このシリーズでは物体検出でお馴染みのYOLOシリーズの2022年最新版「YOLOv7」について、環境構築から学習の方法までまとめます。
YOLOv7は2022年7月に公開された最新バージョンであり、速度と精度の面で限界を押し広げています。
第4回目では、アノテーション作業に焦点を当て、様々な方法を紹介します。
物体検出のモデル作成にあたっては教師データの収集に加えて、検出対象物の座標を与えるアノテーション作業が必要となります。
モデルの作成の際にはアノテーションを精度良くかつ効率的に行うようにしましょう。
今回の目標
・アノテーションとは
・YOLOv7で必要となるアノテーション(座標)
・アノテーションツールの使い方
・OpenCVによるアノテーション
・Windows「ペイント」
アノテーションとは
アノテーションとは、あるデータに対して関連する情報(メタデータ)を注釈として付与することを言います。
機械学習においては、モデルに学習させるための教師データ(正解データ、ラベル)を作成することを指します。
物体検出でのアノテーションとは、画像の中における物体の位置(座標)を明示することを言います。
具体的には、以下の画像を例に取ると、マスク着用を検出するための座標をテキストファイルとして保存する作業と言い換えることもできます。

※各座標の考え方は「第2回 モデルの評価と推論 〜座標とスコアの出力〜」の記事で紹介しています。
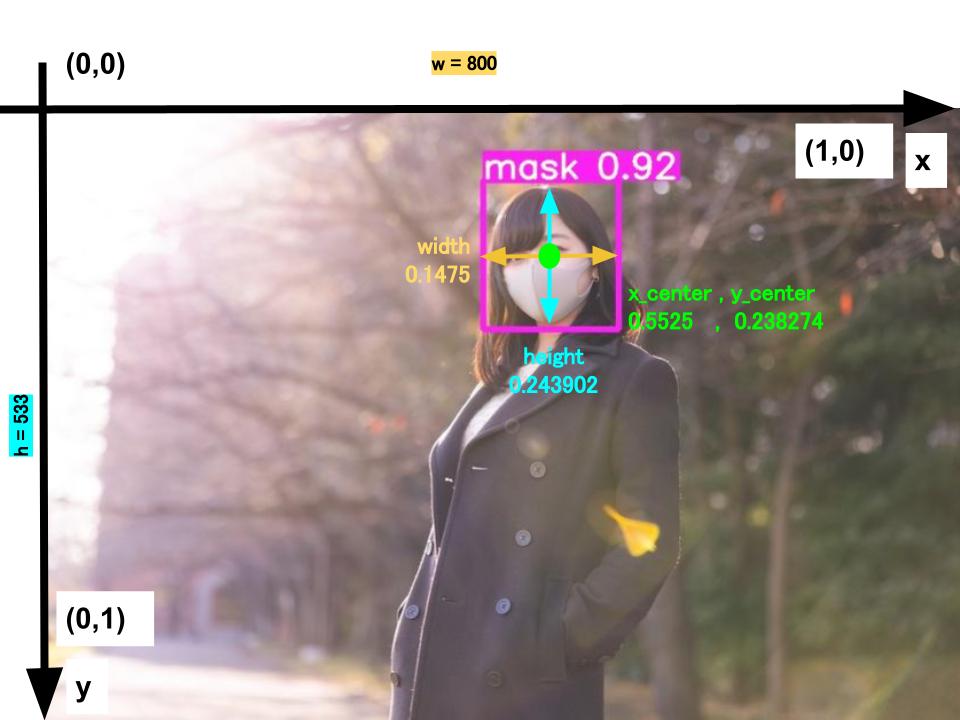
0 0.5525 0.238274 0.1475 0.243902
# oject-class, x_center,y_center,width,height
# ymin = y1/h,ymax = y2/h,xmin = x1/w,xmax = x2/w
# x_center = xmin + (xmax-xmin)/2
# y_center = ymin + (ymax-ymin)/2
# width = xmax-xmin
# height = ymax-ymin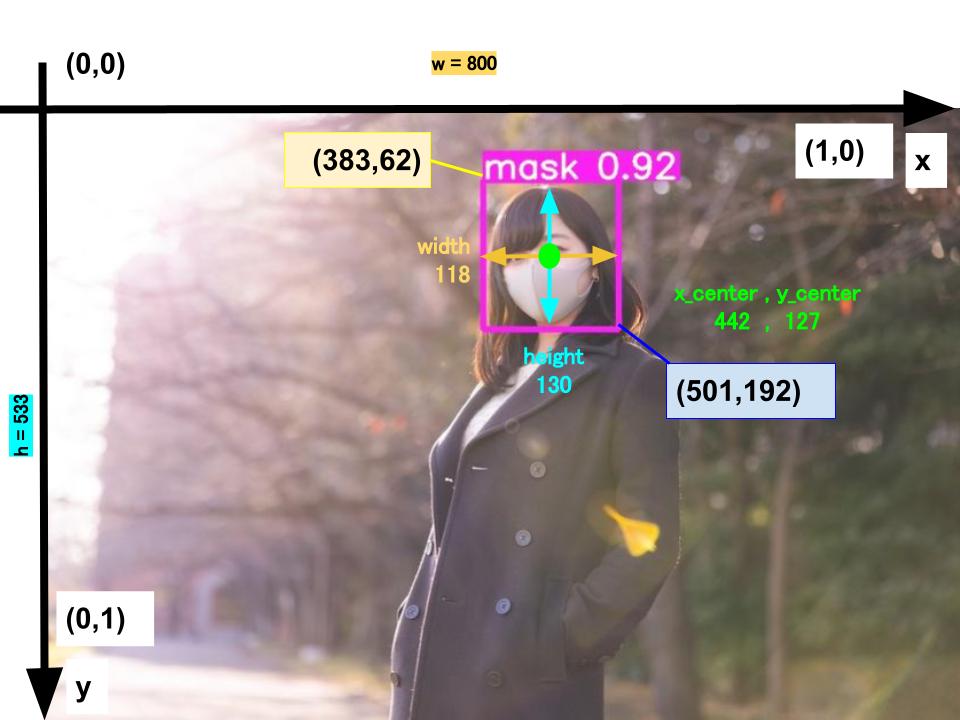
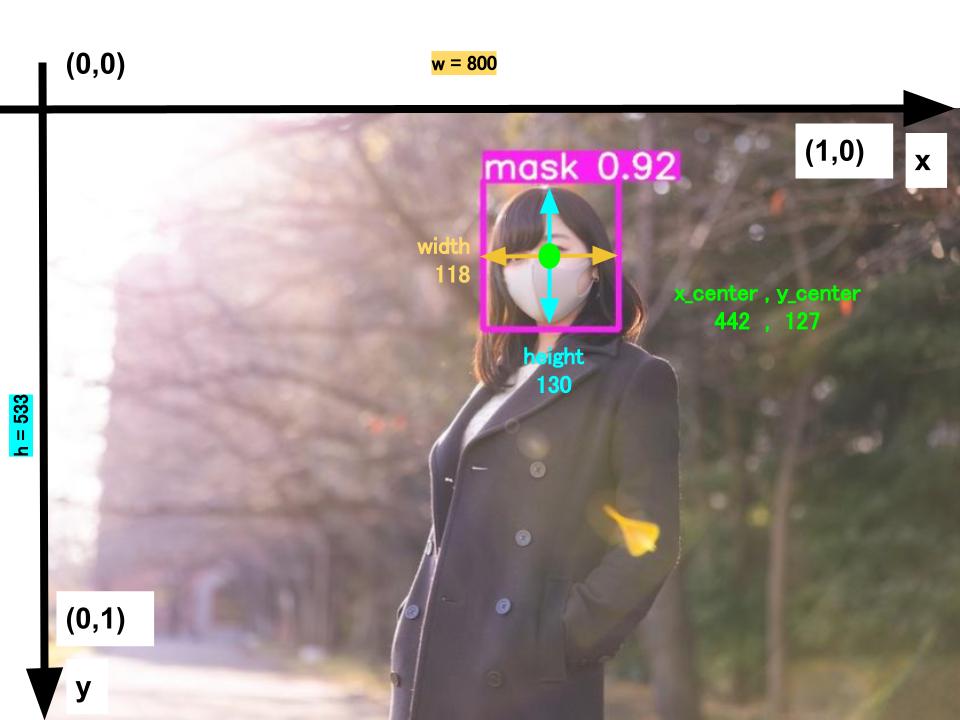
YOLOv7では画像1枚に対して、1つのテキストファイル(例:教師画像「mask.jpg」に対して「mask.txt」)が必要となります。
1枚の画像の中に検出対象が複数ある時は、改行して同様に座標データを入力していきます。
画像に対して座標を入力して、テキストファイルを作っていく作業をアノテーションと言います。
以降では、このアノテーションの省力化のための方法を紹介していきます。
アノテーションツール
アノテーション作業を行う際には、フリーツールを使用することが一般的です。ここでは代表的なツールを紹介します。
vott2
Microsoft が公開しているアノテーションツールです。
こちらからダウンロードして使用してください。
Label me
LabelMeはMITよって開発された画像アノテーションツールです。
物体検出だけでセマンティックセグメンテ―ションやインスタンスセグメンテーションなどのアノテーションも行うことができます。
Anacondaで環境構築して、labelmeをインストールします。
pip install labelme以下の通り実行すると、画面が立ち上がります。
labelmeまずは「Open」ボタンから画像を選択します。

画像が表示されました。

次に「Edit」から「Creat Rectangle」を選択します。

検出対象を枠線で囲います。
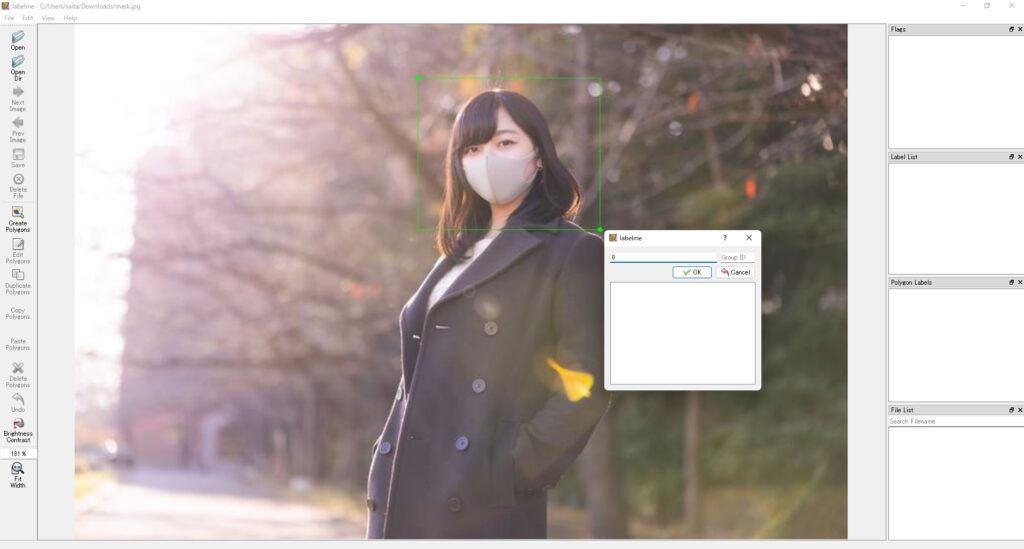
jsonファイルとして出力することができます。
OpenCVによるアノテーション
OpenCVからも画像の座標を取得することができます。
この方法は既存のアノテーションツールよりも自由度が高く、カスタマイズしたい方向けとなります。
ここではYOLOv7 で学習できる形式のアノテーションファイルを出力する方法を紹介します。
Anacondaで環境構築して、以下の通り実行します。
import cv2
import numpy as np
drawing = False
ix = -1
iy = -1
results = list()
def onMouse(event, x, y, flag, params):
global drawing, ix, iy
wname, img = params
if event == cv2.EVENT_LBUTTONDOWN:
drawing = True
ix, iy = x, y
if event == cv2.EVENT_MOUSEMOVE:
img2 = np.copy(img)
h,w = img2.shape[0], img2.shape[1]
if drawing == False:
cv2.line(img2, (x, 0), (x, h-1), (255, 0, 0))
cv2.line(img2, (0, y), (w-1, y), (255, 0, 0))
else:
cv2.rectangle(img2,(ix,iy),(x,y),(0,0,255),1)
cv2.imshow(wname, img2)
if event == cv2.EVENT_LBUTTONUP:
drawing = False
cv2.rectangle(img,(ix,iy),(x,y),(0,0,255),1
x_center = (ix+(x-ix)/2)/img.shape[1]
y_center = (iy +(y-iy)/2)/img.shape[0]
width = (x-ix)/img.shape[1]
height = (y-iy)/img.shape[0]
result = (str(label) + str(' ') + str(x_center)+str(' ')+str(y_center)+str(' ')+str(width)+str(' ')+str(height)+str(' ')+str('\n'))
results.append(str(result))入力画像を指定して実行すると画像が表示され、枠線で囲うことで座標を取得することができます。
以下の例ではラベルが単一である場合の例となります。
file_name = 'mask.jpg'
# ラベルの番号はここで変える
label = 0
img = cv2.imread(file_name)
wname='MouseEvent'
cv2.namedWindow(wname)
cv2.setMouseCallback(wname, onMouse, [wname, img])
cv2.imshow(wname, img)
while True:
cv2.imshow(wname, img)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cv2.destroyAllWindows()
with open(os.path.basename(file_name).strip(".jpg")+'.txt', 'w') as f:
f.writelines(results) 実行すると以下のような画面が出ますので、対象物を枠線で囲っていきましょう。

「q」キーを押すと、画面が閉じられると同時にアノテーションファイルが出力されます。
YOLOv7 で学習できる形式のアノテーションファイルを作ることができました。
Windows「ペイント」
画像の座標を確認するということであれば、windowsのペイントなども使うことができます。
windowsPCでアプリケーションをインストールできないなどの制約があるケースでは有効かもしれません。
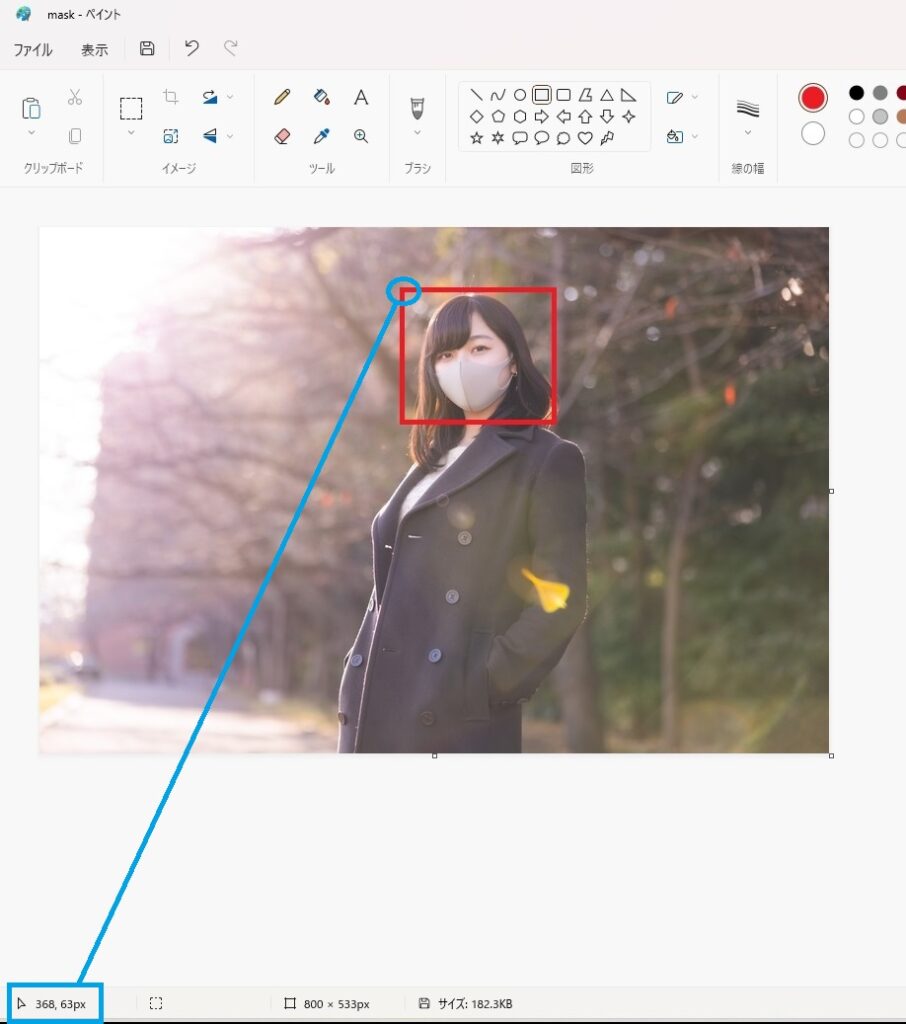
まずは対象物を長方形で囲います。
その後、左上にカーソルを合わせると、その座標が左下に表示されます。
この情報を元にアノテーションファイルを作成していきます。
左上の座標を(x1,y1)、右下の座標を(x2,y2)、画像サイズ(上の例だとW=800,H=533)として、以下のように換算します。
result = list()
label = 0
ymin = float(y1/H)
ymax = float(y2/H)
xmin = float(x1/W)
xmax = float(x2/W)
x_center = xmin + (xmax-xmin)/2
y_center = ymin + (ymax-ymin)/2
width = xmax-xmin
height = ymax-ymin
result.append(str(label)+str(' ')+str(x_center)+str(' ')+str(y_center)+str(' ')+str(width)+str(' ')+str(height)+str('\n'))これを対象物の数だけ繰り返していきます。
全ての物体に対して座標の把握が終わったら、テキストファイルとして出力しましょう。
import os
with open(os.path.basename(f).strip(".jpg")+'.txt', 'w') as f:
f.writelines(result) YOLOv7 で学習できる形式のアノテーションファイルを作ることができました。
まとめ
最後までご覧いただきありがとうございました。
今回はアノテーション作業に焦点を当て、様々な方法を紹介します。
物体検出のモデル作成にあたっては教師データの収集に加えて、検出対象物の座標を与える必要があります。
モデルの作成の際にはアノテーションを精度良くかつ効率的に行うようにしましょう。
次回は作成したデータを元に学習を実行します。
【物体検出2022】YOLOv7まとめ第5回 オリジナルデータセットの学習
YOLOシリーズの2022年最新版「YOLOv7」について、環境構築から学習の方法までまとめます。 YOLOv7は2022年7月に公開された最新バージョンであり、速度と精度の面で限界を…


