このシリーズではE資格対策として、書籍「ゼロから作るDeep Learning」を参考に学習に役立つ情報をまとめています。
<参考書籍>
Dropoutの概要
Dropoutとは、ニューラルネットワークを訓練する際に用いられる正則化の一つで、過学習(overfitting)を防ぐための手法です。過学習は、モデルが訓練データに対しては高い精度を示すものの、新たなテストデータに対しては低い精度を示す現象を指します。これはモデルが訓練データのノイズや偶然のパターンまで学習してしまっているために起こります。
Dropoutは、訓練の各ステップでニューロンをランダムに選び、それらを「ドロップアウト」(つまり、無効化)することで、ニューロンが特定の他のニューロンに依存しすぎることを防ぎます。これにより、ネットワークはより頑健(robust)になり、過学習を防ぐ効果があります。
Dropoutの実装
このクラスは、forwardメソッドで指定されたdropout_ratioに基づいてランダムにニューロンを無効化(ドロップアウト)しています。そしてbackwardメソッドでは、ドロップアウトされたニューロンは誤差逆伝播の際にも考慮されません。
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
ネットワークを訓練する際は、訓練データを用いてネットワークの出力と正解との間の誤差を計算し、その誤差を用いてネットワークのパラメータを更新します。
実装(MNIST)
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
class Trainer:
def __init__(self, network, x_train, t_train, x_test, t_test,
epochs=20, mini_batch_size=100,
optimizer='SGD', optimizer_param={'lr':0.01},
evaluate_sample_num_per_epoch=None, verbose=True):
self.network = network
self.verbose = verbose
self.x_train = x_train
self.t_train = t_train
self.x_test = x_test
self.t_test = t_test
self.epochs = epochs
self.batch_size = mini_batch_size
self.evaluate_sample_num_per_epoch = evaluate_sample_num_per_epoch
# optimizer
optimizer_class_dict = {'sgd':SGD, 'momentum':Momentum, 'nesterov':Nesterov,
'adagrad':AdaGrad, 'rmsprop':RMSprop, 'adam':Adam}
self.optimizer = optimizer_class_dict[optimizer.lower()](**optimizer_param)
self.train_size = x_train.shape[0]
self.iter_per_epoch = max(self.train_size / mini_batch_size, 1)
self.max_iter = int(epochs * self.iter_per_epoch)
self.current_iter = 0
self.current_epoch = 0
self.train_loss_list = []
self.train_acc_list = []
self.test_acc_list = []
def train_step(self):
batch_mask = np.random.choice(self.train_size, self.batch_size)
x_batch = self.x_train[batch_mask]
t_batch = self.t_train[batch_mask]
grads = self.network.gradient(x_batch, t_batch)
self.optimizer.update(self.network.params, grads)
loss = self.network.loss(x_batch, t_batch)
self.train_loss_list.append(loss)
if self.verbose: print("train loss:" + str(loss))
if self.current_iter % self.iter_per_epoch == 0:
self.current_epoch += 1
x_train_sample, t_train_sample = self.x_train, self.t_train
x_test_sample, t_test_sample = self.x_test, self.t_test
if not self.evaluate_sample_num_per_epoch is None:
t = self.evaluate_sample_num_per_epoch
x_train_sample, t_train_sample = self.x_train[:t], self.t_train[:t]
x_test_sample, t_test_sample = self.x_test[:t], self.t_test[:t]
train_acc = self.network.accuracy(x_train_sample, t_train_sample)
test_acc = self.network.accuracy(x_test_sample, t_test_sample)
self.train_acc_list.append(train_acc)
self.test_acc_list.append(test_acc)
if self.verbose: print("=== epoch:" + str(self.current_epoch) + ", train acc:" + str(train_acc) + ", test acc:" + str(test_acc) + " ===")
self.current_iter += 1
def train(self):
for i in range(self.max_iter):
self.train_step()
test_acc = self.network.accuracy(self.x_test, self.t_test)
if self.verbose:
print("=============== Final Test Accuracy ===============")
print("test acc:" + str(test_acc))
class MultiLayerNetExtend:
def __init__(self, input_size, hidden_size_list, output_size,
activation='relu', weight_init_std='relu', weight_decay_lambda=0,
use_dropout = False, dropout_ration = 0.5, use_batchnorm=False):
self.input_size = input_size
self.output_size = output_size
self.hidden_size_list = hidden_size_list
self.hidden_layer_num = len(hidden_size_list)
self.use_dropout = use_dropout
self.weight_decay_lambda = weight_decay_lambda
self.use_batchnorm = use_batchnorm
self.params = {}
self.__init_weight(weight_init_std)
activation_layer = {'sigmoid': Sigmoid, 'relu': Relu}
self.layers = OrderedDict()
for idx in range(1, self.hidden_layer_num+1):
self.layers['Affine' + str(idx)] = Affine(self.params['W' + str(idx)],
self.params['b' + str(idx)])
if self.use_batchnorm:
self.params['gamma' + str(idx)] = np.ones(hidden_size_list[idx-1])
self.params['beta' + str(idx)] = np.zeros(hidden_size_list[idx-1])
self.layers['BatchNorm' + str(idx)] = BatchNormalization(self.params['gamma' + str(idx)], self.params['beta' + str(idx)])
self.layers['Activation_function' + str(idx)] = activation_layer[activation]()
if self.use_dropout:
self.layers['Dropout' + str(idx)] = Dropout(dropout_ration)
idx = self.hidden_layer_num + 1
self.layers['Affine' + str(idx)] = Affine(self.params['W' + str(idx)], self.params['b' + str(idx)])
self.last_layer = SoftmaxWithLoss()
def __init_weight(self, weight_init_std):
all_size_list = [self.input_size] + self.hidden_size_list + [self.output_size]
for idx in range(1, len(all_size_list)):
scale = weight_init_std
if str(weight_init_std).lower() in ('relu', 'he'):
scale = np.sqrt(2.0 / all_size_list[idx - 1])
elif str(weight_init_std).lower() in ('sigmoid', 'xavier'):
scale = np.sqrt(1.0 / all_size_list[idx - 1])
self.params['W' + str(idx)] = scale * np.random.randn(all_size_list[idx-1], all_size_list[idx])
self.params['b' + str(idx)] = np.zeros(all_size_list[idx])
def predict(self, x, train_flg=False):
for key, layer in self.layers.items():
if "Dropout" in key or "BatchNorm" in key:
x = layer.forward(x, train_flg)
else:
x = layer.forward(x)
return x
def loss(self, x, t, train_flg=False):
y = self.predict(x, train_flg)
weight_decay = 0
for idx in range(1, self.hidden_layer_num + 2):
W = self.params['W' + str(idx)]
weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W**2)
return self.last_layer.forward(y, t) + weight_decay
def accuracy(self, x, t):
y = self.predict(x, train_flg=False)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t, train_flg=True)
grads = {}
for idx in range(1, self.hidden_layer_num+2):
grads['W' + str(idx)] = numerical_gradient(loss_W, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_W, self.params['b' + str(idx)])
if self.use_batchnorm and idx != self.hidden_layer_num+1:
grads['gamma' + str(idx)] = numerical_gradient(loss_W, self.params['gamma' + str(idx)])
grads['beta' + str(idx)] = numerical_gradient(loss_W, self.params['beta' + str(idx)])
return grads
def gradient(self, x, t):
self.loss(x, t, train_flg=True)
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
grads = {}
for idx in range(1, self.hidden_layer_num+2):
grads['W' + str(idx)] = self.layers['Affine' + str(idx)].dW + self.weight_decay_lambda * self.params['W' + str(idx)]
grads['b' + str(idx)] = self.layers['Affine' + str(idx)].db
if self.use_batchnorm and idx != self.hidden_layer_num+1:
grads['gamma' + str(idx)] = self.layers['BatchNorm' + str(idx)].dgamma
grads['beta' + str(idx)] = self.layers['BatchNorm' + str(idx)].dbeta
return grads
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = sigmoid(x)
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
class Affine:
def __init__(self, W, b):
self.W =W
self.b = b
self.x = None
self.original_x_shape = None
self.dW = None
self.db = None
def forward(self, x):
self.original_x_shape = x.shape
x = x.reshape(x.shape[0], -1)
self.x = x
out = np.dot(self.x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
dx = dx.reshape(*self.original_x_shape)
return dx
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None
self.t = None
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
if self.t.size == self.y.size:
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
class Momentum:
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum*self.v[key] - self.lr*grads[key]
params[key] += self.v[key]
class Nesterov:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class RMSprop:
def __init__(self, lr=0.01, decay_rate = 0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class Adam:
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
def softmax(x):
x = x - np.max(x, axis=-1, keepdims=True)
return np.exp(x) / np.sum(np.exp(x), axis=-1, keepdims=True)
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
from keras.datasets import mnist
(x_train, t_train), (x_test, t_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = x_train[:300]
t_train = t_train[:300]
use_dropout = True
dropout_ratio = 0.2
network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],
output_size=10, use_dropout=use_dropout, dropout_ration=dropout_ratio)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=301, mini_batch_size=100,
optimizer='sgd', optimizer_param={'lr': 0.01}, verbose=True)
trainer.train()
train_acc_list, test_acc_list = trainer.train_acc_list, trainer.test_acc_list
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, marker='o', label='train', markevery=10)
plt.plot(x, test_acc_list, marker='s', label='test', markevery=10)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()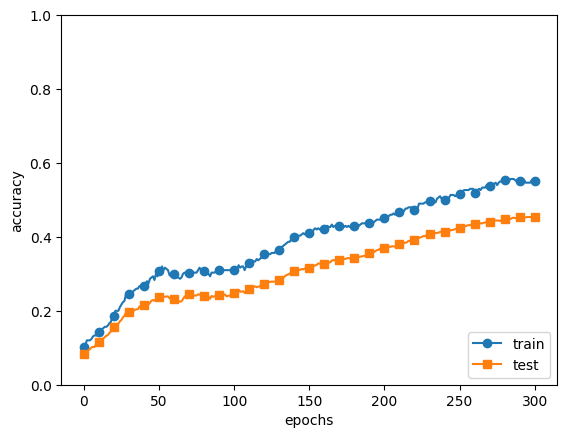
まとめ
最後までご覧いただきありがとうございました。
