物体検出でお馴染みのYOLOシリーズの最新版「YOLOv7」について、動かしながら試していきます。
YOLOv7は2022年7月に公開された最新バージョンであり、速度と精度の面で限界を押し広げています。
Google colabを使用して簡単に最新の物体検出モデルを実装することができますので、ぜひ最後までご覧ください。
今回の内容
・YOLOv7の概要
・Google colabを使用してYOLOv7の導入
・チュートリアルの推論
YOLOv7とは
YOLOv7は2022年7月に公開された最新バージョンであり、5FPSから160FPSの範囲で速度と精度の両方ですべての既知のオブジェクト検出器を上回り、速度と精度の面で限界を押し広げています。
これまでのYOLOR、YOLOX、Scaled-YOLOv4、YOLOv5、 DETR、Deformable DETR、DINO-5scale-R50、ViT-Adapter-Bなどと比較しても速度と精度における他の多くのオブジェクト検出器を上回る結果を出しています。
特にYOLOv7-E6オブジェクト検出器(56 FPS V100、55.9%AP)は、トランスフォーマーベースの検出器SWIN-LカスケードマスクR-CNN(9.2 FPS A100、53.9%AP)よりも速度が509%、精度が2%が上回っており、畳み込みベースの検出器ConvNeXt-XLカスケードマスクR-CNN(8.6 FPS A100、55.2%AP)に対しても、速度が551%、精度が0.7%上回る性能を誇ります。
リアルタイム物体検出器に対して、パラメータを効果的に利用できる「拡張」及び「複合スケーリング」手法により、リアルタイム物体検出器のパラメータを約40%、計算量を約50%削減することができるとしています。
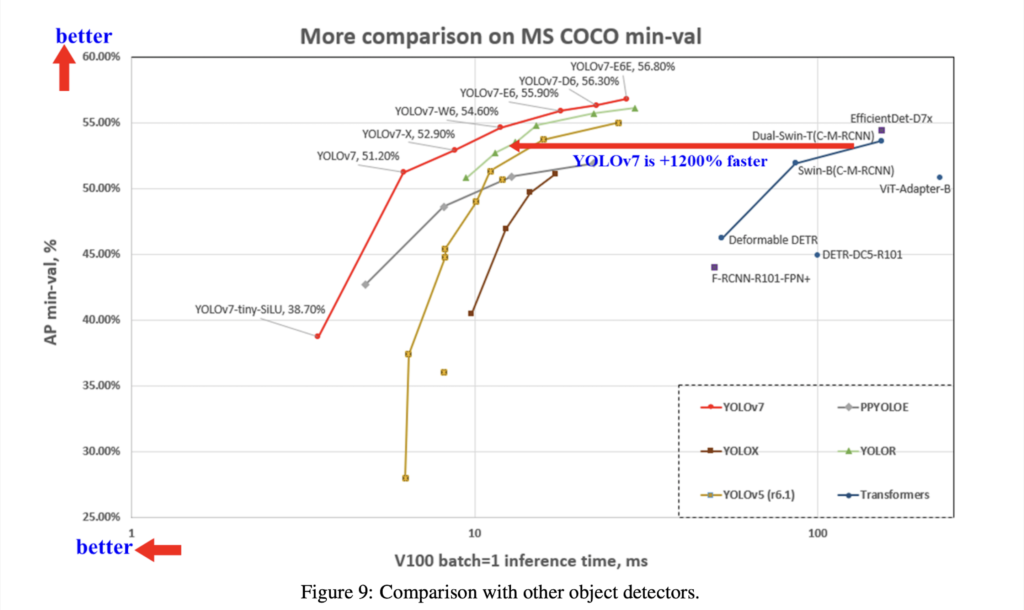
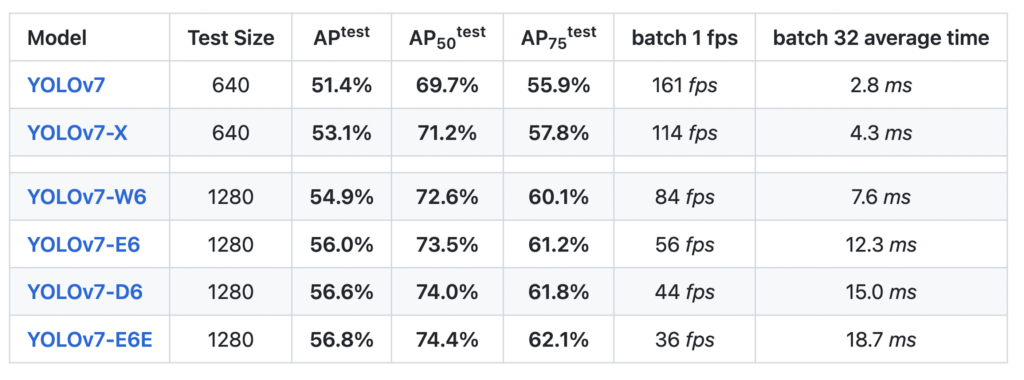
YOLOv7のベンチマーク結果は以下となっています。
なお、YOLOv7のライセンスは「GNU General Public License v3.0」となっています。
YOLOv7の導入
早速YOLOv7を使って動かしていきましょう。
ここからはGoogle colabを使用して実装していきます。
まずはGPUを使用できるように設定をします。
「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をGPUに変更
GPUの設定が終わったら、Googleドライブをマウントします。
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive公式よりcloneしてきます。
!git clone https://github.com/WongKinYiu/yolov7次に必要なライブラリをインポートします。
公式ではDockerを推奨していますが、ここではpipでインストールすることにします。
%cd yolov7
!pip install -r requirements.txt以上で準備完了です。
YOLOv7を使えるようになりました。
YOLOv7の動作確認
まずは動作確認をしてみましょう。
(動作確認は飛ばしても問題ありません。)
下記のコードを実行するとcocoデータセットに対して、YOLOv7の性能を見ることができます。
!python test.py --data data/coco.yaml --img 640 --batch 32 --conf 0.001 --iou 0.65 --device 0 --weights yolov7.pt --name yolov7_640_val学習済みモデルを使った推論デモ
サンプル画像で試してみる
ここからは推論デモを試してみましょう。
まずは学習済みモデルを取得します。
冒頭紹介した通り、いくつかの学習済みモデルがあります。
ここでは、最も精度が高い「yolov7-e6e.pt」を使うことにします。
下記の通り実行してモデルをダウンロードしましょう。
!wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-e6e.pt次に推論を実施します。
サンプル画像として「yolov7/inference/images/horses.jpg」が用意されています。
このサンプル画像を指定しましょう。
!python detect.py --source inference/images/horses.jpg --weights yolov7-e6e.pt --conf 0.25 --img-size 1280 --device 0実行すると「yolov7/runs/detect/exp」のフォルダ内に結果が保存されます。
中身を確認してみると、馬が高精度で検出できていることがわかります。

簡単に物体検出を実装することができました。
任意の画像で試してみる
次に推論デモを任意の画像でも試してみましょう。
画像を用意したら先ほどの「horses.jpg」がある「yolov7/inference/images/」に画像を保存しましょう。
保存したら先ほど同様に推論デモを実行します。
「--source」の引数をアップロードした画像「inference/images/dog.jpg」に変えましょう。
!python detect.py --source inference/images/dog.jpg --weights yolov7-e6e.pt --conf 0.25 --img-size 1280 --device 0実行すると、「yolov7/runs/detect/exp2」に結果が保存されます。

任意の画像でも推論デモを簡単に実行することができました。
任意の動画で試してみる
動画でも試してみましょう。
「yolov7/inference/images/」に動画を保存して、同様に推論デモを実行します。
!python detect.py --source inference/images/road.mp4 --weights yolov7-e6e.pt --conf 0.25 --img-size 1280 --device 0任意の動画で推論デモを簡単に実行することができました。
まとめ
最後までご覧いただきありがとうございました。
2022年7月に公開された物体検出でお馴染みのYOLOシリーズの最新バージョンである「YOLOv7」について、動かしながら試してみました。
精度・推論速度ともに向上しており、非常に使いやすいものになっています。
物体検出の活用の幅がさらに広がりそうですね。
次回はYOLOv7による学習及び推論の方法をまとめますので、ぜひ合わせてご覧ください。

