このシリーズでは、自然言語処理の環境構築から学習の方法までまとめます。
今回の記事ではGiNZAまとめ②として、形態素解析を中心に紹介します。
Google colabを使用して、簡単に最新の自然言語処理モデルを実装することができますので、ぜひ最後までご覧ください。
(前回の記事)
【🔰自然言語処理】GiNZAまとめ① 〜概要〜
このシリーズでは、自然言語処理の環境構築から学習の方法までまとめます。 今回の記事ではGiNZAまとめ①として、ライブラリの概要とどんな使い方ができるのかを紹介します…

今回の内容
・GiNZAの導入
・形態素解析
・品詞の抽出
・レンマの抽出
・係り受け解析
・分境界解析
GiNZAとは
「GiNZA」は、2019年4月に登場したオープンソースな日本語の自然言語処理ライブラリです。
最先端の機械学習技術を取り入れた自然言語処理ライブラリ「spaCy」をフレームワークとして利用しており、トークン化処理にオープンソースな形態素解析器「SudachiPy」が使われています。
「GiNZA日本語UDモデル」にはMegagon Labsと国立国語研究所の共同研究成果が組み込まれています。
詳細は公式の実装からご確認ください。
GiNZAの導入
ここからはGoogle colabを使用して、GiNZAによる形態素解析の簡単なを実装例を紹介していきます。
まずはインストールします。
# GiNZAのインストール
!pip install -U ginza動作確認をします。
import spacy
nlp = spacy.load('ja_ginza')以下のようなエラーが出た場合には、再度インストールします。
Can't find model 'ja_ginza'. It doesn't seem to be a shortcut link, a Python package or a valid path to a data directory.
!pip install ginza ja-ginza インストールが終わったら、ランタイムの再起動を行います。
形態素解析
それぞれの解析方法について紹介します。
形態素分割
形態素分割では、一連の文章から形態素(=言語が意味を持つ最小単位)に分割して出力します。
一般に形態素解析という場合には、この形態素分析を指す場合が多いです。
import spacy
nlp = spacy.load('ja_ginza')
doc = nlp('私は毎週水曜日にカフェで勉強します。その後、ジムに寄ってから帰ります。')
for token in doc:
print(token)実行すると、以下のような結果が出力されます。
私
は
毎週
水曜日
に
カフェ
で
勉強
し
ます
。
その
後
、
ジム
に
寄っ
て
から
帰り
ます
。形態素の分割モード
「GiNZA」では、3種類の形態素を切り替えて利用することができます。
全国高等学校野球選手権大会
分割単位A 全国/高等/学校/野球/選手/権/大会
分割単位B 全国/高等/学校/野球/選手権/大会
分割単位C 全国/高等学校/野球/選手権/大会分割単位A
import spacy
import ginza
nlp = spacy.load('ja_ginza')
ginza.set_split_mode(nlp, 'A') # 分割単位A
doc = nlp('夏の全国高等学校野球選手権大会に出場する')
for token in doc:
print(token)実行すると、以下のような結果が出力されます。
夏
の
全国
高等
学校
野球
選手
権
大会
に
出場
する分割単位B
import spacy
import ginza
nlp = spacy.load('ja_ginza')
ginza.set_split_mode(nlp, 'B') # 分割単位B
doc = nlp('夏の全国高等学校野球選手権大会に出場する')
for token in doc:
print(token)実行すると、以下のような結果が出力されます。
夏
の
全国
高等
学校
野球
選手権
大会
に
出場
する分割単位C
import spacy
import ginza
nlp = spacy.load('ja_ginza')
ginza.set_split_mode(nlp, 'C') # 分割単位C
doc = nlp('夏の全国高等学校野球選手権大会に出場する')
for token in doc:
print(token)実行すると、以下のような結果が出力されます。
夏
の
全国
高等学校
野球
選手権
大会
に
出場
する品詞の抽出
品詞の抽出
形態素解析から得られたトークンから名詞や動詞といった品詞を抽出することができます。
tokenプロパティは以下の通りです。
| token.i | トークン番号 |
| token.text | テキスト |
| token.lemma_ | レンマ |
| token.tag_ | 日本語の品詞タグ |
| token.pos_ | Universal Dependenciesの品詞タグ |
import spacy
nlp = spacy.load('ja_ginza')
doc = nlp('私は毎週水曜日にカフェで勉強します。その後、ジムに寄ってから帰ります。')
for token in doc:
print(
token.text+', '+ # テキスト
token.tag_+', '+ # SudachiPyの品詞タグ
token.pos_) # Universal Dependenciesの品詞タグ実行すると、以下のような結果が出力されます。
私, 代名詞, PRON
は, 助詞-係助詞, ADP
毎週, 名詞-普通名詞-副詞可能, NOUN
水曜日, 名詞-普通名詞-副詞可能, NOUN
に, 助詞-格助詞, ADP
カフェ, 名詞-普通名詞-一般, NOUN
で, 助詞-格助詞, ADP
勉強, 名詞-普通名詞-サ変可能, VERB
し, 動詞-非自立可能, AUX
ます, 助動詞, AUX
。, 補助記号-句点, PUNCT
その, 連体詞, DET
後, 名詞-普通名詞-副詞可能, NOUN
、, 補助記号-読点, PUNCT
ジム, 名詞-普通名詞-一般, NOUN
に, 助詞-格助詞, ADP
寄っ, 動詞-一般, VERB
て, 助詞-接続助詞, SCONJ
から, 助詞-格助詞, ADP
帰り, 動詞-一般, VERB
ます, 助動詞, AUX
。, 補助記号-句点, PUNCT品詞の一覧は以下のようになります。
・名詞-普通名詞-一般
・名詞-普通名詞-サ変可能
・名詞-普通名詞-形状詞可能
・名詞-普通名詞-サ変形状詞可能
・名詞-普通名詞-副詞可能
・名詞-普通名詞-助数詞可能
・名詞-固有名詞-一般
・名詞-固有名詞-人名-一般
・名詞-固有名詞-人名-姓
・名詞-固有名詞-人名-名
・名詞-固有名詞-地名-一般
・名詞-固有名詞-地名-国
・名詞-数詞
・名詞-助動詞語幹
・代名詞
・形状詞-一般
・形状詞-タリ
・形状詞-助動詞語幹
・連体詞
・副詞
・接続詞
・感動詞-一般
・感動詞-フィラー
・動詞-一般
・動詞-非自立可能
・形容詞-一般
・形容詞-非自立可能
・助動詞
・助詞-格助詞
・助詞-副助詞
・助詞-係助詞
・助詞-接続助詞
・助詞-終助詞
・助詞-準体助詞
・接頭辞
・接尾辞-名詞的-一般
・接尾辞-名詞的-サ変可能
・接尾辞-名詞的-形状詞可能
・接尾辞-名詞的-サ変形状詞可能
・接尾辞-名詞的-副詞可能
・接尾辞-名詞的-助数詞
・接尾辞-形状詞的
・接尾辞-動詞的
・接尾辞-形容詞的
・記号-一般
・記号-文字
・補助記号-一般
・補助記号-句点
・補助記号-読点
・補助記号-括弧開
・補助記号-括弧閉
・補助記号-AA-一般
・補助記号-AA-顔文字
・空白Universal Dependenciesの品詞タグの一覧は以下のようになります。
・NOUN : 名詞
・名詞-普通名詞 (但しVERB,ADJとして使われるものを除く) (例: パン)
・PROPN : 固有名詞
・名詞-固有名詞 (例: 大阪)
・VERB : 動詞
・動詞(但し非自立となるものを除く) (例: 食べる)
・名刺+サ変可能で動詞の語尾が付いたもの (例: '食事'する)
・ADJ : 形容詞
・形容詞(但し非自立となるものを除く) (例: 小さい)
・形状詞 (例: 豊か)
・連体詞(但しDETを除く) (例: 大きな)
・名詞-形状詞可能で形状詞の語尾が付く場合 (例: '自由'な)
・ADV : 副詞
・副詞 (例: ゆっくり)
・INTJ : 間投詞
・間投詞 (例: あっ)
・PRON : 代名詞
・代名詞 (例: 彼)
・NUM : 数詞
・名詞-数詞 (例: 5)
・AUX : 助動詞
・助動詞 (例: た)
・動詞/形容詞のうち非自立のもの (例: して'いる', 食べ'にくい’)
・CONJ : 接続詞
・接続詞または助詞-接続助詞のうち、等位接 続詞として用いるもの (例: と)
・SCONJ : 従属接続詞
・接続詞・助詞-接続助詞(CONJとなるものを除く) (例: て)
・準体助詞 (例: 行く'の'が)
・DET : 限定詞
・連体詞の一部 (例: この, その, あんな, どんな)
・ADP : 接置詞
・助詞-格助詞 (例: が)
・副助詞 (例: しか)
・係助詞 (例: こそ)
・PART : 接辞
・助詞-終助詞 (例: 何時です'か')
・接尾辞 (例: 深'さ')
・PUNCT : 句読点
・補助記号-句点/読点/括弧開/括弧閉
・SYM : 記号
・記号・補助記号のうちPUNCT以外のもの
・X : その他
・空白品詞の抽出(名詞のみ抽出する)
品詞を指定して、特定の品詞に該当する単語のみを抽出することができます。
以下の例では、名詞である単語のみ表示するような処理を行います。
import spacy
nlp = spacy.load('ja_ginza')
doc = nlp('私は毎週水曜日にカフェで勉強します。その後、ジムに寄ってから帰ります。')
for token in doc:
if '名詞' in token.tag_:
print(token,token.tag_,token.pos_)実行すると、以下のような結果が出力されます。
私 代名詞 PRON
毎週 名詞-普通名詞-副詞可能 NOUN
水曜日 名詞-普通名詞-副詞可能 NOUN
カフェ 名詞-普通名詞-一般 NOUN
勉強 名詞-普通名詞-サ変可能 VERB
後 名詞-普通名詞-副詞可能 NOUN
ジム 名詞-普通名詞-一般 NOUNレンマの抽出
レンマ(Lemma)とは、単語の基本形のことで、辞書でいうところの見出し語に相当します。
形態素解析した単語をレンマに変換することをレンマ化といいます。
import spacy
nlp = spacy.load('ja_ginza')
doc = nlp('私は毎週水曜日にカフェで勉強します。その後、ジムに寄ってから帰ります。')
# レンマと品詞の抽出
for sent in doc.sents:
for token in sent:
print(token.text,token.lemma_) 実行すると、以下のような結果が出力されます。
私 私
は は
毎週 毎週
水曜日 水曜日
に に
カフェ カフェ
で で
勉強 勉強
し する
ます ます
。 。
その その
後 後
、 、
ジム ジム
に に
寄っ 寄る
て て
から から
帰り 帰る
ます ます
。 。係り受け解析
係り受け解析
文章を単語に分かち書きした後、文の構造を解析する処理を構文分析と言います。
構文分析の手法として、形態素解析で得られた単語間の関係性を解析する係り受け解析があります。
また、文の意味を解析する処理を意味解析と言います。
文から意味を取り出す手法に述語項構造解析があります。
係り受け解析や述語項構造解析を用いることで、以下のように文章の構造を把握することができるようになります。
tokenプロパティは以下の通りです。
| token.dep_ | 構文従属関係 |
| token.head | 構文上の親のトークン |
| token.children | 構文上の子のトークン |
| token.lefts | 構文上の左のトークン群 |
| token.rights | 文上の右のトークン群 |
import spacy
from spacy import displacy
nlp = spacy.load('ja_ginza')
doc = nlp('私は毎週水曜日にカフェで勉強します。その後、ジムに寄ってから帰ります。')
for sent in doc.sents:
for token in sent:
print(token.text+' ← '+token.head.text+', '+token.dep_)実行すると、以下のような結果が出力されます。
私 ← 勉強, nsubj
は ← 私, case
毎週 ← 水曜日, compound
水曜日 ← 勉強, obl
に ← 水曜日, case
カフェ ← 勉強, obl
で ← カフェ, case
勉強 ← 勉強, ROOT
し ← 勉強, aux
ます ← 勉強, aux
。 ← 勉強, punct
その ← 後, det
後 ← 寄っ, obl
、 ← 後, punct
ジム ← 寄っ, obl
に ← ジム, case
寄っ ← 帰り, advcl
て ← 寄っ, mark
から ← 寄っ, case
帰り ← 帰り, ROOT
ます ← 帰り, aux
。 ← 帰り, punct係り受け解析のグラフを表示する
係り受け解析の結果のグラフとして表示することができます。
displacy.render(doc, style='dep', jupyter=True, options={'compact':True, 'distance': 90})
displacy.render(doc, style='dep', jupyter=True)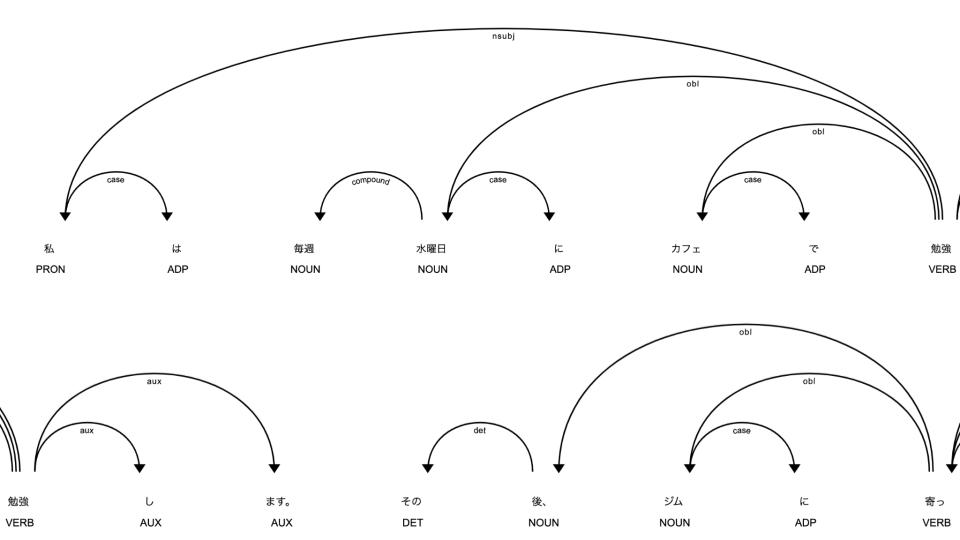
「構文従属関係」の定数は、以下のとおりです。
・acl : 名詞の節修飾子
・advcl : 副詞節修飾子
・advmod : 副詞修飾子
・amod : 形容詞修飾子
・appos : 同格
・aux : 助動詞
・case : 格表示
・cc : 等位接続詞
・ccomp : 補文
・clf : 類別詞
・compound : 複合名詞
・conj : 結合詞
・cop : 連結詞
・csubj : 主部
・dep : 不明な依存関係
・det : 限定詞
・discourse : 談話要素
・dislocated : 転置
・expl : 嘘辞
・fixed : 固定複数単語表現
・flat : 同格複数単語表現
・goeswith : 1単語分割表現
・iobj : 関節目的語
・list : リスト表現
・mark : 接続詞
・nmod : 名詞修飾子
・nsubj : 主語名詞
・nummod : 数詞修飾子
・obj : 目的語
・obl : 斜格名詞
・orphan : 独立関係
・parataxis : 並列
・punct : 句読点
・reparandum : 単語として認識されない単語表現
・root : ルート
・vocative : 発声関係
・xcomp : 補体文境界解析
「文境界解析」は、文章を文の境界を検出して、文に分解する処理です。
import spacy
nlp = spacy.load('ja_ginza')
doc = nlp('私は毎週水曜日にカフェで勉強します。その後、ジムに寄ってから帰ります。')
for sent in doc.sents:
print(sent)実行すると、以下のような結果が出力されます。
私は毎週水曜日にカフェで勉強します。
その後、ジムに寄ってから帰ります。まとめ
最後までご覧いただきありがとうございました。
今回の記事では、自然言語処理の基本事項である形態素解析の基本的な実装方法を紹介しました。
次回はGiNZAによる固有表現抽出について紹介します。
このシリーズでは、自然言語処理全般に関するより詳細な実装や学習の方法を紹介しておりますので、是非ご覧ください。
自然言語処理(NLP)まとめは「G検定完全ガイド」に統合されました
旧「自然言語処理(NLP)まとめ」ページは、サイト整理に伴い G検定完全ガイド 配下の最新キーワード解説に統合されました。NLP関連の解説(形態素解析・word2vec・Transform…