今回の記事では日本語LLMの1つであるLLM-jp-13Bの実装を紹介します。
Google Colabを使用して簡単に実装できますので、ぜひ最後までご覧ください。
LLM-jp-13Bの概要
LLM-jp-13Bとは
LLM-jp-13Bは、10/20に発表されたNIIが主導するLLM-jpの一環として開発された大規模な言語モデルです。500名以上の自然言語処理及び計算機システムの研究者が集まり、ハイブリッド会議やオンライン会議、Slack等を通じて情報共有と共同研究開発を行っています。LLM-jpの目的は、オープンかつ日本語に強いLLMの構築とそれに関連する研究開発の推進、定期的な情報交換、組織横断的な連携の促進、そして成果物の公開です。
LLM-jp-13Bは、計算資源としてデータ活用社会創成プラットフォームmdxの12ノード(A100 96枚)を利用し、モデル構築にはMicrosoftのDeepSpeed技術が採用されています。学習とログの保存にはWeights & Biasesを用いており、モデルのパラメータ数は130億個にも及びます。
学習データ量は約3000億トークンで、日本語と英語のウェブコーパス、Wikipedia、プログラムコード等を含んでいます。これらのデータは、トークナイザーやウェブコーパスのフィルタリングツールを用いて整備されました。モデルのチューニングには、日本語と英語のインストラクションデータおよび和訳データを用い、複数の評価データに対して横断的な評価を行うフレームワークが構築されています。
しかし、LLM-jp-13Bはまだ研究開発の初期段階にあり、人間の意図に沿った出力を行うようにチューニングされていないため、そのまま実用的なサービスに供することを想定していません。安全性や倫理的な側面からの検討が更に必要です。
詳細は以下のリンクからご確認ください。
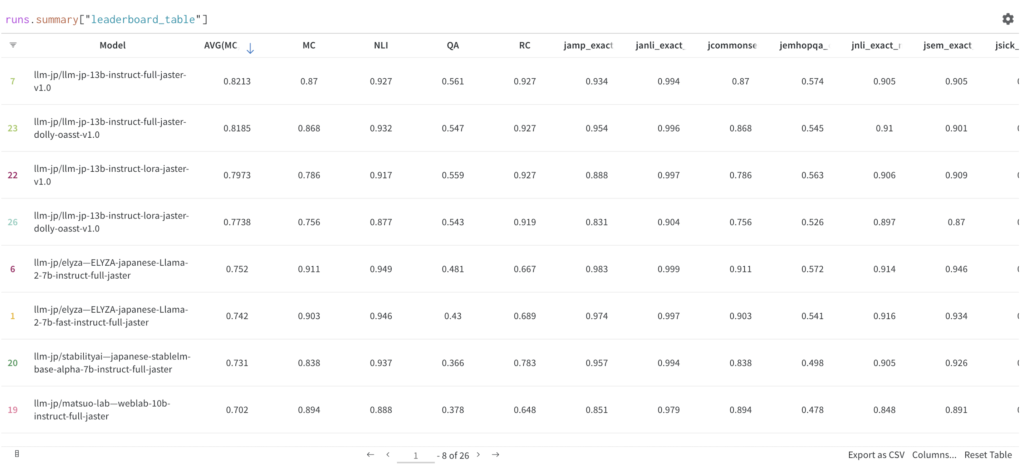
LLM-jp-13Bの性能
llm-jp-13b-instruct-full-jaster-v1.0の実装
まずはインストラクションチューニングされたモデルから試していきます。
ここからはGoogle colabを使用して実装していきます。
(Google colabの使用方法はこちら⇨使い方)
※今回紹介するコードは以下のリンクからもご覧いただけます。
![]()
まずはGPUを使用できるように設定をします。
・「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をGPUに変更
(参考)GPU RAM:12.9 GB
必要なライブラリをインストールします。
!pip install transformers accelerate質問①:自然言語処理とは何か
まずはテンプレートの通りに動かしてみます。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained(
"llm-jp/llm-jp-13b-instruct-full-jaster-v1.0"
)
model = AutoModelForCausalLM.from_pretrained(
"llm-jp/llm-jp-13b-instruct-full-jaster-v1.0",
device_map="auto",
torch_dtype=torch.float16
)
text = "自然言語処理とは何か"
text = text + "### 回答:"
tokenized_input = tokenizer.encode(text,
add_special_tokens=False,
return_tensors="pt"
).to(model.device)
with torch.no_grad():
output = model.generate(
tokenized_input,
max_new_tokens=100,
do_sample=True,
top_p=0.95,
temperature=0.7,
)[0]
print(tokenizer.decode(output))実行結果:
自然言語処理とは何か### 回答: 自然言語処理とは、コンピュータに人間が話す言葉を理解させること質問②:日本で一番高い山はどこか?
text = "日本で一番高い山はどこか?"
text = text + "### 回答:"
tokenized_input = tokenizer.encode(text,
add_special_tokens=False,
return_tensors="pt"
).to(model.device)
with torch.no_grad():
output = model.generate(
tokenized_input,
max_new_tokens=100,
do_sample=True,
top_p=0.95,
temperature=0.7,
)[0]
print(tokenizer.decode(output))実行結果:
日本で一番高い山はどこか?### 回答:富士山質問③:富士山について詳しく解説して下さい
text = "富士山について詳しく解説して下さい"
text = text + "### 回答:"
tokenized_input = tokenizer.encode(text,
add_special_tokens=False,
return_tensors="pt"
).to(model.device)
with torch.no_grad():
output = model.generate(
tokenized_input,
max_new_tokens=100,
do_sample=True,
top_p=0.95,
temperature=0.7,
)[0]
print(tokenizer.decode(output))実行結果:
富士山について詳しく解説して下さい### 回答: 山梨県と静岡県の県境にそびえる標高3776mの山llm-jp-13b-v1.0の実装
インストラクションチューニングされていないモデルも試してみます。
富士山について詳しく述べる
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained(
"llm-jp/llm-jp-13b-v1.0"
)
model = AutoModelForCausalLM.from_pretrained(
"llm-jp/llm-jp-13b-v1.0",
device_map="auto",
torch_dtype=torch.float16
)
text = "富士山について詳しく述べる"
tokenized_input = tokenizer.encode(text,
add_special_tokens=False,
return_tensors="pt"
).to(model.device)
with torch.no_grad():
output = model.generate(
tokenized_input,
max_new_tokens=1500,
do_sample=True,
top_p=0.95,
temperature=0.7,
)[0]
print(tokenizer.decode(output))実行結果:
富士山について詳しく述べるが、その前に、富士山とは何かを説明しておこう。
富士山は静岡県、山梨県、神奈川県の3県にまたがり、標高3776mの独立峰である。
富士五湖の1つである河口湖から望む姿は、日本の象徴として知られる。
日本国内の名山の中でも、最も美しい山との呼び声も高い。
日本だけでなく世界的にも有名な山で、富士山は世界遺産に登録されている。
富士山頂には、日本一高い標高を誇る神社の奥宮がある。 その名も「富士山本宮浅間大社」。
この神社は、浅間大神を主祭神としており、浅間大神は富士山の神様である。
富士山の山頂に浅間大社があるということは、富士山は浅間大社の神域であると言える。
富士山は、浅間大社の神域であると同時に、信仰の対象でもあるのだ。
浅間大社は、富士山の頂上にある神社で、富士山の神である浅間大神を祀っている。
浅間大社は、富士山が噴火したときに、その噴煙で社殿が焼けてしまった。
そこで、浅間大社の神職たちが、山頂にあった浅間大神の祠を、今の場所に移し祀った。
富士山の神は、富士山の噴火を鎮めることを目的としている。
そのため、浅間大社は、噴火を鎮めるために建てられた神社なのだ。
富士山は、噴火を鎮めるために浅間大社が建てられた神社である。
このような神社は他にはなく、富士山が特別な場所であることがわかる。
富士山は、浅間大社の神域であり、信仰の対象である。
浅間大社が富士山の噴火を鎮めるために建てられたことから、富士山は噴火を鎮める特別な場所であるといえるだろう。
富士山の御祭神は、火の神である火之神櫛真智命(ひのかみくしまちのみこと)様で、元々は富士山の頂上にあった浅間大神を祀っています。
浅間大神は、富士山の神様で、古くからの山岳信仰の対象であり、富士山が噴火する度に、浅間大社も大打撃を受けていた為、浅間大神を山麓にある富士山本宮浅間大社にお祀りし、その御神霊を富士山の噴火が鎮まるまで、お預かりしているということです。
富士山の麓にある浅間大社の参道には、多くのお土産物屋さんや飲食店が立ち並び、富士登山の時には、ここでお土産や飲食を楽しみながら、ゆっくりと登山をするのも良いでしょう。
(以下ループのため省略)とても詳しく解説してもらうことができました。
まとめ
最後までご覧いただきありがとうございました。
今回の記事では日本語LLMの1つであるLLM-jp-13Bの実装を紹介しました。