このシリーズでは物体検出でお馴染みのYOLOシリーズの2022年最新版「YOLOv7」について、環境構築から学習の方法までまとめます。
YOLOv7は2022年7月に公開された最新バージョンであり、速度と精度の面で限界を押し広げています。
第3回目では、物体検出のデータセット作成のための教師画像データ収集に焦点を当て、ネット上から収集可能な方法を紹介します。
ぜひ最後までご覧ください。
今回の目標
・オープンデータの活用
・スクレイピング
・YouTube動画の活用
・オープンモデルの活用
オープンデータの活用
現在は多くの画像のデータセットが公開されています。作りたいモデルに応じて適切な画像を使用するようにします。
ここでは無料で使用できるデータセットを紹介します。
画像・動画データ
ここで紹介するものは画像のみのデータとなりますので、自身でアノテーションを行うか、学習済みモデル等を活用してアノテーションファイルを作成する必要があります。
The CIFAR-10 dataset
10クラスの60000 32×32カラーイメージで構成され、クラスごとに6000イメージがあり、 50000個のトレーニング画像と10000個のテスト画像があります。
The CIFAR-100 dataset
それぞれ600個の画像を含む100個のクラスがあり、クラスごとに500のトレーニング画像と100のテスト画像があります。
Fashion-MNIST
ファッションの画像を対象としたデータセットで、Tシャツ、ズボン、ドレス、スニーカーなど10個のカテゴリでラベリングされています。
Deep Fashion
80万以上、50カテゴリからなるファッション画像データセットです。
MegaFace
ノイズデータを混ぜた顔認識と大規模なデータセットで、ワシントン大学で行われている顔認識アルゴリズムの公開競技で使用されています。
ImageNet
1,400万枚以上のデータセットで、文字列検索をすると検索単語に合ったクラスが出てくるのでデータ取得しやすくなっています。
SUN dataset
シーン認識・分類に利用できる899のカテゴリと130,519の画像を含む広範囲のシーンUNderstanding (SUN) データベースです。
Natural Adversarial Examples
機械学習のモデルが間違いを犯すように意図的に用意されたデータセットで、機械学習モデルの性能を著しく低下させるためのものであるので、使用の際は注意してください。
rois-codh/kmnist
くずし字漢字は、漢字3832字(64x64階調、140,426画像)、Kuzushiji-49はその名の通り49クラス(28x28 グレースケール、270,912画像)で、48文字のひらがなと1文字のひらがな反復記号を含むデータセットです。
Stanford Drone Dataset
スタンフォード大学のドローンから撮影された歩行者、自転車、スケートボーダー、車、バス、ゴルフカートなどの画像データセットです。それぞれラベル付けがされています。
Indoor Scene Recognition
屋内シーン認識モデルのための屋内画像データセットです。67の屋内カテゴリと合計15620の画像が含まれています。
YouTube-8M Dataset
Google研究チームが公開する、4800件のナレッジグラフのエンティティでタグ付けされた800万本ものYouTube動画のデータセットです。1000クラスの約237Kセグメントで人間が検証したラベルを収集しています。
アノテーションデータ付きの画像・動画データ
画像とアノテーションデータがセットになっているオープンデータもあります。
こちらはデータセットをそのまま利用することで、すぐに物体検出の学習を始めることができます。
COCO 2017
約16万枚の画像上に対して、カテゴリ数約80クラスのBounding boxがセットになっています。
Open Images Dataset
約190万枚の画像上に対して、カテゴリ数約600クラスの合計約1600万個のBounding boxがセットになっています。アノテーションはCC BY 4.0ライセンス、画像自体はCC BY 2.0ライセンスとなっています。
roboflow Computer Vision Datasets
2021年8月に50のオープンソースデータセットでリリースされ、パブリックプランでコンピュータービジョンインフラストラクチャ製品を無料で公開されています。コンピュータービジョンモデルの構築に利用できる6,600万以上の画像を含む、90,000以上のデータセットと、アプリケーションで使用できるAPIを備えた7,000以上の事前トレーニング済みモデルがあります。
Google Open Image V6
Googleが公開している、画像とアノテーションデータがセットになっている約900万枚のデータセットです。
The Oxford-IIIT Pet Dataset
各クラスに約200枚の画像を持つ37カテゴリのペットデータセットです。画像はスケール、ポーズ、照明に大きなバリエーションがなどがあり、アノテーションが付与されています。
CelebA Dataset
20万枚以上の著名人画像にそれぞれ40の属性情報を付与した大規模な顔属性データセットである。5つのランドマーク位置、1画像あたり40の2値属性アノテーションが含まれている。
YouTube-BoundingBoxes Dataset
動画にバウンディングボックスがラベリングされたの大規模なデータセットです。 データセットは、24万のさまざまな一般公開のYouTubeビデオから抽出された約380,000の15-20のビデオセグメントで構成され、編集や後処理を行わずに自然な設定でオブジェクトを自動的に選択することができます。
スクレイピング
インターネット上にあるデータを収集するスクレイピング技術を用いて画像を収集することが可能です。
ここでは「icrawler」を用いたWebスクレイピングによる画像収集を紹介します。
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDriveスクレイピングに必要なライブラリをインストールします。
!pip install icrawlerここでは「犬」の画像を集める例を示します。
from icrawler.builtin import BingImageCrawler
crawler = BingImageCrawler(storage={"root_dir": "dogs"})
crawler.crawl(keyword="犬", max_num=10)
#keyword="犬":集めたい画像のキーワードを指定する
#max_num=10:収集する画像の最大枚数(あまり大きくしすぎない)これを実行すると、「YOLOX/dogs」に犬の画像が10枚ほどアップされています。
画像を収集する際は「犬 ブルドッグ」や「犬 ペット」などキーワードを変えて収集してみましょう。
YouTubeなどの動画サイト
YouTubeなどの動画サイトには様々なジャンルの動画がありますので、教師画像として活用することが可能です。
動画を保存したのち、必要な部分を画像として使用しましょう。
ここからはYouTube動画をダウンロードする方法を紹介します。
まずは「youtube_dl」をインストールしましょう。
!pip install youtube_dlあとは最後の行のURLを変更するだけで、動画のダウンロードができます。
from yt_dlp import YoutubeDL
# ダウンロード条件を設定する。今回は画質・音質ともに最高の動画をダウンロードする
ydl_opts = {'format': 'best'}
# 動画のURLを指定
with YoutubeDL(ydl_opts) as ydl:
ydl.download(['https://youtu.be/NuoLQeP4xIU'])詳細は以下の記事で紹介しておりますので、合わせてご覧ください。
【Python活用】「yt-dlp」を使ってYouTube動画や音楽をダウンロードする
このシリーズでは、Pythonの様々な活用の方法を紹介しています。 今回は、PythonでYouTube動画を簡単にダウンロードする方法を紹介します。 Google colabを使用して簡単に…

以下の通り実行すると、ダウンロードした動画を画像に変換することができます。
import os
import cv2
def save_all_frames(video_files):
video = cv2.VideoCapture(video_files)
num = 0
while(video.isOpened()):
ret, frame = video.read()
if ret == True:
cv2.imwrite(os.path.basename(video_files).strip(".mp4") + "_{:0=10}".format(num) + ".jpg",frame)
num += 1
else:
break
video.release()
video = 'road.mp4'
save_all_frames(video)フレームごとに画像が出力されますので、必要な箇所を教師画像として使用することができます。
オープンモデルの活用
公開されている学習済みモデルを活用して、画像とアノテーションデータを抽出することが可能です。
推論結果から得られた座標をYOLov7で使えるデータに変換して、教師データとして活用しましょう。
Detic
Meta(旧 Facebook)が2022年1月に発表した新しい物体検出器であるDetic(Detecting Twenty-thousand Classes using Image-level Supervision)では2万種類の物体検出が可能です。
このモデルのテスト結果を活用することで、新たに作成するモデルの教師データとすることができます。
【物体検出】2万種類の物体検出ができるDeticを使って物体検出結果のCSV出力とマスク画像作成をする
Meta(旧 Facebook)が2022年1月に発表した新しい物体検出器であるDetic(Detecting Twenty-thousand Classes using Image-level Supervision) […]

YOLOX
過去に作成したモデルのテスト結果を活用することで、新たに作成するモデルの教師データとすることができます。
公開されている学習済モデルを用いることで、画像データとアノテーションデータをセットで取得することができます。
【物体検出】YOLOXまとめ|第4回:ONNXRuntimeとテスト結果(スコア、座標)の出力方法
このシリーズでは物体検出でお馴染みのYOLOシリーズの最新版「YOLOX」について、環境構築から学習の方法までまとめます。 YOLOXは2021年8月に公開された最新バージョンで…

YOLOv5
過去に作成したモデルのテスト結果を活用することで、新たに作成するモデルの教師データとすることができます。
公開されている学習済モデルを用いることで、画像データとアノテーションデータをセットで取得することができます。
🔰YOLOv5で実装する物体検出入門|第7回:動画の物体検出 〜座標やスコアのCSV出力とその応用
このシリーズでは物体検出でお馴染みの「YOLOv5」を用いて、物体検出の実装を基礎から学ぶことができます。 環境構築から学習の方法、さらに活用方法までをまとめています…
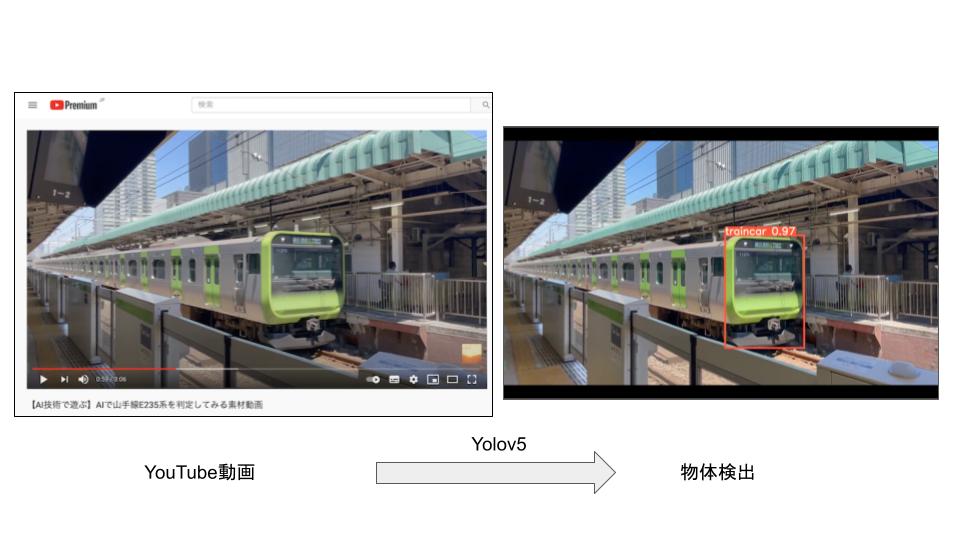
以下では、YOLOv5の学習モデルからYOLOv7の学習データを作成する方法を紹介します。
まずはYOLOv5を導入します。
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive
!git clone https://github.com/ultralytics/yolov5
%cd yolov5/
!pip install -qr requirements.txt次にモデルを指定します。
ここでは以前作成したモデルを使用して推論しています。
詳しい使い方はこちらの記事をご覧ください。
import torch
import glob
from PIL import Image
model = torch.hub.load('', 'custom', './weights/best.pt',source='local')最後に入力画像を指定して、YOLOv5による推論結果からYOLOv7用のファイルを出力しましょう。
files = glob.glob("*.jpg")
for f in files:
result = list()
im = Image.open(f)
imgs = [input_dir + os.path.basename(f)]
results = model(imgs)
results.print()
results.save(save_dir='runs/detect')
for j in range(len(results.pandas().xyxy[0])):
ymin = float((results.pandas().xyxy[0]["ymin"][j])/int(im.size[1]))
ymax = float((results.pandas().xyxy[0]["ymax"][j])/int(im.size[1]))
xmin = float((results.pandas().xyxy[0]["xmin"][j])/int(im.size[0]))
xmax = float((results.pandas().xyxy[0]["xmax"][j])/int(im.size[0]))
x_center = xmin + (xmax-xmin)/2
y_center = ymin + (ymax-ymin)/2
width = xmax-xmin
height = ymax-ymin
result.append(str(0)+str(' ')+str(x_center)+str(' ')+str(y_center)+str(' ')+str(width)+str(' ')+str(height)+str('\n'))
with open(os.path.basename(f).strip(".jpg")+'.txt', 'w') as f:
f.writelines(result) 画像とアノテーションファイルをセットで得ることができます。
過去に作成したモデルや公開されているモデルをうまく活用すれば、データセット作成の手間が省けそうですね。
まとめ
最後までご覧いただきありがとうございました。
深層学習のモデル作成にあたっては多くの教師データが必要となります。
効果的に画像収集を行い、精度の高いモデル作成を行っていきましょう。
次回はYOLOv7におけるアノテーションの方法を紹介します。
【物体検出2022】YOLOv7まとめ第4回 物体検出のためのアノテーション
このシリーズでは物体検出でお馴染みのYOLOシリーズの2022年最新版「YOLOv7」について、環境構築から学習の方法までまとめます。 YOLOv7は2022年7月に公開された最新バー…


