YOLOシリーズの2022年最新版「YOLOv7」について、環境構築から学習の方法までまとめます。
YOLOv7は2022年7月に公開された最新バージョンであり、速度と精度の面で限界を押し広げています。
第7回目はYOLOv7によるInstance segmentationを紹介します。
Google colabを使用して簡単に最新の物体検出モデルを実装することができますので、ぜひ最後までご覧ください。
YOLOv7まとめシリーズはこちらからご覧いただけます。
今回の内容
・YOLOv7によるInstance segmentationの実装
YOLOv7とは
YOLOv7は2022年7月に公開された最新バージョンであり、速度と精度の面で限界を押し広げています。詳細は前回の記事で紹介しておりますのでよかったらご覧ください。
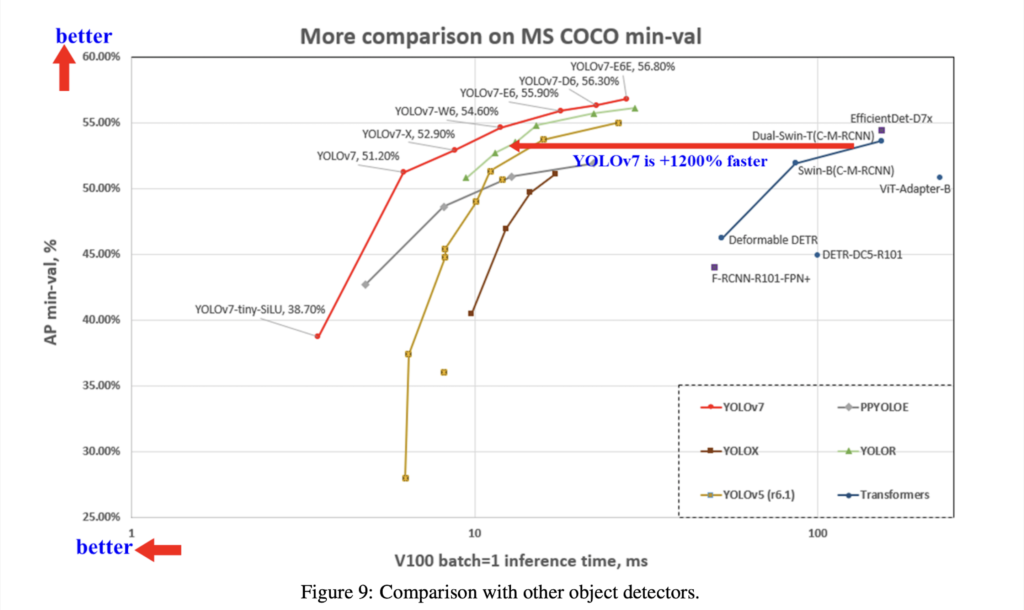
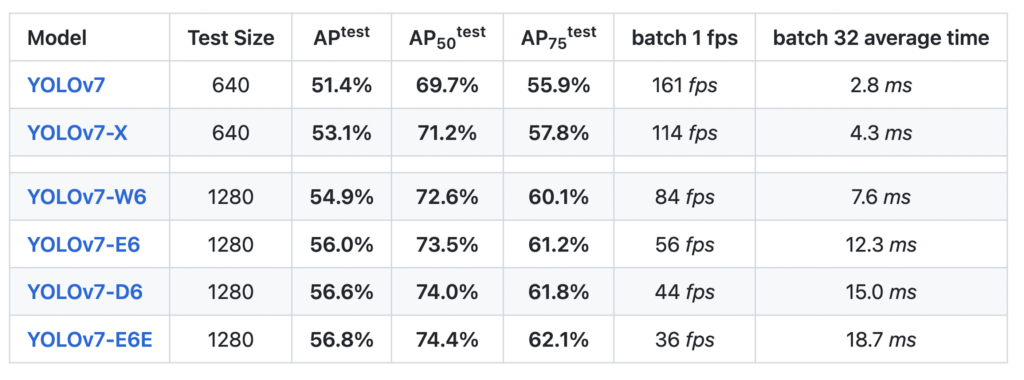
YOLOv7のベンチマーク結果は以下となっています。
なお、YOLOv7のライセンスは「GNU General Public License v3.0」となっています。とは
Instance segmentationとは
画像のセグメンテーションタスクについて紹介します。
セマンティック セグメンテーション
画像全体や画像の一部分の検出ではなく、ピクセル(画素)ごとに示す意味をラベル付けしていく手法です。
画像のピクセルがどのカテゴリに属するかで分類し、何が写っているかのラベル付けやカテゴリ関連付けを行います。
物体の種類ごとに領域分割し、物体が重なっているときにはそれぞれの区別ができませんが、背景や車、人など不定形の領域を検出することが可能です。
インスタンス セグメンテーション
画像中の全ての物体に対して(物体検出をした領域を対象)クラスラベルを予測し、一意のIDを付与することを目的と手法です。
不定形の領域は扱えませんが、隣接した同種類の物体は区別できます。
例えば、各物体に対して一意のIDを付与するため、1つの画像に複数の人が写っている場合にはそれぞれの車を別々の物体と認識することが可能です。

パノプティック セグメンテーション
セマンティックセグメンテーションとインスタンスセグメンテーションを組み合わせた方法です。
すべてのピクセルにラベルがふられて、数えられる物体に関して個別で認識した結果が出てきます。
個々の物体をそれぞれ分離しつつ、壁や床などはひとまとめにすることがでます。

導入
ここからはGoogle colabを使用して実装していきます。
まずはGPUを使用できるように設定をします。
「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をGPUに変更
今回紹介するコードは以下のボタンからコピーして使用していただくことも可能です。
![]()
GPUの設定が終わったら、フォルダを作成してGoogleドライブをマウントしましょう。
from google.colab import drive
drive.mount('/content/drive')
#専用のフォルダを作成する
!mkdir -p '/content/drive/My Drive/yolov7_segmentation/'
%cd '/content/drive/My Drive/yolov7_segmentation/'ブランチをクローン
次に公式実装からブランチをクローンします。
!git clone -b mask https://github.com/WongKinYiu/yolov7
# ブランチをクローンする場合
# !git clone -b ブランチ名 リポジトリ次に必要なライブラリをインストールします。
%cd yolov7
!pip install -r requirements.txtDetectron2をクローン
Detectron2が必要となりますので、合わせて準備します。
!git clone https://github.com/facebookresearch/detectron2今回必要なフォルダを取り出すため、まずは先程クローンしたフォルダの名前を変更します。
%mv ./detectron2 ./detectron次に今回必要となるDetectron2のサブフォルダを移動します。
%mv ./detectron/detectron2 ./Pytorchと他のライブラリをインストール
%cd '/content/drive/My Drive/yolov7_segmentation/yolov7'必要となるPytorchのバージョンを指定してインストールします。
!pip install torchvision==0.10.1
!pip install torch==1.9.1その他、必要となるものもインストールします。
!pip install fvcore
!pip install omegaconf
!pip install fairscale
!pip install timm以上で準備が完了しました。
学習済モデルのダウンロード
最後の学習済モデルをダウンロードしましょう。
以下のコマンドで公式ページよりダウンロードすることができます。
!wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-mask.ptセグメンテーションの実装
いよいよセグメンテーションを実装します。
まずは先程用意したライブラリをそれぞれインポートします。
import matplotlib.pyplot as plt
import torch
import cv2
import yaml
from torchvision import transforms
import numpy as np
from utils.datasets import letterbox
from utils.general import non_max_suppression_mask_conf
from detectron2.modeling.poolers import ROIPooler
from detectron2.structures import Boxes
from detectron2.utils.memory import retry_if_cuda_oom
from detectron2.layers import paste_masks_in_image次に学習済モデルを読み込みます。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
with open('data/hyp.scratch.mask.yaml') as f:
hyp = yaml.load(f, Loader=yaml.FullLoader)
weigths = torch.load('yolov7-mask.pt')
model = weigths['model']
model = model.half().to(device)
_ = model.eval()次にテスト画像を読み込みます。
今回使用する画像は毎度おなじみの画像です。

image = cv2.imread('./inference/images/horses.jpg')
image = letterbox(image, 960, stride=64, auto=True)[0]
image_ = image.copy()
image = transforms.ToTensor()(image)
image = torch.tensor(np.array([image.numpy()]))
image = image.to(device)
image = image.half()
output = model(image)推論の結果を返します。
inf_out, train_out, attn, mask_iou, bases, sem_output = output['test'], output['bbox_and_cls'], output['attn'], output['mask_iou'], output['bases'], output['sem']
bases = torch.cat([bases, sem_output], dim=1)
nb, _, height, width = image.shape
names = model.names
pooler_scale = model.pooler_scale
pooler = ROIPooler(output_size=hyp['mask_resolution'], scales=(pooler_scale,), sampling_ratio=1, pooler_type='ROIAlignV2', canonical_level=2)
output, output_mask, output_mask_score, output_ac, output_ab = non_max_suppression_mask_conf(inf_out, attn, bases, pooler, hyp, conf_thres=0.25, iou_thres=0.65, merge=False, mask_iou=None)
pred, pred_masks = output[0], output_mask[0]
base = bases[0]
bboxes = Boxes(pred[:, :4])
original_pred_masks = pred_masks.view(-1, hyp['mask_resolution'], hyp['mask_resolution'])
pred_masks = retry_if_cuda_oom(paste_masks_in_image)( original_pred_masks, bboxes, (height, width), threshold=0.5)
pred_masks_np = pred_masks.detach().cpu().numpy()
pred_cls = pred[:, 5].detach().cpu().numpy()
pred_conf = pred[:, 4].detach().cpu().numpy()
nimg = image[0].permute(1, 2, 0) * 255
nimg = nimg.cpu().numpy().astype(np.uint8)
nimg = cv2.cvtColor(nimg, cv2.COLOR_RGB2BGR)
nbboxes = bboxes.tensor.detach().cpu().numpy().astype(np.int)最後に得られた結果にしたがって、画像をマスクします。
pnimg = nimg.copy()
for one_mask, bbox, cls, conf in zip(pred_masks_np, nbboxes, pred_cls, pred_conf):
if conf < 0.25:
continue
color = [np.random.randint(255), np.random.randint(255), np.random.randint(255)]
pnimg[one_mask] = pnimg[one_mask] * 0.5 + np.array(color, dtype=np.uint8) * 0.5結果を表示してみましょう。
%matplotlib inline
plt.figure(figsize=(8,8))
plt.axis('off')
plt.imshow(pnimg)
plt.show() 
正しくセグメンテーションができていることがわかります。
物体検出の情報を付加する
今度はバウンディングボックスとスコアも同時に表示してみます。
pnimg = nimg.copy()
for one_mask, bbox, cls, conf in zip(pred_masks_np, nbboxes, pred_cls, pred_conf):
if conf < 0.25:
continue
color = [np.random.randint(255), np.random.randint(255), np.random.randint(255)]
pnimg[one_mask] = pnimg[one_mask] * 0.5 + np.array(color, dtype=np.uint8) * 0.5
pnimg = cv2.rectangle(pnimg, (bbox[0], bbox[1]), (bbox[2], bbox[3]), color, 2)
label = '%s %.3f' % (names[int(cls)], conf)
t_size = cv2.getTextSize(label, 0, fontScale=0.5, thickness=1)[0]
c2 = bbox[0] + t_size[0], bbox[1] - t_size[1] - 3
pnimg = cv2.rectangle(pnimg, (bbox[0], bbox[1]), c2, color, -1, cv2.LINE_AA) # filled
pnimg = cv2.putText(pnimg, label, (bbox[0], bbox[1] - 2), 0, 0.5, [255, 255, 255], thickness=1, lineType=cv2.LINE_AA) %matplotlib inline
plt.figure(figsize=(8,8))
plt.axis('off')
plt.imshow(pnimg)
plt.show() 
セグメンテーションと合わせて、バウンディングボックスとスコアも表示することができました。
まとめ
最後までご覧いただきありがとうございました。
Instance segmentationの実装方法を紹介しました。
物体検出の活用の幅がさらに広がりそうですね。
次回は物体追跡を紹介します。
【物体検出2022】YOLOv7まとめ第8回 BoT-SORTで物体追跡(MOT)を実装する
YOLOシリーズの2022年最新版「YOLOv7」について、環境構築から学習の方法までまとめます。 YOLOv7は2022年7月に公開された最新バージョンであり、速度と精度の面で限界を…


