このシリーズではE資格対策として、書籍「ゼロから作るDeep Learning」を参考に学習に役立つ情報をまとめています。
<参考書籍>
ハイパーパラメータとは
ハイパーパラメータとは、学習率やバッチサイズ、隠れ層のノード数など、モデルの学習前に人間が設定するパラメータのことを指します。これらのパラメータはモデルの学習結果と性能に大きな影響を与えるため、適切な値を見つけることが重要です。
ハイパーパラメータの最適化手法としては、以下のようなものがあります:
- グリッドサーチ(Grid Search):ハイパーパラメータの全ての組み合わせを試す方法です。例えば、学習率を0.1, 0.01, 0.001とし、バッチサイズを10, 100, 1000とした場合、全ての組み合わせを試します。しかし、パラメータの数が増えると試す組み合わせが指数的に増えるため、計算コストが高くなります。
- ランダムサーチ(Random Search):ハイパーパラメータの範囲を指定し、その範囲内でランダムに値を選び出す方法です。グリッドサーチに比べて計算コストを抑えられ、また、多くの場合でグリッドサーチと同等またはそれ以上の性能を出すことが報告されています。
- ベイズ最適化(Bayesian Optimization):ハイパーパラメータの評価結果をもとに、次に試すべきハイパーパラメータを決定する方法です。評価結果をガウス過程という手法でモデル化し、そのモデルの予測結果をもとに次に試すハイパーパラメータを選びます。
これらの手法を使ってハイパーパラメータを最適化することで、ディープラーニングモデルの性能を向上させることができます。ただし、ハイパーパラメータの最適化は時間と計算リソースを必要とするため、適切な手法を選ぶことが重要です。
ハイパーパラメータの探索
深層学習のハイパーパラメータの最適化をランダム探索で行うものです。ここで最適化を行うハイパーパラメータは「learning rate, lr 」と 「weight decay」です。
optimization_trial = 100
results_val = {}
results_train = {}
for _ in range(optimization_trial):
# 探索したハイパーパラメータの範囲を指定===============
weight_decay = 10 ** np.random.uniform(-8, -4)
lr = 10 ** np.random.uniform(-6, -2)
# ================================================
val_acc_list, train_acc_list = __train(lr, weight_decay)
print("val acc:" + str(val_acc_list[-1]) + " | lr:" + str(lr) + ", weight decay:" + str(weight_decay))
key = "lr:" + str(lr) + ", weight decay:" + str(weight_decay)
results_val[key] = val_acc_list
results_train[key] = train_acc_list具体的な処理は次のようになっています:
optimization_trialで指定した回数だけ以下の処理を行います。この例では100回試行します。- 探索するハイパーパラメータの範囲をランダムに指定します。学習率(lr)と重み減衰(weight decay)の範囲は、それぞれ
10 ** np.random.uniform(-6, -2)と10 ** np.random.uniform(-8, -4)で指定されています。これにより、それぞれのハイパーパラメータは指定した範囲内でランダムに選択されます。 - 指定したハイパーパラメータで訓練を行い、バリデーションデータと訓練データの精度を取得します。訓練は
__train(lr, weight_decay)で行われ、返された結果はval_acc_listとtrain_acc_listに格納されます。 - 試行の結果を表示します。ここではバリデーションの精度、使用した学習率、重み減衰の値を表示します。
- 各試行の結果を辞書型の
results_valとresults_trainに保存します。これにより、後で各試行の精度の遷移を確認したり、どのハイパーパラメータが最も良い結果をもたらしたか確認できます。
このようなランダムサーチは、ハイパーパラメータの適切な範囲が事前にわかっていない場合や、大まかな範囲を探索したい場合に有効です。ただし、探索空間が大きい場合や、試行回数が多い場合には時間がかかる欠点があります。
実装(MNIST)
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
class Trainer:
def __init__(self, network, x_train, t_train, x_test, t_test,
epochs=20, mini_batch_size=100,
optimizer='SGD', optimizer_param={'lr':0.01},
evaluate_sample_num_per_epoch=None, verbose=True):
self.network = network
self.verbose = verbose
self.x_train = x_train
self.t_train = t_train
self.x_test = x_test
self.t_test = t_test
self.epochs = epochs
self.batch_size = mini_batch_size
self.evaluate_sample_num_per_epoch = evaluate_sample_num_per_epoch
# optimizer
optimizer_class_dict = {'sgd':SGD, 'momentum':Momentum, 'nesterov':Nesterov,
'adagrad':AdaGrad, 'rmsprop':RMSprop, 'adam':Adam}
self.optimizer = optimizer_class_dict[optimizer.lower()](**optimizer_param)
self.train_size = x_train.shape[0]
self.iter_per_epoch = max(self.train_size / mini_batch_size, 1)
self.max_iter = int(epochs * self.iter_per_epoch)
self.current_iter = 0
self.current_epoch = 0
self.train_loss_list = []
self.train_acc_list = []
self.test_acc_list = []
def train_step(self):
batch_mask = np.random.choice(self.train_size, self.batch_size)
x_batch = self.x_train[batch_mask]
t_batch = self.t_train[batch_mask]
grads = self.network.gradient(x_batch, t_batch)
self.optimizer.update(self.network.params, grads)
loss = self.network.loss(x_batch, t_batch)
self.train_loss_list.append(loss)
if self.verbose: print("train loss:" + str(loss))
if self.current_iter % self.iter_per_epoch == 0:
self.current_epoch += 1
x_train_sample, t_train_sample = self.x_train, self.t_train
x_test_sample, t_test_sample = self.x_test, self.t_test
if not self.evaluate_sample_num_per_epoch is None:
t = self.evaluate_sample_num_per_epoch
x_train_sample, t_train_sample = self.x_train[:t], self.t_train[:t]
x_test_sample, t_test_sample = self.x_test[:t], self.t_test[:t]
train_acc = self.network.accuracy(x_train_sample, t_train_sample)
test_acc = self.network.accuracy(x_test_sample, t_test_sample)
self.train_acc_list.append(train_acc)
self.test_acc_list.append(test_acc)
if self.verbose: print("=== epoch:" + str(self.current_epoch) + ", train acc:" + str(train_acc) + ", test acc:" + str(test_acc) + " ===")
self.current_iter += 1
def train(self):
for i in range(self.max_iter):
self.train_step()
test_acc = self.network.accuracy(self.x_test, self.t_test)
if self.verbose:
print("=============== Final Test Accuracy ===============")
print("test acc:" + str(test_acc))
class MultiLayerNet:
def __init__(self, input_size, hidden_size_list, output_size,
activation='relu', weight_init_std='relu', weight_decay_lambda=0):
self.input_size = input_size
self.output_size = output_size
self.hidden_size_list = hidden_size_list
self.hidden_layer_num = len(hidden_size_list)
self.weight_decay_lambda = weight_decay_lambda
self.params = {}
# 重みの初期化
self.__init_weight(weight_init_std)
# レイヤの生成
activation_layer = {'sigmoid': Sigmoid, 'relu': Relu}
self.layers = OrderedDict()
for idx in range(1, self.hidden_layer_num+1):
self.layers['Affine' + str(idx)] = Affine(self.params['W' + str(idx)],
self.params['b' + str(idx)])
self.layers['Activation_function' + str(idx)] = activation_layer[activation]()
idx = self.hidden_layer_num + 1
self.layers['Affine' + str(idx)] = Affine(self.params['W' + str(idx)],
self.params['b' + str(idx)])
self.last_layer = SoftmaxWithLoss()
def __init_weight(self, weight_init_std):
all_size_list = [self.input_size] + self.hidden_size_list + [self.output_size]
for idx in range(1, len(all_size_list)):
scale = weight_init_std
if str(weight_init_std).lower() in ('relu', 'he'):
scale = np.sqrt(2.0 / all_size_list[idx - 1]) # ReLUを使う場合に推奨される初期値
elif str(weight_init_std).lower() in ('sigmoid', 'xavier'):
scale = np.sqrt(1.0 / all_size_list[idx - 1]) # sigmoidを使う場合に推奨される初期値
self.params['W' + str(idx)] = scale * np.random.randn(all_size_list[idx-1], all_size_list[idx])
self.params['b' + str(idx)] = np.zeros(all_size_list[idx])
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
y = self.predict(x)
weight_decay = 0
for idx in range(1, self.hidden_layer_num + 2):
W = self.params['W' + str(idx)]
weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W ** 2)
return self.last_layer.forward(y, t) + weight_decay
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
for idx in range(1, self.hidden_layer_num+2):
grads['W' + str(idx)] = numerical_gradient(loss_W, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_W, self.params['b' + str(idx)])
return grads
def gradient(self, x, t):
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 設定
grads = {}
for idx in range(1, self.hidden_layer_num+2):
grads['W' + str(idx)] = self.layers['Affine' + str(idx)].dW + self.weight_decay_lambda * self.layers['Affine' + str(idx)].W
grads['b' + str(idx)] = self.layers['Affine' + str(idx)].db
return grads
def shuffle_dataset(x, t):
permutation = np.random.permutation(x.shape[0])
if x.ndim == 2:
x = x[permutation,:]
elif x.ndim == 3:
x = x[permutation,:,:]
elif x.ndim == 4:
x = x[permutation,:,:,:]
t = t[permutation]
return x, t
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = sigmoid(x)
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
class Affine:
def __init__(self, W, b):
self.W =W
self.b = b
self.x = None
self.original_x_shape = None
self.dW = None
self.db = None
def forward(self, x):
self.original_x_shape = x.shape
x = x.reshape(x.shape[0], -1)
self.x = x
out = np.dot(self.x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
dx = dx.reshape(*self.original_x_shape)
return dx
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None
self.t = None
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
if self.t.size == self.y.size:
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
class Nesterov:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class RMSprop:
def __init__(self, lr=0.01, decay_rate = 0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class Adam:
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
class Momentum:
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum*self.v[key] - self.lr*grads[key]
params[key] += self.v[key]
def softmax(x):
x = x - np.max(x, axis=-1, keepdims=True)
return np.exp(x) / np.sum(np.exp(x), axis=-1, keepdims=True)
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
from keras.datasets import mnist
(x_train, t_train), (x_test, t_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = x_train[:500]
t_train = t_train[:500]
validation_rate = 0.20
validation_num = int(x_train.shape[0] * validation_rate)
x_train, t_train = shuffle_dataset(x_train, t_train)
x_val = x_train[:validation_num]
t_val = t_train[:validation_num]
x_train = x_train[validation_num:]
t_train = t_train[validation_num:]
def __train(lr, weight_decay, epocs=50):
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],
output_size=10, weight_decay_lambda=weight_decay)
trainer = Trainer(network, x_train, t_train, x_val, t_val,
epochs=epocs, mini_batch_size=100,
optimizer='sgd', optimizer_param={'lr': lr}, verbose=False)
trainer.train()
return trainer.test_acc_list, trainer.train_acc_list
optimization_trial = 100
results_val = {}
results_train = {}
for _ in range(optimization_trial):
weight_decay = 10 ** np.random.uniform(-8, -4)
lr = 10 ** np.random.uniform(-6, -2)
val_acc_list, train_acc_list = __train(lr, weight_decay)
print("val acc:" + str(val_acc_list[-1]) + " | lr:" + str(lr) + ", weight decay:" + str(weight_decay))
key = "lr:" + str(lr) + ", weight decay:" + str(weight_decay)
results_val[key] = val_acc_list
results_train[key] = train_acc_list
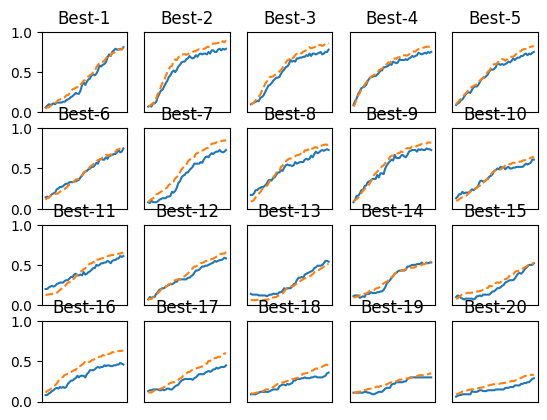
print("=========== Hyper-Parameter Optimization Result ===========")
graph_draw_num = 20
col_num = 5
row_num = int(np.ceil(graph_draw_num / col_num))
i = 0
for key, val_acc_list in sorted(results_val.items(), key=lambda x:x[1][-1], reverse=True):
print("Best-" + str(i+1) + "(val acc:" + str(val_acc_list[-1]) + ") | " + key)
plt.subplot(row_num, col_num, i+1)
plt.title("Best-" + str(i+1))
plt.ylim(0.0, 1.0)
if i % 5: plt.yticks([])
plt.xticks([])
x = np.arange(len(val_acc_list))
plt.plot(x, val_acc_list)
plt.plot(x, results_train[key], "--")
i += 1
if i >= graph_draw_num:
break
plt.show()実行結果:
まとめ
最後までご覧いただきありがとうございました。
