(cfg)
add_detic_config(cfg)
cfg.merge_from_file("configs/Detic_LCOCOI21k_CLIP_SwinB_896b32_4x_ft4x_max-size.yaml")
cfg.MODEL.WEIGHTS = 'https://dl.fbaipublicfiles.com/detic/Detic_LCOCOI21k_CLIP_SwinB_896b32_4x_ft4x_max-size.pth'
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5
cfg.MODEL.ROI_BOX_HEAD.ZEROSHOT_WEIGHT_PATH = 'rand'
cfg.MODEL.ROI_HEADS.ONE_CLASS_PER_PROPOSAL = True
predictor = DefaultPredictor(cfg)まずはvocabularyをロードし、検出できる対象を全て検出してみましょう。
BUILDIN_CLASSIFIER = {
'lvis': 'datasets/metadata/lvis_v1_clip_a+cname.npy',
'objects365': 'datasets/metadata/o365_clip_a+cnamefix.npy',
'openimages': 'datasets/metadata/oid_clip_a+cname.npy',
'coco': 'datasets/metadata/coco_clip_a+cname.npy',
}
BUILDIN_METADATA_PATH = {
'lvis': 'lvis_v1_val',
'objects365': 'objects365_v2_val',
'openimages': 'oid_val_expanded',
'coco': 'coco_2017_val',
}
vocabulary = 'lvis' # change to 'lvis', 'objects365', 'openimages', or 'coco'
metadata = MetadataCatalog.get(BUILDIN_METADATA_PATH[vocabulary])
classifier = BUILDIN_CLASSIFIER[vocabulary]
num_classes = len(metadata.thing_classes)
reset_cls_test(predictor.model, classifier, num_classes)ここでは「drive.jpeg」の画像を使用します。
テストをして結果を表示してみましょう。
im = cv2.imread("drive.jpeg")
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1], metadata)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(out.get_image()[:, :, ::-1])
# print(outputs)
結果が表示されました。
画像の中にある多くの物体が検出できていますね。
物体検出結果(スコアや座標など)を表形式で出力する
スコアや座標を表示してみます。
それぞれの値はoutputs["instances"]から取り出すことが可能です。
各クラスに対して、順番にスコアや座標を取り出して表形式にしてみましょう。
result = []
[result.extend((x,
outputs["instances"][x].pred_classes.item(),
[metadata.thing_classes[x] for x in outputs["instances"][x].pred_classes][0],
outputs["instances"][x].scores.item(),
outputs["instances"][x].pred_boxes.tensor.cpu().numpy()[0][0],
outputs["instances"][x].pred_boxes.tensor.cpu().numpy()[0][1],
outputs["instances"][x].pred_boxes.tensor.cpu().numpy()[0][2],
outputs["instances"][x].pred_boxes.tensor.cpu().numpy()[0][3])
for x in range(len(outputs["instances"])))]
df = pd.DataFrame(result, columns = ['class-id','class','score','x-min','y-min','x-max','y-max'])
df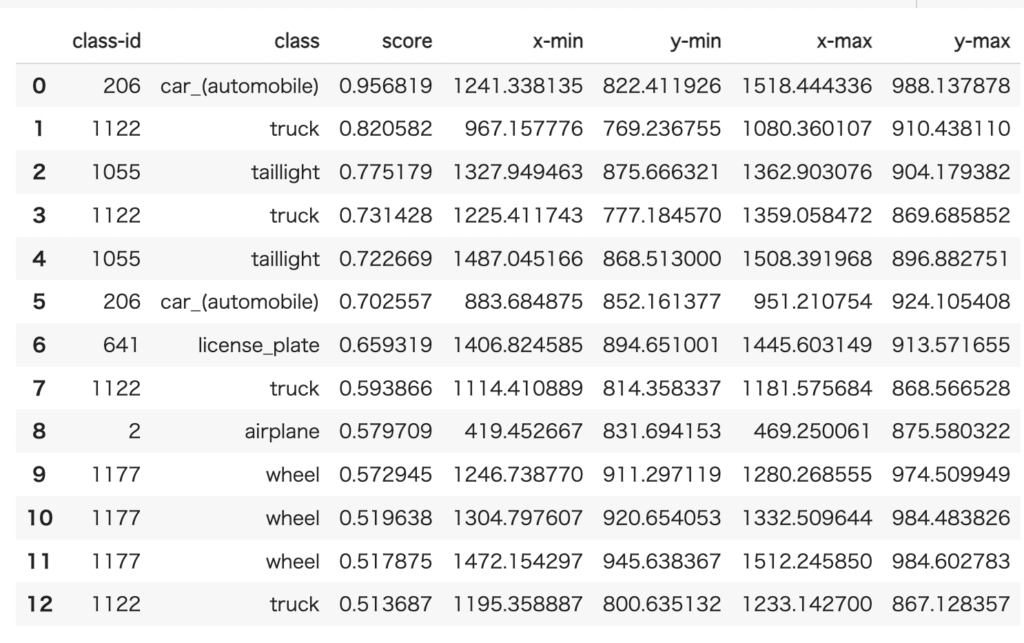
それぞれのクラスに対して、スコアや座標を表形式で出力することができました。
物体検出結果(スコアや座標など)をCS Vファイルで出力する
最後に結果をCSVファイルに出力しましょう。
df.to_csv("detic_result.csv")Detic によるテスト結果を出力して、CSVファイルに保存することができました。
物体検出結果を画像に表示する
先程の結果を画像の中にも表示させてみましょう。
ここではクラスIDをそれぞれのbouding-boxの左上に表示してみます。
bounding_boxes = outputs["instances"]._fields["pred_boxes"].tensor.cpu().numpy()
img_copy = im
for i in range(len(bounding_boxes)):
left_pt = tuple(bounding_boxes[i][0:2])
right_pt = tuple(bounding_boxes[i][2:4])
cv2.putText(img_copy, f'{i}', left_pt, cv2.FONT_HERSHEY_PLAIN, 4, (255, 255, 255), 5, cv2.LINE_AA)
cv2.rectangle(img_copy,left_pt,right_pt,(0,0,155),1)
cv2_imshow(img_copy)
例えば、検出対象を自動車にすれば、車の台数を視覚的に表現することができます。
以上、Deticを使って検出結果を出力する方法を紹介しました。
マスク画像を出力する
ここからはセグメンテーションの結果を利用して、マスク画像の作成をします。
なお各種セグメンテーションはDetecron2がベースになります。
前回の記事で紹介しておりますので、合わせてご覧ください。
【物体検出とセグメンテーション】Detectron2を使って物体検出とセグメンテーションを実装する
FacebookAIが開発した、PyTorchベースの物体検出・セグメンテーションのためのプラットフォームであるDetectron2について操作方法をまとめます。 Detectron2の発展版であ…

なお、今回はしきい値を0.8としています。
im = cv2.imread("drive.jpeg")
cfg = get_cfg()
add_centernet_config(cfg)
add_detic_config(cfg)
cfg.merge_from_file("configs/Detic_LCOCOI21k_CLIP_SwinB_896b32_4x_ft4x_max-size.yaml")
cfg.MODEL.WEIGHTS = 'https://dl.fbaipublicfiles.com/detic/Detic_LCOCOI21k_CLIP_SwinB_896b32_4x_ft4x_max-size.pth'
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.8
cfg.MODEL.ROI_BOX_HEAD.ZEROSHOT_WEIGHT_PATH = 'rand'
cfg.MODEL.ROI_HEADS.ONE_CLASS_PER_PROPOSAL = True
predictor = DefaultPredictor(cfg)
vocabulary = 'lvis' # change to 'lvis', 'objects365', 'openimages', or 'coco'
metadata = MetadataCatalog.get(BUILDIN_METADATA_PATH[vocabulary])
classifier = BUILDIN_CLASSIFIER[vocabulary]
num_classes = len(metadata.thing_classes)
reset_cls_test(predictor.model, classifier, num_classes)
im = cv2.imread("drive.jpeg")
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1], metadata)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2_imshow(out.get_image()[:, :, ::-1])
セグメンテーションの結果から輪郭を抽出する
次にクラスを自動車に限定して、輪郭を抽出してみましょう。
target = MetadataCatalog.get(cfg.DATASETS.TRAIN[0]).thing_classes.index("car_(automobile)")
classes = np.asarray(outputs["instances"].to("cpu").pred_classes)
masks = np.asarray(outputs["instances"].to("cpu").pred_masks)[classes==target].astype("uint8")
contours = [ cv2.findContours(m, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0] for m in masks]
con =np.asarray(contours)[0]
for i in range(1,len(masks)):
con =con+np.asarray(contours)[i]
im_con = im.copy()
output =cv2.drawContours(im_con, con, -1, (0,255,0), 2)
cv2_imshow(output)
先程の物体検出の結果のうち、自動車のみの輪郭を抽出することができました。
マスク画像を作成する
最後にこれを利用して、マスク画像を作成します。
draw_campus = np.zeros_like(im_con, dtype=np.uint8)
cv2.fillPoly(draw_campus, con, color=(255,255,255))
from PIL import Image
Image.fromarray(draw_campus)
無事にマスク画像を出力することができました。
(おまけ)Inpaintingで自動車を消してみる
このマスク画像を使うことで、画像修復技術に活用することもできます。
ぜひ、合わせてご覧ください。
【画像修復】Lamaによる写真から人物や自動車を消すInpainting(画像修復)の実装
この記事では2021年9月に登場した、Inpainting(画像修復)のモデルであるLaMaを紹介します。 まずは下の画像をご覧ください。 Inpainting(画像修復)よって、画像の中か…
まとめ
最後までご覧いただきありがとうございました。
今回はMeta(旧 Facebook)が2022年1月に発表した新しい物体検出器であるDetic(Detecting Twenty-thousand Classes using Image-level Supervision)の使い方を紹介しました。
今回は物体検出結果のCSV出力とマスク画像作成の方法についてご理解いただけかと思います。
なお、今回のベースとなっているDetectron2の扱い方は別の記事で紹介しておりますので、ぜひご覧ください。

