入力したテキストに応じた画像生成ができる「rq-vae-transformer」を紹介します。
実際に画像を生成してみましょう。
Google colabを使用して簡単に実装することができますので、ぜひ最後までご覧ください。
今回の目標
・rq-vae-transformerとは
・rq-vae-transformerの実装
rq-vae-transformerとは
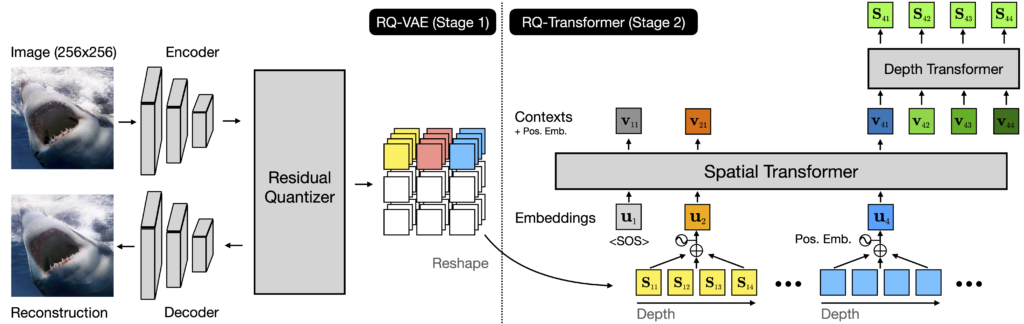
rq-vae-transformerは解像度画像を効果的に生成するために、残差量子化VAE(RQ-VAE)とRQ-Transformerで構成される2段階のフレームワークです。
画像の特徴マップを正確に近似し、画像を離散コードのスタックとして表現して、高品質の画像を効果的に生成できます。
実際に例を見てみましょう。

上段の入力テキストに対して、それぞれ対応した画像を生成できていることがわかります。
rq-vae-transformerの構成
コードブックのサイズが固定されている場合、RQ-VAEは画像の特徴マップを正確に近似し、画像を離散コードのスタックマップとして表すことができます。
RQ-Transformerは、コードの次のスタックを予測することにより、次の位置で量子化された特徴ベクトルを予測することを学習します。
無条件および条件付き画像生成のさまざまなベンチマークで、既存のARモデルよりも優れた性能を誇ります。
出典は以下の通りです。
rq-vae-transformerの導入
rq-vae-transformerを使用していきましょう。
以下、Google colab環境で進めていきます。
まずはGPUを使用できるように設定をします。
「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をGPUに変更
今回紹介するコードは以下のボタンからコピーして使用していただくことも可能です。
![]()
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive公式よりcloneしてきます。
!git clone https://github.com/kakaobrain/rq-vae-transformer次に必要なライブラリをインストールします。
%cd rq-vae-transformer
!pip install -r requirements.txt!pip install git+https://github.com/openai/CLIP.git以上で導入が完了しました。
デモ
まずはチュートリアルに沿って、画像を生成してみます。
学習済モデルをダウンロード
冒頭紹介した通り2つのステージ(VAEとtransformer)から成りますので、それぞれダウンロードします。
まずは以下のリンクからダウンロードしましょう。
ダウンロードが終わったら、以下のようにフォルダを作成してファイルを格納します。
rq-vae-transformer
└── cc3m_cc12m_yfcc
├── stage1
│ └──model.pt # model: RQ-VAE
└── stage2
└──model.pt # RQ-Transformer各種ライブラリのインポート
必要なライブラリをインポートします。
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from PIL import Image
import yaml
import torch
import torchvision
import clip
import torch.nn.functional as F
from notebooks.notebook_utils import TextEncoder, load_model, get_generated_images_by_texts先程保存したモデルを読み込みます。
# load stage 1 model: RQ-VAE
vqvae_path = './saved_models/cc3m_cc12m_yfcc/stage1/model.pt'
model_vqvae, _ = load_model(vqvae_path)
# load stage 2 model: RQ-Transformer
model_path = './saved_models/cc3m_cc12m_yfcc/stage2/model.pt'
model_ar, config = load_model(model_path, ema=False)
model_ar = model_ar.cuda().eval()
model_vqvae = model_vqvae.cuda().eval()
model_clip, preprocess_clip = clip.load("ViT-B/32", device='cpu')
model_clip = model_clip.cuda().eval()
text_encoder = TextEncoder(tokenizer_name=config.dataset.txt_tok_name,
context_length=config.dataset.context_length)チュートリアル実行
いよいよチュートリアルを実行していきます。
ここではサンプルとして、「A cherry blossom tree on the blue ocean」のキーワードで画像を生成してみます。
text_prompts = 'A cherry blossom tree on the blue ocean'
num_samples = 16
temperature= 1.0
top_k=1024
top_p=0.95pixels = get_generated_images_by_texts(model_ar,
model_vqvae,
text_encoder,
model_clip,
preprocess_clip,
text_prompts,
num_samples,
temperature,
top_k,
top_p,
)画像の生成が終わりました。
実際に生成された画像を並べてみてみましょう。
num_visualize_samples = 16
images = [pixel.cpu().numpy() * 0.5 + 0.5 for pixel in pixels]
images = torch.from_numpy(np.array(images[:num_visualize_samples]))
images = torch.clamp(images, 0, 1)
grid = torchvision.utils.make_grid(images, nrow=4)
img = Image.fromarray(np.uint8(grid.numpy().transpose([1,2,0])*255))
display(img)
海の上の桜の画像が生成されていますね。
VAEですので、当然毎回出力結果が異なります。
お好みの画像が生成されるまで繰り返してみるのも楽しいかもしれませんね。
うまくいったら、画像を保存しましょう。
img.save(f'{text_prompts}_temp_{temperature}_top_k_{top_k}_top_p_{top_p}.jpg')画像を1枚ずつ保存する
条件を変えて、色々な画像を生成してみましょう。
1行目の「text_prompts = " "」の部分を変えてみます。
さらに画像も1枚ずつ保存するように変更しました。
num_samples =300とすることで、300枚の画像が生成されます。
text_prompts = "Beautiful sunset"
num_samples = 300
temperature= 1.0
top_k=1024
top_p=0.95
pixels = get_generated_images_by_texts(model_ar,
model_vqvae,
text_encoder,
model_clip,
preprocess_clip,
text_prompts,
num_samples,
temperature,
top_k,
top_p,
)
for num in range(num_samples):
images = [pixel.cpu().numpy() * 0.5 + 0.5 for pixel in pixels]
images = torch.from_numpy(np.array(images[num]))
images = torch.clamp(images, 0, 1)
grid = torchvision.utils.make_grid(images, nrow=4)
img = Image.fromarray(np.uint8(grid.numpy().transpose([1,2,0])*255))
img.save(f'{text_prompts}_temp_{temperature}_top_k_{top_k}_top_p_{top_p}'+str(num)+'.jpg')画像が1枚ずつ保存されています。
個人的に気に入ったものを何枚か掲載してみます。









まとめ
最後までご覧いただきありがとうございました。
今回は入力したテキストに応じた画像生成ができる「rq-vae-transformer」を紹介しました。
ぜひ色々なテキストを入力して、好みの画像を生成してみてください。

