YOLOシリーズの2022年最新版「YOLOv7」について、環境構築から学習の方法までまとめます。
YOLOv7は2022年7月に公開された最新バージョンであり、速度と精度の面で限界を押し広げています。
第5回目は、オリジナルデータセットの学習の方法を紹介します。
Google colabを使用して簡単に最新の物体検出モデルを実装することができますので、ぜひ最後までご覧ください。
YOLOv7まとめシリーズはこちらからご覧いただけます。
今回の内容
・YOLOv7で必要となるデータセットの作成方法
・オリジナルデータの物体検出モデルを作成
YOLOv7とは
YOLOv7は2022年7月に公開された最新バージョンであり、速度と精度の面で限界を押し広げています。詳細は前回の記事で紹介しておりますのでよかったらご覧ください。
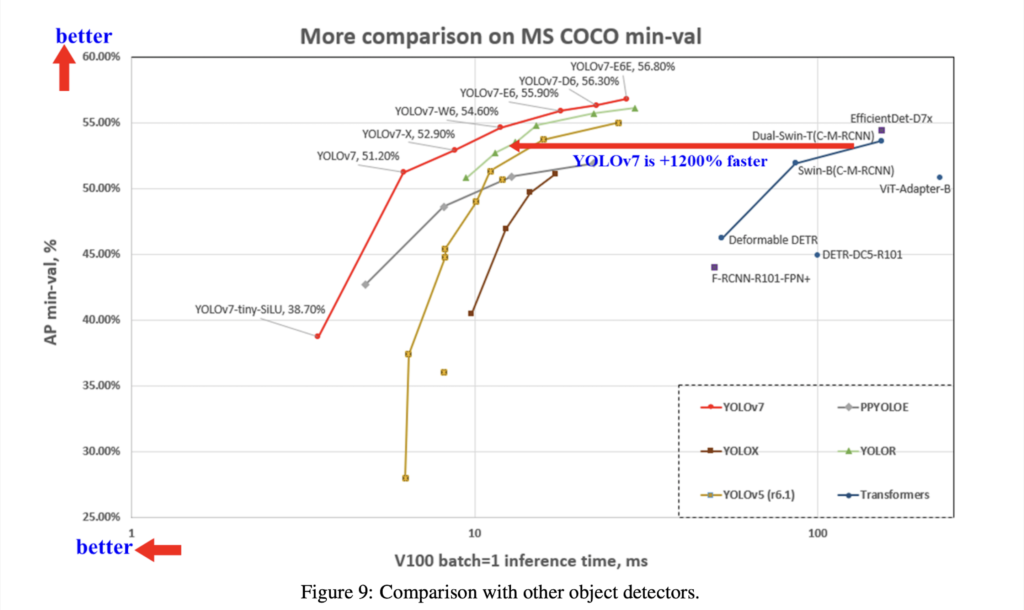
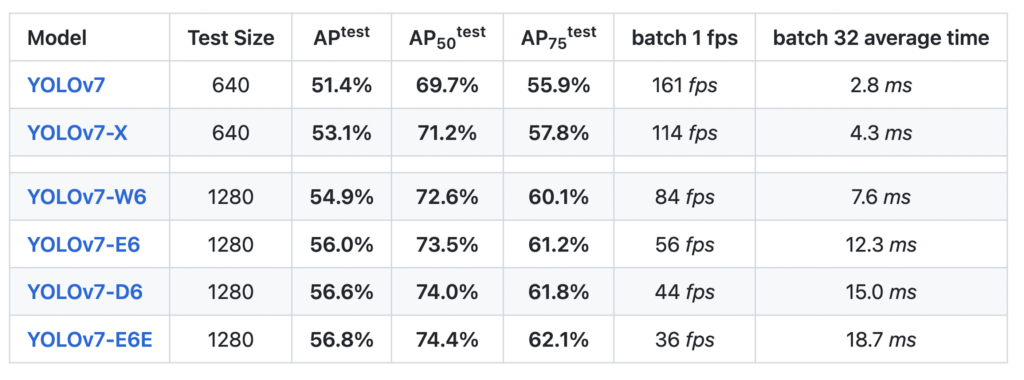
YOLOv7のベンチマーク結果は以下となっています。
なお、YOLOv7のライセンスは「GNU General Public License v3.0」となっています。
YOLOv7の導入
早速YOLOv7を使って動かしていきましょう。
ここからはGoogle colabを使用して実装していきます。
まずはGPUを使用できるように設定をします。
「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」をGPUに変更
今回紹介するコードは以下のボタンからコピーして使用していただくことも可能です。
![]()
GPUの設定が終わったら、Googleドライブをマウントします。
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive公式よりcloneしてきます。
!git clone https://github.com/WongKinYiu/yolov7次に必要なライブラリをインポートします。
公式ではDockerを推奨していますが、ここではpipでインストールすることにします。
%cd yolov7
!pip install -r requirements.txt最後に今回使用する学習済みモデルを取得します。
!wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7x.pt以上で準備完了です。
YOLOv7を使えるようになりました。
データセット作成のための教師画像収集
まずは教師画像を収集しましょう。
収集方法は対象となる画像によって異なりますが、ここでは比較的容易に収集が可能な方法をいくつか紹介します。
| オープンデータの活用 | 現在は多くの画像のデータセットが公開されています。作りたいモデルに応じて適切な画像を使用するようにします。 |
| スクレイピング | インターネット上にあるデータを収集するスクレイピング技術を用いて画像を収集することが可能です。 |
| YouTubeなどの動画サイト | YouTubeなどの動画サイトには様々なジャンルの動画がありますので、教師画像として活用することが可能です。 動画を保存したのち、必要な部分を画像として使用しましょう。 |
| オープンモデルの活用 | 公開されている学習済みモデルを活用して、画像とアノテーションデータを抽出することが可能です。 推論結果から得られた座標をYOLov7で使えるデータに変換して、教師データとして活用しましょう。 |
詳しくは以下の記事をご覧ください。
【物体検出2022】YOLOv7まとめ第3回 物体検出のためのデータ収集
このシリーズでは物体検出でお馴染みのYOLOシリーズの2022年最新版「YOLOv7」について、環境構築から学習の方法までまとめます。 YOLOv7は2022年7月に公開された最新バー…

アノテーション
アノテーションとは、あるデータに対して関連する情報(メタデータ)を注釈として付与することを言います。
機械学習においては、モデルに学習させるための教師データ(正解データ、ラベル)を作成することを指します。
物体検出でのアノテーションとは、画像の中における物体の位置(座標)を明示することを言います。
具体的には、以下の画像を例に取ると、マスク着用を検出するための座標をテキストファイルとして保存する作業と言い換えることもできます。
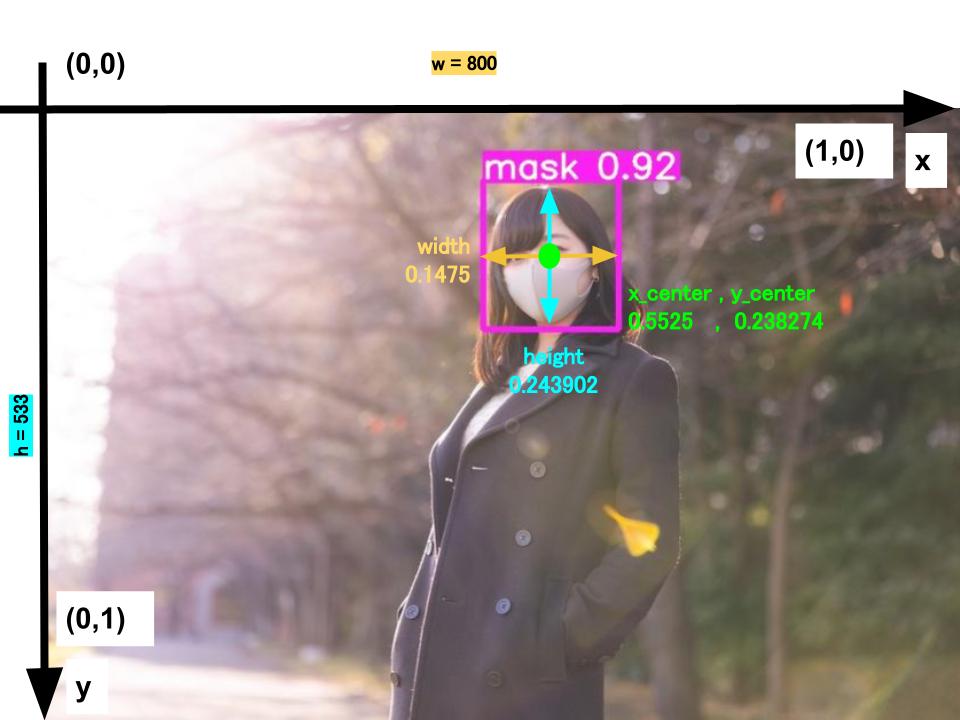
# [oject-class] [x_center] [y_center] [width] [height]
0 0.5525 0.238274 0.1475 0.243902
#oject-class:クラスの番号。yamlファイルの内容と合わせる
#x_center:枠線中心のx座標
#y_center:枠線中心のy座標
#width:枠線x方向長さ
#height:枠線y方向長さ
# ymin = y1/h,ymax = y2/h,xmin = x1/w,xmax = x2/w
# x_center = xmin + (xmax-xmin)/2
# y_center = ymin + (ymax-ymin)/2
# width = xmax-xmin
# height = ymax-yminYOLOv7では画像1枚に対して、1つの同じ名前のテキストファイルが必要となります。
(「test.jpg」に対して、アノテーションファイル「test.txt」が必要)
1枚の画像の中に検出対象が複数ある時は、改行して同様に座標データを入力していきます。
画像に対して座標を入力して、テキストファイルを作っていく作業をアノテーションと言います。
アノテーションの具体的な方法はこちらの記事で紹介しております。
【物体検出2022】YOLOv7まとめ第4回 物体検出のためのアノテーション
このシリーズでは物体検出でお馴染みのYOLOシリーズの2022年最新版「YOLOv7」について、環境構築から学習の方法までまとめます。 YOLOv7は2022年7月に公開された最新バー…

データセットの格納
教師データの格納
教師画像とアノテーションファイルが完成したら、データを格納していきましょう。
まずはそれぞれのデータを学習用と評価用に分割します。
分割が終わったら、以下のようにフォルダ構成でデータを格納します。
images:教師画像(画像ファイル)、labels:アノテーションファイル(テキストファイル)
yolov7
┗ data
┗ train_car
┠ train
┃ ┠ images
┃ ┗ labels
┗ valid
┠ images
┗ labelsyamlファイルの作成
学習するにあたり必要な情報を記述したyamlファイルを作成します。
学習データのパスは上記で指定した通りです。任意の名前に変更しても問題ありません。
検出のクラス数は作成したデータセットに応じて設定します。
最後にそれぞれのクラス名を記述します。
クラス名称は辞書形式となっており、「651」はアノテーションファイル作成時に設定した「0」に相当します。
# 学習データのパスを指定する
train: .data/train_car/train/images
val: .data/train_car/valid/images
# 検出のクラス数
nc: 14
# クラス名
names: ['651','e231','e233','e235','e257','e259','e261','e353','e531','e657','ef81','ef210','eh200','eh500']このファイルをyolov7の直下にアップします。
yolov7
┠ data
┃ ┗ train_car
┃ ┗ …
┗ train_car.yaml以上で学習に必要なデータの準備が終わりました。
学習
はじめから学習する
早速、学習を実行しましょう。
batch-sizeを小さくしすぎると学習が途中で止まってしまいますので、注意してください。
Google colabで学習する場合にはinput sizeを640、batch-sizeを16とすれば問題なく学習ができます。
!python train.py --workers 8 --batch-size 16 --data train_car.yaml --cfg cfg/training/yolov7x.yaml --weights 'yolov7x.pt' --name yolov7x --hyp data/hyp.scratch.p5.yaml --epochs 300 --device 0 学習結果は「yolor/runs/train/yolov7x/」に保存されます。
評価指標も同じフォルダに保存されますので保存されますので確認してみましょう。
途中から学習する
Google colabで学習をすると、途中で接続が切れてしまうことがあるかと思います。
引数に「--resume」を追加することで、前回の途中から学習をすることができます。
!python train.py --workers 8 --batch-size 16 --data train_car.yaml --cfg cfg/training/yolov7x.yaml --weights 'yolov7x.pt' --name yolov7x --hyp data/hyp.scratch.p5.yaml --epochs 300 --device 0 --resume結果は先ほどと同様に保存されます。
テスト
テスト結果を出力する(画像)
学習した結果を用いてテストをしてみましょう。
先ほど学習したファイルを「--weights runs/train/yolov7x/weights/best.pt」、使用したい画像を「--source test.jpg」としてテストをします。
!python detect.py --weights runs/train/yolov7x/weights/best.pt --conf 0.25 --img-size 640 --source mask.jpg
「runs/detect/exp/」に画像が保存されました。
高い精度で検出できていることがわかりました。
※左の車両は学習対象外のため、検出されなくて問題ありません。
テスト結果を出力する(動画)
画像だけでなく動画でもテストすることができます。
先ほど学習したファイルを「--weights runs/train/yolov7x/weights/best.pt」、使用したい画像を「--source test.mp4」としてテストをします。
!python detect.py --weights runs/train/yolov7x/weights/best.pt --conf 0.25 --img-size 640 --source mask.mp4任意の動画で推論デモを簡単に実行することができました。
まとめ
最後までご覧いただきありがとうございました。
2022年7月に公開されたのYOLOシリーズの最新バージョンである「YOLOv7」について、オープンソースのデータセットを活用したマスク着用判定モデルの作成を通じて学習と評価の方法を紹介しました。
精度・推論速度ともに向上しており、非常に使いやすいものになっています。
物体検出の活用の幅がさらに広がりそうですね。
次回は姿勢推定の実装を紹介します。
【物体検出2022】YOLOv7まとめ第6回 姿勢推定(Human Pose Estimation)を実装する
YOLOシリーズの2022年最新版「YOLOv7」について、環境構築から学習の方法までまとめます。 YOLOv7は2022年7月に公開された最新バージョンであり、速度と精度の面で限界を…


