今回はViT(Vision Transformer)をテーマに、画像分類の基本的な実装方法を紹介します。
2022年7月に公開された、「japanese-cloob-vit-b-16(v0.2.0)」モデルを使用して、高性能な画像分類の実装を試してみましょう。
Google colabを使用して簡単に実装することができますので、ぜひ最後までご覧ください。
今回の目標
・画像認識とは
・ViTとCNN
・ViTによる分類の実装
画像分類とは
概要
画像分類はCV(コンピュータビジョン)のタスクのうちの1つです。
具体的には、画像に写る物体名称を出力するタスクであり、確信度が最も高い名称を結果として出力し、クラス分類を行います。
例として、以下のような画像が与えたとします。

画像分類タスクでは、この画像を「犬」として結果を出力することができます。
同様に以下の画像では「猫」として結果を出力します。

類似のタスク
画像認識技術の中で、類似のタスクに「物体検出」や「セグメンテーション」があります。
例えば、画像分類の場合、以下の画像では正しい結果を得ることができません。

画像内には「犬」と「猫」の両方が写っているため、分類では対応することができません。
このような場合には、物体のクラスと位置を出力する物体検出や、ピクセル単位で物体を識別するセグメンテーションにより、正しい結果を得ることができるようになります。
なお、それぞれの実装方法は以下の記事で紹介していますので、あわせてご覧下さい。
CNNとViT
ここからは画像認識の代表的な手法である、CNNとViTについて紹介します。
CNNとは
CNN(Convolutional Neural Network)は、日本語では「畳み込みニューラルネットワーク」と呼ばれ、画像認識技術においては代表的な手法です。
全結合層だけでなく、畳み込み層(Convolution Layer)とプーリング層(Pooling Layer)から構成されています。
2012年に登場したAlexNetを皮切りに、これまで多くのCNNのモデルが登場しています。
例として、こちらの記事ではEfficientNetv2による実装を紹介しています。
【はじめての画像分類】Google ColabでEfficientNetV2を使って画像分類
EfficientNetV2によりGoogle Colaboratory上で画像分類を実装していく手順をまとめます。今回の方法ではGoogleアカウントがあれば誰でも同じように試すことが可能です。 …

ViTとは
ViT(Vision Transformer)は、2020年にGoogleが発表した画像認識モデルです。
自然言語処理の分野においては、BERTやGPT3などのモデルがTransformerを応用したモデルとして急速に広まっていますが、その手法を画像認識タスクに応用したものがViTです。
CNNのように畳み込みを用いずにSOTA(State-of-the-Art)を達成したことで注目されました。
ViTはBERTと同様の構造をしており、BERTでは各単語のベクトル表現をEncoderに入力していましたが、ViTでは画像を小さなパッチに分割してベクトル化したものを入力します。
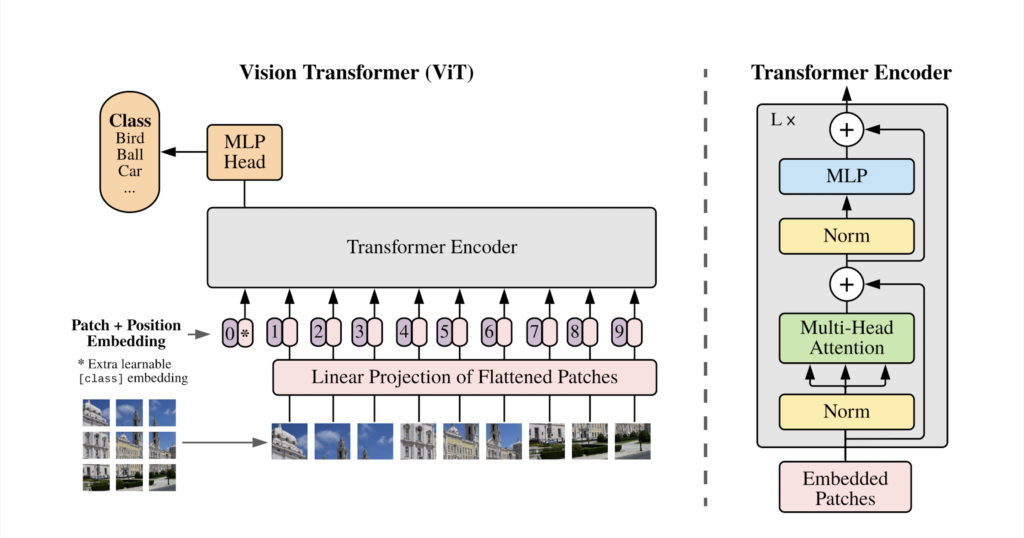
自然言語処理と同様に、大規模データセットで学習させた事前学習モデルを小規模データセットを用いた下流タスクでfine tuningするような使い方をします。
ViTによる画像分類の実装
ここからは、実際にViTによる画像分類を実装してみましょう。
今回紹介するコードは以下のリンクからもご覧いただけます。
![]()
準備
ここからは、Google colab環境で進めていきます。
はじめに、GPUを使用できるように設定をします。
「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をGPUに変更
設定が終わったら、まずはgoogleドライブをマウントします。
from google.colab import drive
drive.mount('/content/drive')
%cd '/content/drive/My Drive/'次に公式からクローンします。
!git clone https://github.com/rinnakk/japanese-clip
%cd japanese-clip必要なライブラリをインストールします。
!pip install git+https://github.com/rinnakk/japanese-clip.git以上で準備が完了しました。
実装
まずはここにあるサンプル画像を使用して、分類を行います。
必要なライブラリをインポートします。
import io
import requests
from PIL import Image
import torch
import japanese_clip as ja_clip
import matplotlib.pyplot as plt次に今回使用する画像と出力となるラベルを定義します。
画像はパスかURL、ラベルは任意のものを使用します。
今回は犬の画像を使用するので、他の候補として、猫と象を挙げます。
# 入力画像と出力ラベルを設定
image_file = 'data/dog.jpeg'
label_text = ["犬", "猫", "象"]GPUを使用できるようにします。
# GPUを使用する
device = "cuda" if torch.cuda.is_available() else "cpu"次にモデルを読み込みます。
今回は2022年7月にリリースされた、japanese-cloob-vit-b-16のv2を使用します。
# モデル読み込み
model, preprocess = ja_clip.load("rinna/japanese-cloob-vit-b-16", device=device)
tokenizer = ja_clip.load_tokenizer()次に先ほど指定した画像を読み込みます。
# 画像を読み込む
img = Image.open(image_file)
image = preprocess(img).unsqueeze(0).to(device)
encodings = ja_clip.tokenize(
texts=label_text,
max_seq_len=77,
device=device,
tokenizer=tokenizer,
)最後に推論します。
# 推論
with torch.no_grad():
image_features = model.get_image_features(image)
text_features = model.get_text_features(**encodings)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)推論結果を表示します。
# 結果表示
labels = zip(label_text, text_probs.flatten().tolist())
for label_text in labels:
print(f"{label_text[0]}\t: {label_text[1]:.2%}")
# 画像を表示
plt.imshow(img)
plt.axis('off')
plt.show()
犬 : 100.00%
猫 : 0.00%
象 : 0.00%画像とともに、ラベルに対する推論結果が表示されています。
今回は、犬の画像を100%犬であると判定することができました。
実装コード
別の画像の例に、ここまでの内容をまとめます。
import io
import requests
from PIL import Image
import torch
import japanese_clip as ja_clip
import matplotlib.pyplot as plt
# 入力画像と出力ラベルを設定
image_file = io.BytesIO(requests.get('https://i0.wp.com/tt-tsukumochi.com/wp-content/uploads/2022/04/test1-2-scaled.jpg?resize=2048%2C1536&ssl=1').content)
label_text = ["自動車", "電車", "新幹線","飛行機","バス","自転車"]
# GPUを使用する
device = "cuda" if torch.cuda.is_available() else "cpu"
# モデル読み込み
model, preprocess = ja_clip.load("rinna/japanese-cloob-vit-b-16", device=device)
tokenizer = ja_clip.load_tokenizer()
# 画像を読み込む
img = Image.open(image_file)
image = preprocess(img).unsqueeze(0).to(device)
encodings = ja_clip.tokenize(
texts=label_text,
max_seq_len=77,
device=device,
tokenizer=tokenizer,
)
# 推論
with torch.no_grad():
image_features = model.get_image_features(image)
text_features = model.get_text_features(**encodings)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
# 結果表示
labels = zip(label_text, text_probs.flatten().tolist())
for label_text in labels:
print(f"{label_text[0]}\t: {label_text[1]:.2%}")
# 画像を表示
plt.imshow(img)
plt.axis('off')
plt.show()実行すると、以下のような結果が表示されます。
自動車 : 0.00%
電車 : 100.00%
新幹線 : 0.00%
飛行機 : 0.00%
バス : 0.00%
自転車 : 0.00%
先ほどの例よりもラベルの候補を多くしてみましたが、正しく判定できていることがわかりました。
まとめ
最後までご覧いただき、ありがとうございました。
今回はViT(Vision Transformer)をテーマに、画像分類の基本的な実装方法を紹介しました。
このブログでは他にも多くの画像認識の実装方法を紹介しておりますので、ぜひご覧ください。


{kind=link}