YOLOシリーズの2022年最新版「YOLOv7」について、環境構築から学習の方法までまとめます。
YOLOv7は2022年7月に公開された最新バージョンであり、速度と精度の面で限界を押し広げています。
第6回目はYOLOv7による姿勢推定(Human Pose Estimation)を紹介します。
Google colabを使用して簡単に最新の物体検出モデルを実装することができますので、ぜひ最後までご覧ください。
今回の内容
・YOLOv7によるHuman Pose Estimationの実装
・動画からHuman Pose Estimation
YOLOv7とは
YOLOv7は2022年7月に公開された最新バージョンであり、速度と精度の面で限界を押し広げています。詳細は前回の記事で紹介しておりますのでよかったらご覧ください。
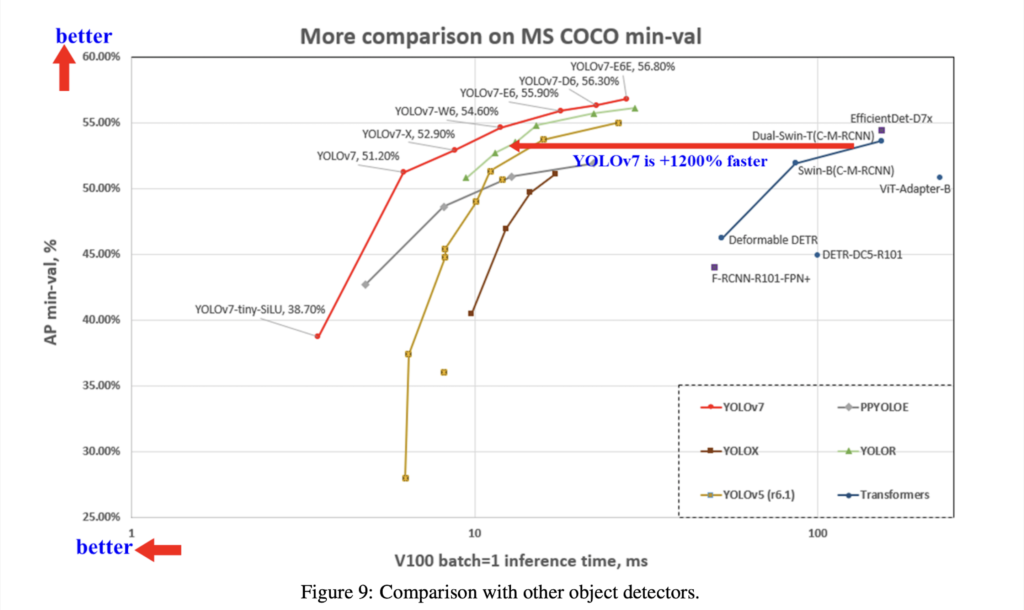
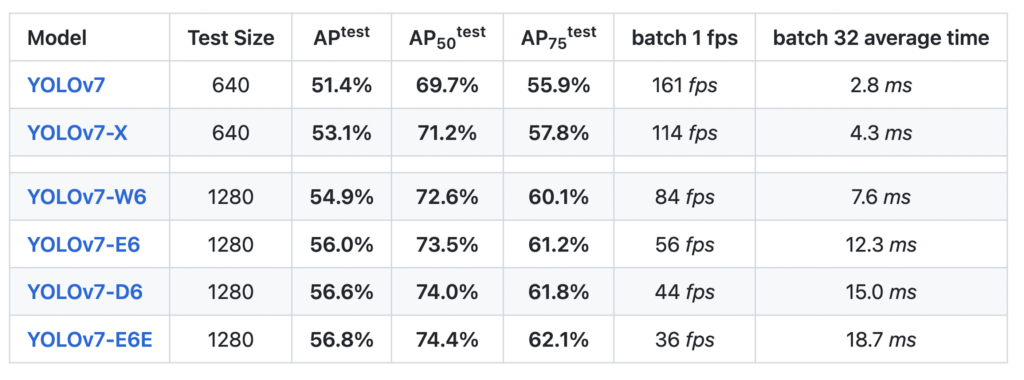
YOLOv7のベンチマーク結果は以下となっています。
なお、YOLOv7のライセンスは「GNU General Public License v3.0」となっています。とは
Human Pose Estimation(姿勢推定)とは
Human Pose Estimation(姿勢推定)とは、入力画像中の各人物に対して画像上のキーポイントと、それらを結ぶ2次元の直線的ボーン姿勢を推定するタスクです。
この技術を使うと、以下の画像や動画のように、人の骨格を検出することが可能です。

スポーツにおけるフォームの分析や、怪しい行動を検知、運転手の居眠りやよそ見の検知といったタスクに活用されています。
導入
ここからはGoogle colabを使用して実装していきます。
まずはGPUを使用できるように設定をします。
「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をGPUに変更
今回紹介するコードは以下のボタンからコピーして使用していただくことも可能です。
![]()
GPUの設定が終わったら、Googleドライブをマウントします。
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive公式よりcloneしてきます。
!git clone https://github.com/WongKinYiu/yolov7%cd yolov7今回使用する学習済モデルをダウンロードします。
# !wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-w6-pose.pt以上で準備完了です。
使用するサンプル画像
まずは既に用意されているサンプル画像を使用して、テストを実行します。
※「./inference/images/image2.jpg」にあります。

サンプル画像によるテスト
まずは必要なライブラリをインポートします。
import matplotlib.pyplot as plt
import torch
import cv2
from torchvision import transforms
import numpy as np
from utils.datasets import letterbox
from utils.general import non_max_suppression_kpt
from utils.plots import output_to_keypoint, plot_skeleton_kpts次に先程ダウンロードした学習済モデルを読み込みます。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
weigths = torch.load('yolov7-w6-pose.pt')
model = weigths['model']
model = model.half().to(device)
_ = model.eval()姿勢推定の処理を実行する関数を定義します。
def pose_estimation(img):
image = cv2.imread(img)
image = letterbox(image, 960, stride=64, auto=True)[0]
image_ = image.copy()
image = transforms.ToTensor()(image)
image = torch.tensor(np.array([image.numpy()]))
if torch.cuda.is_available():
image = image.half().to(device)
output, _ = model(image)
output = non_max_suppression_kpt(output, 0.25, 0.65, nc=model.yaml['nc'], nkpt=model.yaml['nkpt'], kpt_label=True)
with torch.no_grad():
output = output_to_keypoint(output)
nimg = image[0].permute(1, 2, 0) * 255
nimg = nimg.cpu().numpy().astype(np.uint8)
nimg = cv2.cvtColor(nimg, cv2.COLOR_RGB2BGR)
for idx in range(output.shape[0]):
plot_skeleton_kpts(nimg, output[idx, 7:].T, 3)
%matplotlib inline
plt.figure(figsize=(8,8))
plt.axis('off')
plt.imshow(nimg)
plt.show()最後に画像を指定して、処理を実行しましょう。
img = './inference/images/image2.jpg'
pose_estimation(img)動画でテスト
これらの処理を動画でも実装してみましょう。
先ほどと同様に必要なライブラリをインポートします。
import torch
import cv2
from torchvision import transforms
import numpy as np
import tqdm
from utils.datasets import letterbox
from utils.general import non_max_suppression_kpt
from utils.plots import output_to_keypoint, plot_skeleton_kpts次に先程ダウンロードした学習済モデルを読み込みます。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
weigths = torch.load('yolov7-w6-pose.pt')
model = weigths['model']
model = model.half().to(device)
_ = model.eval()動画を読み込み、姿勢推定の処理を実行する関数を定義します。
def process_keypoints(video_file, model, output_video_path):
video = cv2.VideoCapture(video_file)
writer = _create_vid_writer(video, output_video_path)
num_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
f_num = 0
pbar = tqdm.tqdm(total=num_frames, desc="inf")
while video.isOpened():
ret, frame = video.read()
if (frame is None):
break
pbar.update(1)
frame = letterbox(frame, 1280, stride=64, auto=True)[0]
frame_ = frame.copy()
frame = transforms.ToTensor()(frame)
frame = torch.tensor(np.array([frame.numpy()]))
frame = frame.to(device)
frame = frame.half()
output, _ = model(frame)
with torch.set_grad_enabled(False):
output = non_max_suppression_kpt(output, 0.25, 0.65, nc=model.yaml['nc'], nkpt=model.yaml['nkpt'], kpt_label=True)
output = output_to_keypoint(output)
nimg = frame[0].permute(1, 2, 0) * 255
nimg = nimg.cpu().numpy().astype(np.uint8)
nimg = cv2.cvtColor(nimg, cv2.COLOR_BGR2RGB)
nimg = cv2.cvtColor(nimg, cv2.COLOR_RGB2BGR)
for idx in range(output.shape[0]):
plot_skeleton_kpts(nimg, output[idx, 7:].T, 3)
writer.write(nimg)
torch.cuda.empty_cache()
video.release()
writer.release()最後に動画を出力する関数を定義します。
def _create_vid_writer(vid_cap, video_path):
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
writer = cv2.VideoWriter(video_path, cv2.VideoWriter_fourcc('m', 'p', '4', 'v'), fps, (1280,768))
return writer動画を指定して関数を実行しましょう。
※動画は各自で用意してください。ここではフリー動画を使用しています。
video_file = './inference/pose/pose.mp4'
video_output = 'pose.mp4'
process_keypoints(video_file, model, video_output)動画から姿勢推定を実装することができました。
動画もあわせてぜひ御覧ください。
まとめ
最後までご覧いただきありがとうございました。
YOLOv7による姿勢推定(Human Pose Estimation)を紹介しました。
精度・推論速度ともに向上しており、非常に使いやすいものになっています。
物体検出の活用の幅がさらに広がりそうですね。
次回はセグメンテーションの実装を紹介します。
【物体検出2022】YOLOv7まとめ第7回 Instance segmentationを実装する
YOLOシリーズの2022年最新版「YOLOv7」について、環境構築から学習の方法までまとめます。 YOLOv7は2022年7月に公開された最新バージョンであり、速度と精度の面で限界を…


