G検定の要点をシラバスから抜粋してまとめました。
これから学習する方も、復習したい方にもお使いいただけます。
試験当日用のG検定カンニングペーパーとしてもお役立てください。
(試験の際は自己責任でご使用ください。)
項目の修正・追加などのご要望はお問い合わせフォームからまたはTwitterからご連絡をお願いします。
2023年の最新版はこちらに移行しました。
【G検定2023まとめ】要点整理&当日用カンペ
こちらに移動しました 関連記事【G検定2024最新】試験当日も使える! 187項目の要点整理&試験対策カンペ【新シラバス対応】 2024年10月24日 【G検定まとめ2024】試験…

【G検定2023まとめ】理解度確認&問題集まとめ【直前対策】
こちらに移動しました 関連記事【G検定2024最新】試験当日も使える! 187項目の要点整理&試験対策カンペ【新シラバス対応】 2024年10月24日 【G検定まとめ2024】試験…

①ページ内検索をご活用ください
(mac:command+F、windows:ctrl+F)
②配色は以下のように使い分けをしています
◯メインキーワード(必ず覚える)
◯関連キーワード(余裕があれば覚える)
◯シラバスにないキーワード(参考)
③一部の項目には詳細や実装に関するリンクがあります。
〈詳細はこちら〉、〈実装はこちら〉
0. 学習のおすすめ書籍(参考)
筆者が実際に学習した書籍を紹介します。
教科書として使用する書籍
体系的に知識を整理することができます。
まずは、この1冊を読んでG検定の学習を進めましょう。
検索機能が使用できるので、Kindle版が特におすすめです。

問題集として使用する書籍
ある程度学習が進んだら、本番を意識して問題集に取り組みましょう。
本番の試験環境を意識して、このページ「要点整理&当日用カンペ」を使用しながら解答してみましょう。


1. 人工知能とは
1.1 人工知能の定義
キーワード
人工知能とは何か、人工知能のおおまかな分類、AI 効果、人工知能とロ ボットの違い、推論、認識、判断、エージェント、古典的な人工知能、機械学習、ディープラーニング
人工知能とは何か ⇨
計算機による知的な情報処理システムの設計や実現に関する研究分野であり、コンピュータを使って学習・推論・認識・判断など人間と同じ知的な処理能力を持つシステム。「知性」や「知能」自体の定義がないため、人工知能の具体的な定義は専門家の間でも未だに無い。同じシステムであっても、それを人工知能だと主張する人と人工知能ではないと考える人がいる。「人間と同じ知的な処理能力を持つ機械(情報処理システム)」という表現をすれば、「人間と同じ知的な処理能力」という部分の解釈が人によって異なる可能性がある。
AIの始まりはエニアック登場の10年後に1956年ダートマス会議で初めて提唱されたことによる。アーサー・サミュエルは機械学習を「明示的にプログラムしなくても学習する能力をコンピュータに与える研究分野」と定義している。
| レベル1 | シンプルな制御プログラム | 全ての振る舞いがあらかじめ決められている。ルールベースで動く |
| レベル2 | 古典的な人工知能 | 探索・推論、知識データを利用して状況に応じて複雑な振る舞いをする |
| レベル3 | 機械学習を入れた人工知能 | 非常に多くのサンプルデータから入出力関係を学習 |
| レベル4 | ディープラーニングを入れた人工知能 | 特徴量による学習 |
AI効果 ⇨
人工知能で何か新しいことが実現され、その原理が分かってしまうと、「それは単純な自動化であって知能とは関係ない」と結論付ける人間の心理的な効果。
人工知能とロボットの違い ⇨
ロボットの脳に当たる部分が人工知能。脳以外の部分を研究対象としているロボットの研究者は人工知能の研究者ではない。人工知能の研究は脳だけを対象としているわけではなく、考える(知的な処理有力)という目に見えないものを扱う。
エージェント
事前に定義された目標を達成するためのコードまたはメカニズム。
古典的な人工知能
掃除ロボットや診断プログラムなど入力と出力を関係づける方法が洗練されており、入力と出力の組み合わせの数が極端に多いもの。
機械学習
学習により自動で改善するコンピューターアルゴリズムもしくはその研究領域。データが持つ特徴(構造やパターン)を学習しており、パターン認識という古くからの研究をベースにしている。
ディープラーニング
ディープニューラルネットワークを用いて学習を行うアルゴリズムで機械学習に含まれる。ディープラーニングを取り入れた人工知能は、学習対象となるデータの特徴量を自動的に学習する。画像認識、音声認識、自動翻訳など、従来のコンピュータでは実現するのが難しいとされてきた分野での応用が進んでいる。ディープラーニングは従来の機械学習と異なり、特徴量そのものを学習するため、入力の良い内部表現を得ることができるようになった。
1.2 人工知能研究の歴史
キーワード
世界初の汎用コンピュータ、ダートマス会議、人工知能研究のブームと冬の時代、エニアック (ENIAC)、ロジック・セオリスト、トイ・プロブレム、エキスパートシステム、第五世代コンピュータ、ビッグデータ、機械学習、特徴量、ディープラーニング、推論・探索の時代、知識の時代、機械学習と特徴表現学習の時代、ディープブルー
世界初の汎用コンピュータ ⇨
1946年、アメリカのペンシルバニア大学で発明された世界初の汎用電子式コンピュータをエニアック(ENIAC)という。
ダートマス会議 ⇨
エニアック誕生の10年後の1956年の7月から8月にかけて開催された、人工知能という学術研究分野を確立した会議の通称である。この会議において初めてAI(Artificial Intelligence)という用語を用いたとされる。
ジョン・マッカーシーが主催しており、他の参加者はマーヴィン・ミンスキー、ジョン・マッカーシー、アレン・ニューウェル、ハーバート・サイモン、クロード・シャノン(情報理論の父と呼ばれる)。
ニューウェルとサイモンは世界初の人工知能プログラムといわれるロジック・セオリストをデモンストレーションしており、コンピュータを用いて数学の定理を自動的に証明することが実現可能であることを示す。さらに知的に行動したり思考したりするコンピュータ・プログラムの実現可能性について議論された。
| 第1次AIブーム | 推論・探索の時代:1950年代後半~1960年代 | トイ・プロブレム⇨:コンピュータによる「推論」や「探索」 の研究が進み、特定の問題に対して解を提示できるようになった。迷路や数学の定理の証明のような簡単な問題(トイ・プロブレム)は解けても現実の問題は解けないことが明らかになり、1970年代には人工知能研究は冬の時代を迎える。 |
| 第2次AIブーム | 知識の時代:1980年代 | エキスパートシステム⇨:データベースに大量の専門知識を溜め込んだ実用的なシステム。日本では政府によって「第五世代コンピュータ」と名付けられた大型プロジェクトが推進された。しかし、知識を蓄積・管理することの大変さが明らかになってくると、1995年ごろからAIは冬の時代を迎える。 第2次AIブームの主役である知識表現は、現在も重要な研究対象になっている。 |
| 第3次AIブーム | 機械学習・特徴表現学習の時代:2010年~ | ディープラーニング(深層学習)⇨:ビッグデータを用いることで人工知能が自ら知識を獲得する機械学習が実用化。特徴量を人工知能が自ら習得するディープラーニング(深層学習)が登場。 第3次AIブームの主役である機械学習(ニューラルネット)も、本質的な提案は第1次AIブームの時に既に出ていた。 |
エニアック( ENIAC )⇨
アメリカで製作された世界初の汎用コンピュータ
エレクトロニクスの高速性と複雑な問題を解くために、
プログラミング可能な能力を初めて併せ持った計算機。
ロジック・セオリスト
数学の定理を自動的に証明することが実現可能であることを示すプログラム。
「世界初の人工知能プログラム」とされている。ニューウェルとサイモンがデモンストレーションを行った。
トイ・プロブレム
トイ・プロブレム(おもちゃの問題)とは、おもちゃのように簡単な問題という意味ではなくコンピュータで扱えるように本質を損なわない程度に問題を簡略化した問題のことで、トイ・プロブレムを用いることで問題の本質を理解したり現実世界の問題に取り組んだりする練習ができるようになる。
コンピュータによる「推論」や「探索」 の研究が進み、特定の問題に対して解を提示できるようになった。迷路や数学の定理の証明のような簡単な問題は解けても、現実の問題は解けないことが明らかになり、1970年代には人工知能研究は冬の時代を迎える。
エキスパートシステム
データベースに大量の専門知識を溜め込んだ実用的なシステム。日本では、政府によって「第五世代コンピュータ」と名付けられた大型プロジェクトが推進された。しかし、知識を蓄積・管理することの大変さが明らかになってくると、1995年ごろからAIは冬の時代を迎える。
第五世代コンピュータ
人工知能コンピュータの開発を目標にした、通商産業省所管の新世代コンピュータ技術開発機構が1982年から1992年にかけて進めた国家プロジェクトの計画名称。
ビッグデータ
一般的なデータ管理・処理ソフトウエアで扱うことが困難なほど巨大で複雑なデータの集合。
特徴量
分析すべきデータや対象物の特徴・特性を、定量的に表した数値。
ディープブルー ⇨
IBMが1989年より開発したチェス専用のスーパーコンピュータ。ディープ・ソートを破った当時チェスの世界チャンピオンだった、ガルリ・カスパロフを打ち負かすことを目標とした。1997年にIBMが開発した人工知能でチェスの世界チャンピオンを破った。ディープブルーは主に全幅探索アプローチが用いられており、圧倒的な計算能力に物を言わせて勝利したといえる。
2. 人工知能をめぐる動向
2.1 探索・推論
キーワード
探索木、幅優先探索、深さ優先探索、プランニング、STRIPS、SHRDLU、アルファ碁 (AlphaGo)、ヒューリスティックな知識、MiniMax 法、αβ 法、ブルートフォース、モンテカルロ法
探索木 ⇨
計算機科学において特定のキーを特定するために使用される木構造のことで、学習結果を木構造で表現できるため解釈性が高い。場合分けを続けていけばいつか目的の条件に合致するという考え方に基づく。不純度が最も減少(情報利得が最も増加)するようにデータを振り分けることを繰り返す。不純度とはクラスの混ざり具合を表す指標でジニ係数やエントロピーがある。バギングを組み合わせた手法をランダムフォレストという。探索方法は大別すると以下の通りとなる。
| 幅優先探索 | 深さ優先探索 |
| 出発点に近いノード(探索木の各要素)順に検索する。出発点から遠いノードほど検索は後回しになる。最短距離でゴールにたどり着く解を見つけることができる。 探索の途中で立ち寄ったノードをすべて記憶しておく必要がありメモリが多く必要となる。 | あるノードから行けるところまで行って、行き止まりになったら1つ手前のノードに戻って探索を行うということを繰り返す。1つ手前のノードに戻って探索するため大きなメモリは要らない。 最短距離でゴールにたどり着く解であるとは限らない(運次第)。「縦型探索」とも呼ばれる。 |
ハノイの塔
円盤と3本のポールを用いたパズルの一種である。「1回に動かせる円盤の枚数は1枚のみ」「小さな円盤の上に大きな円盤を乗せることはできない」というルールに従って、全ての円を右端に移動させる。円盤の枚数がn枚である時、最小の手数は「(2^ n)ー 1」回であることが知られている。
プランニング ⇨
エージェントに与えられた目標を達成するために必要な行動の系列を探索により自動作成すること。あらゆる状態「前提条件」について、「行動」と「結果」を記述しておけば目標とする状態に至る行動計画を立てることができる。
STRIPS(Stanford Research Institute Problem Solver)
1970年代に提案された「前提条件」・「行動」・「結果」の3つの組み合わせで記述するプランニングの手法。
SHRDLU
1968年から1970年にかけて、テリー・ウィノグラードによって実施されたプロジェクトプランニングを実現する研究。英語による指示を受け付け、コンピュータ画面に描かれる「積み木の世界」に存在する様々な物体(ブロック、四角錐、立方体など)を動かすことができた。この成果はCycプロジェクトにも引き継がれている。
AlphaGo(アルファ碁)⇨
Google DeepMindによって開発されたコンピュータ囲碁プログラム。2016年3月9日、韓国のプロ棋士に4勝1敗。
ボードゲームをコンピュータで解く基本は探索であり、代表的なボードゲームでは探索の組み合わせの数の順番はオセロ<チェス<将棋<囲碁となる。
| オセロ | 1997年に人工知能が人間のチャンピオンに勝利 |
| チェス | 1997年に人工知能が人間のチャンピオンに勝利 |
| 将棋 | 人間のレベルを超えたのは2015年 |
| 囲碁 | 2015年時点でコンピュータの実力は人間のアマチュア6、7段程度。世界チャンピオンに勝つにはさらに10年はかかると思われていたが、2016年3月9日に人工知能の囲碁プログラムAlphaGoが人間のチャンピオンに勝ち越した。 |
ヒューリスティック(な知識)
探索のコスト(時間や費用)を考えるときに、探索を効率化するのに有効な経験的な知識や経験をいう。ボードゲームを例に取ると、コンピュータが効率よく最良の手を探索できるように状態が自分にとって有利か不利かを示すスコア(コスト)を情報として保持する。
MiniMax法
自分が番にスコアが最大になるように、相手の番にはスコアが最小になるように戦略を立てる手法。ボードゲームにおける探索木では、一手が指され他時に盤面の状態を探索木の各ノードとし、ある盤面における状態の良し悪しはスコアによって評価される。
αβ法
Mini-Max法による探索をできるだけ減らす手法。
| αカット | すでに出現したスコアよりも小さいノードが現れた時点で、その先につながるノードの探索をカットする |
| βカット | すでに出現したスコアよりも大きいノードが現れた時点で、その先につながるノードの探索をカットする |
ブルートフォース ⇨
力任せで総当たり攻撃すること。可能な組合せを全て試すやり方。人間の思考方法とは違ってブルートフォース(力任せ)で押し切る方法のため、探索しなければならない組み合わせの数が増えると、立ち行かなくなるためしばらくは囲碁でプロに勝てなかった。ディープラーニングの技術を使って人間の思考方法をコンピュータで実現し人間のプロ棋士に勝利した。
モンテカルロ法 ⇨
モンテカルロ法とはシミュレーションや数値計算を乱数を用いて行う手法の総称。囲碁や将棋などにおいては、ゲームがある局面まで進んだら、あらかじめ決められた方法でゲームの局面のスコアを評価するという方法を完全に放棄する。その代わりに、コンピュータが2人の仮想的なプレーヤーを演じて、完全にランダムに手を指し続ける方法でゲームをシミュレーションし終局させてしまうことをプレイアウトという。どの方法が一番勝率が高いか計算でき、ゲームのスコアを評価できる。
2.2 知識表現
キーワード
人工無脳、知識ベースの構築とエキスパートシステム、知識獲得のボトル ネック(エキスパートシステムの限界)、意味ネットワーク、オントロ ジー、概念間の関係 (is-a と part-of の関係)、オントロジーの構築、ワト ソン、東ロボくん、イライザ (ELIZA)、イライザ効果、マイシン (MYCIN)、DENDRAL、知識獲得のボトルネック(エキスパートシステムの限界)、インタビューシステム、意味ネットワーク、is-a の関係、has-a の関係、part-of の関係、オントロジー、Cycプロジェクト、推移律、ウェブマイニング、データマイニング、ワトソン、Question-Answering、セマンティック Web
人工無能
チャットボット、おしゃべりボットなどと呼ばれている、人間的な会話の成立を目指した人工知能に類するコンピュータプログラム。特定のルール・手順に沿って会話を機械的に処理するだけで、実際は会話の内容を理解していない。
イライザ(ELIZA) ⇨
1964年から1966年にかけてジョセフ・ワイゼンバウムによって開発されたコンピュータプログラム。(人工無能の元祖)相手の発言をあらかじめ用意されたパターンと比較し、パターンに合致した発言があった場合にはそのパターンに応じた発言を返答する。
イライザ効果 ⇨
コンピュータのことを自分とコミュニケーションがとれる人間だと錯覚してしまうこと。
マイシン( MYCIN )⇨
1970年代にスタンフォード大学で開発された、血液中のバクテリアの診断支援をするルールベースのプログラム。あたかも感染症の専門医のように振舞うことができ、初期のエキスパートシステムとして影響力を持っていた。
DENDRAL ⇨
スタンフォード大学のエドワード・ファイゲンバウムが1960年代に開発した未知の有機化合物を特定するエキスパートシステム。1977年には実世界の問題に対する技術を重視した「知識工学」を提唱し、1970年代後半から1980年代にわたり多くのエキスパートシステムが開発された。
知識獲得のボトルネック(エキスパートシステムの限界)⇨
知識のデータベースを構築するためには、専門家・ドキュメント・事例などから知識を獲得する必要がある。ドキュメントや事例から知識を獲得するためには自然言語処理や機械学習という技術を利用することで取得可能であるが、最大の知識源である人間の専門家の知識は暗黙的であるため獲得は難しい場合が多い。そこで専門家が持つ知識を上手にヒアリングするインタビューシステムなどの研究が行われた。知識を共有する方法や再利用する方法も問題になり、そうした問題を解決するために意味ネットワークやオントロジーなどの研究が活性化した。
意味ネットワーク ⇨
もともと認知心理学における長期記憶の構造モデルとして考案された。人工知能においても重要な知識表現の方法の1つ。意味ネットワークは「概念」をラベルの付いたノードで表し、概念間の関係をラベルの付いたリンクで結んだネットワークとして表現する。
| is-a(「である」の関係) | part-of(「一部である」の関係) |
|---|---|
| 上位概念と下位概念の継承関係 | 属性 |
| 哺乳類-犬 | 車-部品 |
| 「is-a」の関係は推移律が必ず成立する。 「哺乳類 is-a 動物」と「人間 is-a 哺乳類」が成立すれば、「人間 is-a 動物」が自動的に成立することを意味する | 「part-of」の関係には最低5つの関係があることが分かっており、コンピュータにこれを理解させるのは大変難しい。 |
オントロジー ⇨
本来は哲学用語で存在論(存在に関する体系的理論)という意味。人工知能の用語としては、トム・グルーパーによる「概念化の明示的な仕様」という定義が広く受入れられており、エキスパートシステムのための知識ベースの開発と保守にはコストがかかるという問題意識に端を発している。知識を記述する時に用いる「言葉(語彙)」や「その意味」、それらの関係性を共有できるように明確な約束事(仕様)として定義。オントロジーの研究が進むにつれ、知識を記述することの難しさが明らかになり、ヘビーウェイトオントロジー、ライトウェイトオントロジーという2つの流れが生まれた。
| ヘビーウェイトオントロジー | ・対象世界の知識をどのように記述するかを哲学的にしっかり考えて行う。 ・構成要素や意味的関係の正当性について哲学的な考察が必要になるため、どうしても人間が関わることになる傾向。 |
| ライトウェイトオントロジー | ・完全に正しいものでなくても使えるものであればいいという考えで、構成要素の分類関係の正当性については深い考察は行わない傾向がある。 ・セマンティックWeb(Webサイトが持つ意味をコンピュータに理解させ、コンピュータ同士で処理を行わせるための技術)や、LOD(Linked Open Data:コンピュータ処理に適したデータを公開・共有するための技術)などの研究として展開。 ・ウェブデータを解析して知識を取り出すウェブマイニングやビッグデータを解析して知識を取り出すデータマイニングと相性が良い。 |
Cycプロジェクト ⇨
すべての一般常識をデータベース化し(知識ベース)、人間と同等の推論システムを構築することを目的とするプロジェクト(ダグラス・レナート)。1984年から今も続いている。
東ロボくん
東大入試合格を目指す人工知能の研究・開発プロジェクトのことで、2016年にはほとんどの私立大学に合格できるレベルになった。国立情報学研究所が2011年から研究がスタートしたが、質問の意味を理解していないので読解力に問題があり、現在の技術では合格は難しいことから2016年に凍結された。
ワトソン君 ⇨
IBMが開発した質問応答システム・意思決定支援システムで、2011年、「ジョパディー」の歴代の人間チャンピオンに勝利した。Question-Answering(質問応答)という研究分野の成果であり、ウィキペディアの情報をもとにライトウェイト・オントロジーを生成して解答する。質問の意味を理解して解答しているわけではなく、質問に含まれるキーワードと関連しそうな答えを高速に検索し、解答候補が質問との整合性や条件をどの程度満たしているかを複数の視点でチェックし総合点を算出して、一番高い総合点が得られた候補を解答として選択していた。
IBMは開発当初、ワトソンを医療診断に応用するとしていたが、コールセンター、人材マッチング、広告、「シェフ・ワトソン」という新しい料理を考えることへの応用など幅広い分野で活用されている。
推移律
集合の二つの要素間の関係に関する条件の一つ。集合の二要素 x、y の間に関係 R があることを xRy と書くことにしたとき、「xRy かつ yRz なる限りつねに xRz」が成立するならば、関係 R は推移律をみたすという。「is-a」の関係は推移律が成立する。
ウェブマイニング
ウェブサイトの構造やウェブ上のデータを解析して知識を取り出す。
データマイニング
統計学、パターン認識、人工知能等のデータ解析の技法を大量のデータに網羅的に適用することで、有用な知識を取り出す技術。
Question-Answering
質問応答システムのこと。自然言語の質問をユーザから自然言語で受けつけ、その解答を返すようなコンピュータソフトウェアをいう。IBMが開発したワトソン君。
セマンティックWeb
Webページに記述された内容について、「情報についての情報」(いわゆるメタデータ)を一定の規則に従って付加し、コンピュータシステムによる自律的な情報の収集や加工を可能にする。情報リソースに意味を付与することでコンピュータにより高度な意味処理を実現することを目指す。
2.3 機械学習・深層学習
キーワード
データの増加と機械学習、ビッグデータ、レコメンデーションエンジン、スパムフィルター、機械学習と統計的自然言語処理統計的、自然言語処理、コーパス、人間の神経回路、単純パーセプトロン、誤差逆伝播法、オートエンコーダ、ILSVRC、特徴量、次元の呪い、機械学習の
定義、パターン認識、画像認識、特徴抽出、一般物体認識、OCR
データの増加と機械学習
機械学習とは人工知能のプログラム自身が学習する仕組みのことをいう。コンピュータは与えられたサンプルデータを通してデータに潜むパターンを学習する。この際、サンプルデータが多ければ多いほど望ましい学習結果が得られる。2000年以降、ビッグデータ(インターネットの成長とともに蓄積された大容量データ)とともに注目を集めるようになった。
ユーザーの好みを推測するレコメンデーションエンジンや迷惑メールを検出するスパムフィルターなども、膨大なサンプルデータを利用できるようになった機械学習によって実用化されたアプリケーション。
機械学習と統計的自然言語処理
従来は文法構造や意味構造を分析して単語単位で訳を割り当ていた。現在の統計的自然言語処理では複数の単語をひとまとまりにした単位(句または文単位)で用意された膨大な量の対訳データをもとに、最も正解である確率が高いものを選択。
コーパス
対訳データのこと。自然言語処理の研究に用いるため、自然言語の文章を構造化し大規模に集積したもの。
ニューラルネットワーク⇨
機械学習の一つで、人間の神経回路を模倣することで学習を実するもの。1943年にウォーレン・マカロックとウォルター・ピッツによって人間の神経細胞を数理モデル化した形式ニューロンが発表され、これを元に1958年に米国の心理学者フランク・ローゼンブラットが単純パーセプトロンというニューラルネットワークを発表。1960年代に爆発的なブームを起こすが人工知能学者のマービン・ミンスキーにより単純パーセプトロンの限界が示され、ニューラルネットワークの研究は下火になってしまうが、ニューラルネットワークを多層にし誤差逆伝播法を使うことで克服された。
日本では1980年に福島邦彦らによってネオコグニトロンというニューラルネットワークが考案されており、これは畳み込みニューラルネットワークの起源となった。視野角の神経細胞の働きを模しており、画像の濃淡パターンを抽出するS細胞の層と特徴の位置ずれの影響を除去するC細胞の層とで構成される。add-id silent という学習手法がとられており、誤差逆伝播方は用いられていない。
誤差逆伝播法(バックプロパゲーション)
1986年にデビッド・ラメルハートらによって命名された、ニューラルネットワークを学習させる際に用いられるアルゴリズム。予測値と実際の誤差をネットワークにフィードバックする。
自己符号化器(オートエンコーダ)
入力と出力が同じになるようなネットワーク。
入力したデータの次元数をいったん下げ(圧縮)、再び戻して出力する。
ILSVRC ⇨
ImageNet Large Scale Visual Recognition Challengeの略であり、2010年より始まった画像認識の精度を競い合う競技会。2012年、ジェフリーヒントン率いるトロント大学のチーム(SuperVision)がAlexNet(パラメータ数:60,000,000)がディープラーニングを用いて優勝。これを受けて、第3次ブームに発展した。
2012年以前のILSVRCで、画像認識に機械学習を用いることは既に常識になっていたが、機械学習で用いる特徴量を決めるのは人間だった。2012年以降のILSVRCのチャンピオンは全てディープラーニングを利用しており、2015年に人間の画像認識エラーである4%を下回った。
次元の呪い ⇨
数学者リチャード・ベルマンによって提唱された概念。データの次元数が大きくなり過ぎると、そのデータで表現できる組み合わせが飛躍的に多くなってしまい、サンプルデータでは十分な学習結果が得られなくなることを「次元の呪い」という。副次的な次元を増やすことにより識別力を向上させることが可能な場合が存在し、そのことを「次元の祝福」と呼ぶ。
パターン認識
画像や音声など膨大なデータから一定の特徴や規則性のパターンを識別して取り出す処理のこと
特徴抽出
データからその特徴量を取り出す処理のこと。ディープラーニングではこの処理が自動で行われるが、登場以前は人間の手によって行われていた。画像の関心部分をコンパクトな特徴ベクトルとして効率的に表現する一種の次元削減とも言える。
OCR(Optical Character Recognition/Reader) ⇨
手書きや印刷された文字を、スキャナによって読みとり、コンピュータが利用できるデジタルの文字コードに変換する技術
3. 人工知能分野の問題
3.1 人工知能分野の問題
キーワード
トイ・プロブレム、フレーム問題、チューリングテスト、強い AI と弱いAI、シンボルグラウンディング問題、身体性、知識獲得のボトルネック、特徴量設計、シンギュラリティ、ローブナーコンテスト、中国語の部屋、機械翻訳、ルールベース機械翻訳、統計学的機械翻訳、特徴表現学習
トイ・プロブレム
トイ・プロブレム(おもちゃの問題)とは、おもちゃのように簡単な問題という意味ではなくコンピュータで扱えるように本質を損なわない程度に問題を簡略化した問題のことで、トイ・プロブレムを用いることで問題の本質を理解したり現実世界の問題に取り組んだりする練習ができるようになる。
コンピュータによる「推論」や「探索」 の研究が進み、特定の問題に対して解を提示できるようになった。迷路や数学の定理の証明のような簡単な問題は解けても、現実の問題は解けないことが明らかになり、1970年代には人工知能研究は冬の時代を迎える。
フレーム問題
1969年にジョン・マッカーシーとパトリック・ヘイズが提唱。哲学者のダニエル・デネットは、洞窟から爆弾を運び出すことを命じられロボットが洞窟から爆弾を運び出すことを命じられたロボットが考えすぎてフリーズしてしまう例を挙げた。有限の情報処理能力しかないため、今しようとしていることに関係のある情報だけを選択することが難しく、現実に起こりうる問題全てに対処することができないことを示すもの。ディープラーニングが登場した現在もまだ本質的な解決はされておらず、人工知能研究の中でも難問である。
フレーム問題を打ち破ったAIを汎用AI、フレーム問題を打ち破っていないAIを特化型AIと呼ぶことがある。
チューリングテスト(人工知能ができたかどうかを判定する方法)⇨
イギリスの数学者アラン・チューリングが提唱した、別の場所にいる人間がコンピュータと会話をした場合に相手がコンピュータだと見抜けなければコンピュータには知能があるとするもの。1950年の論文の中でアラン・チューリングは50年以内に質問者が5問質問した後の判定でコンピュータを人間と誤認する確率は30%であると見積もった。
1966年にジョセフ・ワインバムによって開発されたイライザ(ELIZA)では、精神科セラピストの役割を演じるプログラムで、本物のセラピストと信じてしまう人も現れるほどの性能であった。
1972年にケネス。コルビーが発表したパーリー(PARRY)も多くの判定者が誤解をする性能だった。イライザ(ELIZA)とパーリー(PARRY)は何度か会話を行ったことがあり、RFC439として最初の記録がある。
1991年以降、チューリングテストに合格する会話ソフトウェアを目指すローブナーコンテストを毎年開催されているが、現在もまだチューリングテストにパスする会話ソフトウェアは現れていない。
強いAIと弱いAI ⇨
アメリカの哲学者ジョン・サールが1980年に発表したAIの区分のこと。
| 強いAI | ・適切にプログラムされたコンピュータは人間が心を持つのと同じ意味で心を持つ。 ・人間の知能に近い機能を人工的に実現するAI |
| 弱いAI | ・コンピュータは人間の心を持つ必要はなく、有用な道具であればよい。 ・人間の知能の一部に特化した機能を実現するAI |
ジョン・サールは、人の思考を表面的に模倣するような「弱いAI」は実現可能でも、意識を持ち意味を理解するような「強いAI」は実現不可能だと主張している。
英語しかわからない人を中国語の質問に答えることができる完璧なマニュアルがある部屋に閉じ込めて、その人がマニュアル通りに受け答えをすれば、実際には中国語を理解していないにも関わらず部屋の中の人が中国語を理解していると誤解してしまう「中国語の部屋」という思考実験を実施。これが本当に知能があるといえるのかという議論がある。
ブラックホールの研究で有名なスティーブン・ホーキングと共同研究をしたことで有名な数学者のロジャー・ペンローズは、意識は脳の中にある微細な管に生じる量子効果が絡んむため、既存のコンピュータでは「強いAI」は実現できないと主張。
シンボルグラウンディング問題 ⇨
1990年に認知科学者のスティーブン・ハルナッドにより議論された。記号(シンボル)とその対象がいかにして結び付くかという問題。人間のであれば「シマ(Stripe)」の意味も「ウマ(Horse)」の意味もよく分かっているので、本物のシマウマ(Zebra)を初めて見たとしても、「あれが話に聞いていたシマウマかもしれない」とすぐに認識することができる。しかし、コンピュータは「記号(文字)」の意味が分かっていないので、「シマ(Stripe)」と「ウマ(Horse)」から「シマウマ」と結び付けることができない。シンボルグラウンディング問題はまだ解決されておらず、人工知能の難問とされている。
身体性
知能が成立するためには身体が不可欠であるという考え。視覚や触覚などの外界と相互作用できる身体がないと、概念はとらえきれないというのが身体性というアプローチの考え。人間は身体を通して概念を獲得しているため、シンボルグラウンディング問題が起きない。
知識獲得のボトルネック
機械翻訳は1970年代後半まではルールベース機械翻訳、1990年代以降では統計的機械翻訳が主流となっていた。人間は膨大な一般常識を持っているのに対して、コンピュータが「意味」を理解していないため従来の統計的機械翻訳はうまくいかない。人間が持つ膨大な知識を獲得することの難しさを知識獲得のボトルネックという。
2016年11月にGoogleが発表したGoogle翻訳ではニューラル機械翻訳が利用されており、機械翻訳の品質が格段に向上した。ディープラーニングの利用で知識獲得のボトルネックを乗り越え、さらなる性能の向上が期待されている。ディープラーニングを使ったニューラル機械翻訳は、人間が言葉を理解するのと同じような構造で訳文を出力すると言われ、TOEIC900点以上の人間と同等の訳文も生成可能だと期待されている。
ナレッジエンジニア
エキスパートシステムの実現には「知識獲得のボルトネック」を解決する必要があるため、それを専門にするナレッジエンジニアと呼ばれる職業が生まれた。エキスパートシステムの開発には人工知能の技術についての理解が必要なので、一般のシステムエンジニアとナレッジエンジニアは区別される。
特徴量設計
機械学習において、注目すべきデータの特徴の選び方が性能を決定づけるため、注目すべきデータの特徴を量的に表したものを特徴量という。特徴量を人間が見つけ出すのは非常に難しいため、この特徴量を機械学習自身に発見させるアプローチを特徴表現学習と呼ぶ。ディープラーニングは与えられたデータの特徴量を階層化しそれらを組み合わせることで問題を解く。ディープラーニングは「判断理由を説明できないブラックボックス型の人工知能」と言われる。
シンギュラリティー ⇨
AIが人類の知能を超える転換点(技術的特異点)とのことであり、それにより人間の生活に大きな変化が起こるという概念。シンギュラリティーが起きると人工知能は自分自身よりも賢い人工知能を作れるようになり、その結果それ自身が無限に知能の高い存在を作り出せるようになるため、知的なシステムの技術開発速度が無限大になるので何が起きるか予想できないとされている。こうした脅威に対し、Googleは、イギリスのディープマインド・テクノロジーズ社を買収する際に、社内に人工知能に関する倫理委員会を作った。日本でも人工知能学会において、2014年に倫理委員会が設置された。なお、シンギュラリティに対する見解は人によって異なっている。
| レイ・カーツワイル | 「$1,000で手に入るコンピュータの性能が全人類の脳の計算性能を上回る時点」「2029年には人工知能が人間よりも賢くなり、シンギュラリティは2045年に到来する」 |
| ヒューゴ・デ・ガリス | 「シンギュラリティは21世紀後半に到来する」 |
| イーロン・マスク | シンギュラリティに危機感を持ち、非営利組織OpenAIを設立 |
| オレン・エツィオーニ | 「シンギュラリティは100万年後に特異点を迎える可能性はある。 しかし、世界制覇すると言う構想は馬鹿げている。」 |
| ヴィーナー・ヴィンジ | 「機械が人間の役に立つふりをしなくなる」 |
| スティーブン・ホーキング | 「AIの完成は人類の終焉を意味するかもしれない」 |
4. 機械学習の具体的手法
4.1 教師あり学習
キーワード
線形回帰、ロジスティック回帰、ランダムフォレスト、ブースティング、サポートベクターマシン (SVM)、ニューラルネットワーク、自己回帰モデル (AR)、分類問題、回帰問題、半教師あり学習、ラッソ回帰、リッジ回帰、決定木、アンサンブル学習、バギング、勾配ブースティング、ブートストラップサンプリング、マージン最大化、カーネル、カーネルトリック、単純パーセプトロン、多層パーセプトロン、活性化関数 、シグモイド関数、ソフトマックス関数、誤差逆伝播法、ベクトル自己回帰モデル (VARモデル)、隠れ層、疑似相関、重回帰分析、AdaBoost、多クラス分類、プルーニング
分類問題、回帰問題 ⇨
教師あり学習の問題は出力値の種類によって、大きく2種類(回帰と分類問題)に分けられる。分類問題は出力が離散値であり、カテゴリを予測したいときに利用される。回帰問題は出力が連続値であり、その連続値そのものを予測したいときに利用される。
線形回帰(LinearRegression) ⇨
回帰問題に用いる手法でシンプルなモデルの1つデータ(の分布)があったときに、そのデータに最も当てはまる直線を考える。線形回帰に正則化項を加えた手法として以下の方法がある。
| ラッソ回帰 | リッジ回帰 |
|---|---|
| マンハッタン距離を用いる | ユークリッド距離を用いる |
| L1正則化 | L2正則化 |
| 一部パラメータの値を0とすることで特徴選択が可能 | パラメータの大きさに応じて0に近づけることで、汎化されたモデルを取得する |
両方を組み合わせた手法を Elastic Net という。
ロジスティック回帰 ⇨
線形回帰を分類問題に応用したアルゴリズム。対数オッズを重回帰分析により予測して、ロジスティック(シグモイド)関数で変換することで出力の正規化によって予測値を求めることで、最大確率を実現するクラスをデータが属するクラスと判定する。目的関数は尤度関数を用いる。ロジット変換を行うことで、出力値が正規化される。3種類以上の分類は、ソフトマックス関数を使う。
決定木
分類木と回帰木を組み合わせたものでツリー(樹形図)によって条件分岐を繰り返すことで境界線を形成してデータを分析する手法。決定木は一般に仕組みがわかりやすいだけでなく、データのスケールを事前に揃えておく必要がなく、分析結果の説明が容易である特徴がある。
訓練データを用いて決定木を過学習させたあと、検証データを用いて性能低下に寄与している分岐を切り取ることを剪定という。これにより過学習を抑制できる。
条件分岐を繰り返す際に条件分岐の良さを判断するための基準をあらかじめ定めておく。分類問題においては情報利得の最大化を判断基準とする。
ランダムフォレスト
「決定木」において特徴量をランダムに選びだす手法。ランダムフォレストでは特徴量をランダムに選び出す(ランダムに複数の決定木を作る)。学習に用いるデータも全データを使うのではなく、それぞれの決定木に対してランダムに一部のデータを取り出して学習を行う(ブートストラップサンプリング)。複数の決定木の結果から、多数決で出力を決定することで全体的に精度向上することを期待している。なお、複数のモデルで 学習することをアンサンブル学習、全体から一部のデータを用いてアンサンブル学習する方法をバギングという。ランダムフォレストはバギングの中で決定木を用いている手法である。過学習しやすいという弱点がある程度解消される。
ブースティング
バギングと同様に一部データを繰り返し抽出して、複数モデルを学習させる。
| バギング | ブースティング |
|---|---|
| 複数のモデルを並列して一度に作成 | モデルを逐次的に作成 |
| それぞれの結果の多数決を取る | 前のモデルでの不正解に対して重みを付けて学習 |
| 精度:低、学習時間:短 | 精度:高 、学習時間:長 |
AdaBoost、XGBoost、勾配ブースティングなどがある。
サポートベクターマシン(SVM) ⇨
SVM(Support Vector Machine)とも呼ばれる。異なるクラスの各データ点(サポートベクトル)との距離(マージン)が最大となるような境界線を求めることで、パターン分類を行う。この距離を最大化することをマージン最大化と言う。スラック変数を用いることで、どの程度誤分類を許容するか調整できるようになり、誤分類されたデータに寛容になる。
SVMではデータをあえて高次元に写像することで、その写像後の空間で線形分類できるようにするカーネル法というアプローチがとられた。この写像に用いられる関数のことをカーネル関数と言う。計算量が非常に大きくなるため、カーネルトリックと言う手法を用いて計算量を抑えることができる。
ニューラルネットワーク
ニューラルネットワークとは人間の脳の中の構造を模したアルゴリズムのこという。入力を受け取る部分を入力層、出力する部分を出力層と表現する。入力層における各ニューロンと、出力層におけるニューロンの間のつながりは重みで表され、どれだけの値を伝えるかを調整する。そして、出力が0か1の値をとるようにすることで、正例と負例の分類を可能にする。ニューラルネットワークのモデルには、複数の特徴量(入力)を受け取り、1つの値を出力する単純パーセプトロン、入力層と出力層の間に隠れ層を追加することで非線形分類も行うことを可能とする多層パーセプトロンがある。
層が増えることによって調整すべき重みの数も増えるが、予測値と実際の値との誤差をネットワークにフィードバックするアルゴリズムである誤差逆伝播法(backpropagation)がある。
多層パーセプトロン
順伝播型ニューラルネットワークの一分類である。入力ノードを除けば、個々のノードは非線形活性化関数を使用するニューロンである。多層パーセプトロンにおけるハイパーパラメータは学習率である。
活性化関数
入力に対して出力を調整するための関数であり、予測の精度に影響がある。単純パーセプトロンでは活性化関数としてステップ関数を用いた場合に相当する。
初期は出力を正規化するためシグモイド関数がよく利用されていたが、勾配消失が起きにくいReLU関数が用いられている。出力層付近ではソフトマックス関数も使用される。
| シグモイド関数 | 任意の値を0から1に写像し、正例(+1)と負例(0)に分類するための関数。閾値を設定し、閾値を境に正例or負例に分類することができる。 |
| ソフトマックス関数 | 3種類以上の分類を行いたい場合に、シグモイド関数に代わって扱う活性化関数。各ユニットの総和を1に 正規化することができる。主に分類問題の出力層で使われる。 |
自己回帰モデル(ARモデル)
一般に回帰問題に適用されるが、対象は時系列データである。時系列データ分析のことを単純に時系列分析(time series analysis)とも呼ぶ。入力が複数種類の場合、自己回帰モデルをベクトル自己回帰モデル(vector autoregressive mode、VARモデル)と呼ぶ。
単回帰分析と重回帰分析
線形回帰には1つの説明変数の1次関数で目的変数を予測する単回帰分析と、複数の説明変数の1次関数で目的変数を予測する重回帰分析がある。
相関係数 ⇨
互いの特徴量の相関の正負と強さを表す指標のこと。1に近いほど強い正の相関、−1に近いほど負の相関を持つ。
多重共線性
相関係数が大きい場合に特徴量の組みを同時に説明変数に選ぶと予測がうまくいかなくなる現象のこと。相関係数をよく観察して特徴量を選択する。
4.2 教師なし学習
キーワード
k-means 法、ウォード法、主成分分析 (PCA)、協調フィルタリング、トピックモデル、クラスタリング、クラスタ分析、レコメンデーション、デンドログラム(樹形図)、 特異値分解 (SVD) 、多次元尺度構成法、t-SNE、コールドスタート問題、コンテンツベースフィルタリング、潜在的ディリクレ配分法(LDA)、次元削減、次元圧縮
k-means法(階層なしクラスタリング)
クラスタの平均を用いて、与えられたクラスタ数をk個に分類する。k個のkは自分で設定する。k-means法を用いた分析のことをクラスタ分析という。
ウォード法(階層ありクラスタリング)⇨
k-means法からさらに、クラスタの階層構造を求めるまで行う手法。最も距離が近い2つのデータ(クラスタ)を選び、それらを1つのクラスタにまとめる処理を繰り返していく。クラスタリングのまとまりを表した樹形図のことをデンドログラム(dendrogram)という。
主成分分析(Principal ComponentAnalysis、PCA)
データの特徴量間の関係性、相関を分析しデータの構造をつかむ手法。特に特徴量の数が多い場合に用いられ、相関をもつ多数の特徴量から相関のない少数の特徴量へと次元削減することが主たる目的。ここで得られる少数の特徴量を主成分という。 線形な次元削減であり、計算量の削減ができ次元の呪いの回避が可能となる。寄与率を調べれば各成分の重要度が把握でき、主成分を調べれば各成分の意味を推測しデータの可視化が可能となる。
主成分分析以外には、特異値分解(Singular Value Decomposition、SVD)、多次元尺度構成法(Multi-Dimensional Scaling、MDS)がよく用いられる。可視化によく用いられる次元圧縮の手法は、t-SNE(t-distributed Stochastic NeighborEmbedding)がある。t-SNEのtはt分布のtである。
協調フィルタリング(collaborative filtering)
レコメンデーション(recommendation)に用いられる手法のひとつであり、レコメンドシステム(推薦システム)に用いられる。ECサイトで表示される「この商品を買った人はこんな商品も買っています」の裏側には協調フィルタリングが用いられている。協調フィルタリングは事前にある程度の参考となるデータがないと推薦を行うことができない(コールドスタート問題(cold startproblem))。
ユーザーではなく商品側に何かしらの特徴量を付与し、特徴が似ている商品を推薦する方法をコンテンツベースフィルタリング(content-based filtering)という。対象ユーザーのデータさえあれば推薦を行うことができるのでコールドスタート問題を回避することができるが、反対に他のユーザー情報を参照することができない。
トピックモデル
k-means法やウォード法と同様クラスタリングを行うモデル。文章を潜在的な「トピック(単語の出現頻度分布)」から確率的に現れるのものと仮定して分析を行う。各トピックの確率分布を推定できれば、傾向や単語の頻度、次にくる文章の予測が可能となる。各文書データ間の類似度を求めることができるため、レコメンドシステム(推薦システム)に用いることができる。データをひとつのクラスタに分類するk-means法などと異なり、トピックモデルは複数のクラスタにデータを分類するのが特徴。トピックモデルの代表的な手法に潜在的ディリクレ配分法(latent Dirichlet allocation、LDA)がある。
LDA(Latent Dirichlet Allocation)
文中の単語から、トピックを推定する教師なし機械学習の手法。ディレクトリ分布という確率分布を用いて、各単語から隠れたあるトピックから生成されているものとしてそのトピックを推定する。
LSI(Latent Semantic Indexing)
潜在的意味解析と呼ばれるトピックモデルの1種。文章ベクトルにおいて複数の文章に共通に現れる単語を解析することによって、低次元の次元の潜在意味空間を構成する方法。ある行列を複数の行列の積で表現する行列分解の一つである特異値分解が用いられれる。文章中の情報を圧縮することができ、これによりトピックを推定することができる。
k近傍法(knn法(k nearest neighbor))
クラス分類の手法でありデータから近い順にk個のデータを見て、それらの多数決によってクラス分類を行う手法。クラスのサンプル数に偏りに弱いという欠点がある。各クラスのデータ数の偏りが少なく、各クラスがはっきりと分かれている場合には有効である。アルゴリズムは単純であるが、訓練データが多いと計算に時間がかかる。
ユークリッド距離(Euclidean distance)
人が定規で測るような二点間の「通常の」距離のことであり、ピタゴラスの公式によって与えられる。ユークリッド距離に対して、各次元ごとに標準偏差で割り、値の分散を標準化した上でのユークリッド距離を標準ユークリッド距離と呼ぶ。
マハラノビス距離
標本点と分布の間の尺度。ベクトルyから平均μ及び共分散Σを持つ分布の場合、標準偏差単位でyが平均からどの程度離れているかを表す。
4.3 強化学習
キーワード
バンディットアルゴリズム、マルコフ決定過程モデル、価値関数、方策勾配、
割引率、ε-greedy 方策、UCB 方策、マルコフ性、状態価値関数、行動価値関数、Q値、Q学習、REINFORCE、方策勾配法、Actor-Critic、A3C
強化学習とは
強化学習とはエージェントが環境の中で自身が得る収益を最大化するために行動を選び、その行動が状態を変化させ、最終的にはエージェント自身が得る収益を最大化するような方策を獲得することを目指す学習手法である。
バンディットアルゴリズム(bandit algorithm)
強化学習では将来の累積報酬が最大となるような行動を取る必要があるが、行動の組み合わせは無限にある。そこで「活用」と「探索」という考え方を用いる。
| 活用 | 現在知っている情報の中から報酬が最大となるような行動を選ぶ |
| 探索 | 現在知っている情報以外の情報を獲得するために行動を選ぶ |
強化学習においてはどちらも重要な要素であり、この活用と探索のバランスを取る手法の総称をバンディットアルゴリズムという。具体的な手法は以下の通り。
| ε-greedy方策 (epsilon-greedy policy) | 基本的には「活用」(=報酬が最大となる行動を選択)するが、一定確率εで「探索」(=ランダムな行動を選択)する |
| UCB方策 (upper-confidence bound policy) | 報酬和の期待値が高い行動を選ぶという基本方針を持ちつつ、試行回数が少ない行動を優先的に選択する。探索と活用のバランスをとりながらアームの選択を行い、報酬の最大化を目指す |
方策とは、ある状態からとりうる行動の選択肢、およびその選択肢をどう決定するかの戦略で確率で表現する。
マルコフ決定過程モデル(Markov decision process)
マルコフ性とは確率論における確率過程が持つ特性の一種であり、環境に対して暗黙的にある仮定を置くことで、「現在の状態から将来の状態に遷移する確率は、現在の状態にのみ依存し、それより過去のいかなる状態にも一切依存しない」という性質。強化学習において、状態遷移にマルコフ性を仮定したモデルをマルコフ決定過程モデルいう。
価値関数
強化学習の目的は、現在の状態から将来の累積報酬が最大となるような行動を選択していくことだが、実際に最適な方策を見つけ出すのは難しいため、最適な方策を直接求める代わりに状態や行動の「価値」を設定し、その価値が最大となるように学習をするアプローチの検討がされた。この「価値」を表す関数として状態価値関数(state-value function)、行動価値関数(state-value function)を導入する。
| 状態価値関数 | 直近の報酬に次の状態の価値関数を足したもの。方策および遷移確率で未来のとりうる値は変わってくるので、その期待値をとる。 |
| 行動価値関数 | 状態sでの行動aを評価する関数。状態sに対して、どの行動が最適なものかを導く手法。 |
一般に「価値関数」と言った場合行動価値関数を指す。価値関数のことをQ値(Q-value)とも呼び、これを最適化することで最適な行動ができるようなるといえる。Q値を最適化する手法にはQ学習(Q-learning)、SARSAなどがある。
Q学習
エージェントが行動するたびにQ値を更新する学習法。2013年にDeep Mind社はディープラーニングを組み合わせたDQNを発表した。その後、Double DQN、Dueling Network、Categorical DQN、Rainbowなどが提案された。
割引率
強化学習の行動を選択する段階において、将来もらえると期待できる報酬の総和を見積もるため、即時報酬に乗算する値。この見積もりは即時報酬から割り引かれて計算され、割引くための係数を割引率という。0から1の間の値をとる。
方策勾配(policy gradient method)
方策をあるパラメータで表される関数とし、累積報酬の期待値が最大となるようにそのパラメータを学習することで、直接方策を学習していくアプローチを方策勾配法という。方策反復法の1つの手法であ李、方策勾配定理に基づき実装される。ロボット制御など、特に行動の選択肢が大量にあるような課題で用いられる。
| REINFORCE | 自ら生成したサンプルを擬似的な教師データとして、評価が高いサンプルに高い重みをつけて学習する方法。AlphaGo に活用。 |
| Actor-Critic | 価値関数ベースおよび方策勾配ベースの考え方を組み合わせで、行動を決める行動器と価値評価を行う評価器を用意して両者を交互に更新しながら学習を進める方法。行動を決めるActor(行動器)と方策を評価するCritic(評価器)から成っているのが由来。A2CやDDPGなどがある。 |
| A3C(Asynchronous Advantage Actor-Critic) | AsynchronousかつAdvantageを使って学習させるActor-Criticの応用手法。CPUで計算可能でありDQNより性能がよい。 |
4.4 モデルの評価
キーワード
正解率・適合率・再現率・F 値、ROC 曲線と AUC、モデルの解釈、モデルの選択と情報量、交差検証、ホールドアウト検証、k- 分割交差検証、混同行列、過学習、未学習、正則化、L0 正則化、L1 正則化、L2 正則化、ラッソ回帰、リッジ回帰、LIME、SHAP、オッカムの剃刀、赤池情報量基準 (AIC)、汎化性能、平均二乗誤差、偽陽性-偽陰性、第一種の過誤-第二種の過誤、訓練誤差、汎化誤差、学習率、誤差関数
正解率・適合率・再現率・F値
「犬」、「猫」の画像分類問題の例では以下のようになる。
| 実際の値\予測値 | 犬 | 猫 |
| 犬 | 真陽性(TP:True Positive) | 偽陰性(FN:False Negative) |
| 猫 | 偽陽性(FP:False Positive) | 真陰性(TN:True Negative) |
| 正解率 (accuracy) | (TP+TN)/(TP+TN+FP+FN) | 全データ中、どれだけ予測が当たったかの割合 |
| 適合率(precision) | TP/(TP+FP) | 予測が正の中で、実際に正であったものの割合 |
| 再現率 (recall) | TP/(TP+FN) | 実際に正であるものの中で、正だと予測できた割合。 |
| F値 (F measure) | 2 × Precision × Recall / Precision + Recall | 適合率と再現率の調和平均。適合率のみあるいは再現率のみで判断すると、予測が偏っているときも値が高くなってしまうので、F値を用いることも多い。 |
ホールドアウト検証
教師データの一部を「テストデータ」として分離して、残りを「訓練データ」として学習をすること。
k- 分割交差検証
データをいくつかに分割して、テストデータに用いるブロックを順に移動しながらホールドアウト法による検証を行う方法。クロスバリデーションともいう。教師データ数が少ない場合に用いる。
過学習(overfitting)
学習時において訓練誤差が小さいにも関わらず汎化誤差が小さくならない状態で、訓練データにのみ最適化されすぎてしまっている状態。
正則化
学習の際に用いる式に項を追加することによって、パラメータのノルムが大きくなりすぎないようにする(とりうる重みの値の範囲を制限する)ことをいう。これにより重みが過度に訓練データに対してのみ調整されることを防ぐ。(過学習の緩和)
| L0正則化 | 0ではないパラメータの数で正則化する。組み合わせは最適化問題になるので、計算コストが高い。 |
| L1正則化 | 一部のパラメータの値を0にすることで、特徴選択を行うことができる。 |
| L2正則化 | パラメータの大きさに応じて0に近づけることで、汎化された滑らかなモデルを得ることができる。 重みの大きさに制約を加える手法を荷重減衰という。 |
線形回帰に対してL1正則化を適用した手法をラッソ回帰、L2正則化を適用した手法をリッジ回帰、両者を組み合わせた手法をElastic Netという。
未学習(underfitting)
正則化しすぎることで全体の汎化性能(予測性能)が低下してしまうこと。
ROC曲線
視覚的にモデル性能を捉えることができる指標。横軸にFPR(=FP/(TP+FN))、縦軸にTPR(=TP/(TP+FN))を取り、閾値を0から1に変化させていった際の値をプロットして得られる曲線。2クラス分類で閾値を0から1に変化させていった場合に、予測の当たり外れがどのように変化していくのかを表す。
AUC
ROC曲線より下部(右部)で囲まれる面積のこと。AUC(0~1)が1に近いほどモデル性能が高いことを表す。
モデルの解釈
機械学習による予測はモデルの精度だけでなくどのように予測しているかも考慮する必要がある。予測の説明性を持たせる手法は以下の通り。
| LIME | 予測結果に対してのみ局所的に近似させた単純な分類器を作って、その単純な分類器から予測に効いた特徴量を選ぶ。 2016年にデータ分析の国際会議で提案された。 Local interpretable model agnostic explanations |
| SHAP | 予測した値に対して、「それぞれの特徴変数がその予想にどのような影響を与えたか」を算出するもの。 2017年にニューラルネットワークの国際会議で発表された。 Shapley Additive explanations |
モデルの選択と情報量
機械学習のモデル設計においては、一概に複雑にすればよいというわけではない。
オッカムの剃刀(Occam's razor / Ockham's razor)
「ある事柄を説明するためには、必要以上に多くを仮定するべきでない」という指針。
赤池情報量規準(Akaike's Information Criterion, AIC)
モデル設計の際にどれくらい複雑にすれば良いかを表す指標(モデルの評価方法)であり、モデルの複雑さと予測精度のバランスを考えたもの。AIC = 2logL+2k(L:モデルの尤度、k:パラメータ数)
p値
統計的有意性を判断する際に用いられる有意確率をp値という。「帰無仮説が正しいという前提において、それ以上偏った検定統計量が得られる確率」を示している。帰無仮説が「母集団Aと母集団Bの平均は等しい」とすると、p値は「2つの母集団AとBからサンプリング可能なすべての組み合わせの総数を1として、その中で今回の平均値の差以上に平均値の差が生じるサンプルの組み合わせが占める比率」ということになる。帰無仮説が正しいのに対立仮説を受け入れてしてしまう誤りを「第1種の過誤(Type I error)」、対立仮説が正しいときに帰無仮説を受け入れる誤りを「第2種の過誤(Type Ⅱ error)」と呼び、統計的検定を行うときには前もって棄却するときの基準(有意水準)を決めておく。有意水準をp値が下回ったときに、はじめて「統計的有意差があった」と言うことができる。
なお、混同行列においては第1種の過誤は偽陽性、第2種の過誤は偽陰性に相当する。
5. ディープラーニングの概要
5.1 ニューラルネットワークとディープラーニング
キーワード
単純パーセプトロン、多層パーセプトロン、ディープラーニングとは、勾配消失問題、信用割当問題、誤差逆伝播法
ニューラルネットワーク
ニューラルネットワークとは人間の脳の中の構造を模したアルゴリズムのこという。入力を受け取る部分を入力層、出力する部分を出力層と表現する。入力層における各ニューロンと、出力層におけるニューロンの間のつながりは重みで表され、どれだけの値を伝えるかを調整する。そして、出力が0か1の値をとるようにすることで、正例と負例の分類を可能にする。ニューラルネットワークのモデルには、複数の特徴量(入力)を受け取り、1つの値を出力する(線形分離)単純パーセプトロン、入力層と出力層の間に隠れ層を追加することで非線形分類も行うことを可能とする多層パーセプトロンがある。
ディープラーニング
隠れ層を増やしたニューラルネットワークのこと。層が多い(深い)ため深層学習と呼ばれる。
| 畳込みニューラルネトワーク(CNN) | 画像認識など |
| 再帰型ニューラルネトワーク(RNN) | 時系列データなど |
| 自己符号化器(AutoEncoder) | 次元削減など |
勾配消失問題
ニューラルネットワークは、誤差逆伝播法によりモデルの予測結果と実際の正解値との誤差をネットワークの出力層から入力層にかけて逆向きにフィードバックさせる形でネットワークの重みを更新している。ネットワークを深くすると、伝搬する誤差がどんどん小さくなってしまうことを勾配消失問題という。入力層付近での学習が進まなくなるディープニューラルネットワーク特有の現象。もともとは事前学習を行うことによりこの問題を回避していたが、ReLUのように正規化機能を持たない活性化関数を中間層で用いるなど、現在は様々な工夫により事前学習なしでも学習が行えるようになっている。
5.2 ディープラーニングのアプローチ
キーワード
事前学習、オートエンコーダ、積層オートエンコーダ、ファインチューニング、深層信念ネットワーク、制限付きボルツマンマシン
事前学習(pre-training)
事前学習を用いた手法はディープラーニングの研究初期に考えられた。重み関数(重みの初期値)についてのより良い初期条件を得るために提案された教師なし事前学習法として、オートエンコーダ(自己符号化器)がある。オートエンコーダを順番に学習していく手順のことを事前学習といい、2006年にジェフリー・ヒントンが提唱した。事前学習では教師なし学習の手法が用いられますが、積層オートエンコーダにはオートエンコーダ、深層信念ネットワークには制限付きボルツマンマシンがそれぞれ用いられている。
事前学習の欠点
層ごとに順番に学習が進むため、全体の学習に必要な計算コストが非常に高くなってしまう。ディープラーニングの研究が活発になったことにより、今では事前学習が必要なくなった。勾配消失問題の原因であった活性化関数を工夫するといったテクニックを用いることでこれを実現した。
オートエンコーダ(autoencoder)
入力と出力が同じになるような層をもつニューラルネットワークであり、入力と出力がセットになった可視層と隠れ層の2層で構成される。可視層(入力) → 隠れ層 → 可視層(出力)と伝播し出力される。可視層の次元よりも隠れ層の次元を小さくする必要がある。
| エンコード(encode) | 入力層から隠れ層への処理 |
| デコード(decode) | 隠れ層から出力層への処理 |
圧縮の際に隠れ層は入力層より次元が減り、それを元に戻すことで情報が失われないことを次元削減という。自己符号化器を用いると主成分分析よりも複雑な非線形な次元削減を得られる。
積層オートエンコーダ(stacked autoencoder)
オートエンコーダのエンコーダおよびデコーダ部分を多層化した構造を持つ。オートエンコーダを順番に学習させ、それを積み重ねていくというアプローチをとる。ディープニューラルネットワークのように一気にすべての層を学習するのではなく、入力層に近い層から順番に学習させるという逐次的な方法をとる。ジェフリー・ヒントンが考案した。非線形な次元削減が可能。
ファインチューニング(fine-tuning)
既存の学習済みモデルに対して重みを一部再学習させ、特徴量抽出器として利用する手法であり、学習済みモデルの層の重みを微調整する。積層オートエンコーダを重ねて行った最後にのロジスティック回帰層(シグモイド関数またはソフトマック関数による出力層)を設けて、ロジスティック回帰層に重みの調整を行うことをファインチューニングという。積層オートエンコーダは事前学習とファインチューニングの工程で構成される。
深層信念ネットワーク
2006年にジェフリー・ヒントンが提唱した、教師なし学習(オートエンコーダに相当する層)に 制限付きボルツマンマシン(restricted boltzmannmachine)という手法を用いている。その後、学習させた制限付きボルツマンマシンを全て結合し、それをソフトマックス層などを追加して教師あり学習を行う。
5.3 ディープラーニングを実現するには
キーワード
CPU と GPU、GPGPU、ディープラーニングのデータ量、TPU
CPU(Central Processing Unit)とGPU(Graphics Processing Unit)
ディープラーニングを考える上ではハードウェアの進化の影響も大きい。Intel社の創設者の1人であるゴードン・ムーアが提唱した「半導体の性能と集積は、18ヶ月ごとに2倍になる」という経験則、通称ムーアの法則は今や限界を迎えてきたと言われている。
| CPU | ・コンピュータ全般の作業を処理する役割を担う。 ・様々な種類のタスクを順番に処理していくことに長けている。 |
| GPU | ・“graphics” という名前が表している通り、画像処理に関する演算を担う。大規模な並列演算処理に特化した存在。 ・GPUはCPUのように様々なタスクをこなすことができない。 |
GPGPU(General-Purpose computing on GPU)
画像以外の目的での使用に最適化されたGPUのこと。GPU(GPGPU)の開発をリードしているのが NVIDIA社であり、ディープラーニング実装用のライブラリのほぼ全てが NVIDIA社製の GPU 上での計算をサポートしている。
Google社はテンソル計算処理に最適化された演算処理装置を開発しており、TPU(Tensor Processing Unit)と呼んでいる。
ディープラーニングのデータ量
畳み込みニューラルネットワーク手法の1つである AlexNet(アレックスネット)モデルのパラメータ数は、約6000万個にもなる。「モデルのパラメータ数の10倍のデータ数が必要」というバーニーおじさんのルールと呼ばれる経験則がある。
5.4 活性化関数
キーワード
tanh 関数、ReLU 関数、シグモイド関数、ソフトマックス関数、Leaky ReLU 関数
活性化関数
ディープニューラルネットワークは隠れ層を増やしたネットワークであり、誤差を逆伝搬する際に勾配が消失しやすくなってしまうという課題がある。これは活性化関数であるシグモイド関数の微分の最大値が原因となっている。出力層では出力を確率で表現するためにはシグモイド関数が必須であるが、隠れ層では任意を実数を変換することができる微分可能な関数にしても問題ない。そこで、隠れ層には以下のような活性化関数が提案されている。
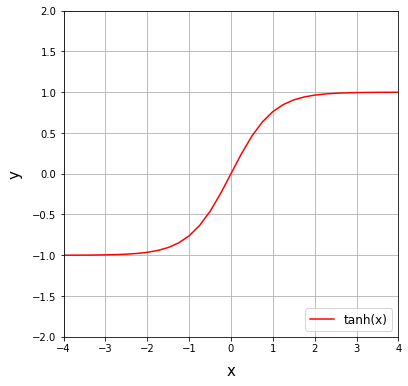
tanh関数
シグモイド関数を線形変換したもので、シグモイド関数が0から1の範囲をとるのに対して、tanh関数は-1から1の範囲をとる。シグモイド関数の微分の最大値が0.25であったのに対して、tanh関数の微分の最大値は1であるので、勾配が消失しにくい。一般的なディープニューラルネットワークの隠れ層の活性化関数にシグモイド関数が使われている場合、それはすべてtanh関数に置き換えたほうがよいことになる。
シグモイド関数よりは高い精度が出やすいものの微分の“最大値”が1であり、1より小さい数になってしまうケースが多い。そのため、勾配消失問題を完全に防ぐことはできない。
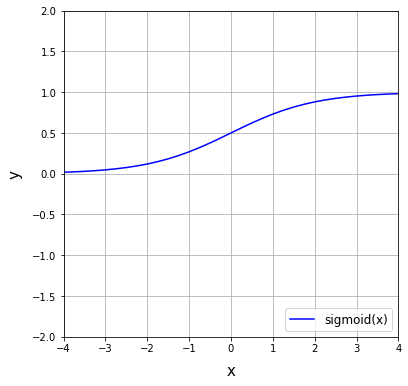
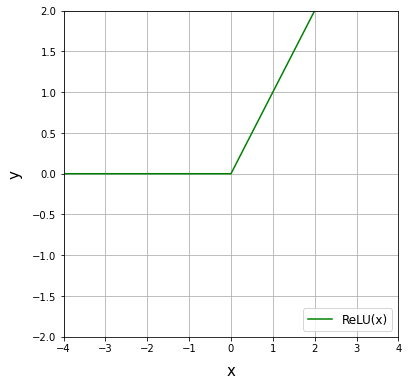
ReLU関数(Rectified Linear Unit)
tanh関数よりも勾配消失問題に対処できる。ReLU関数を微分すると0より大きい限り、微分値は常に最大値である1が得られることになる。tanh関数のようにピーク値のみが1のときと比較すると、誤差逆伝播の際に勾配が小さくなりにくい(勾配消失しにくい)。ReLUはステップ関数と同様に不連続な関数であり、数学的にはx=0の地点では微分ができない。
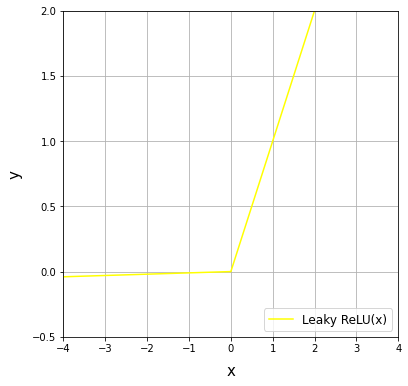
LeakyReLU関数
x<0においてわずかな傾きをもっている。これにより微分値が0になることはなくなるため、ReLUよりも勾配消失しにくい。ただし、Leaky ReLUよりもReLUのほうが結果がよい場合もある。
Parametric ReLU
Leaky ReLUのx<0部分の直線の傾きを学習によって最適化するモデル
Randomized ReLU
複数の傾きをランダムに試すモデル
5.5 学習の最適化
キーワード
勾配降下法、勾配降下法の問題と改善、学習率、誤差関数、交差エントロピー、イテレーション、エポック、局所最適解、大域最適解、鞍点、プラトー、モーメンタム、AdaGrad、AdaDelta、RMSprop、Adam、AdaBound、AMSBound、ハイパーパラメータ、ランダムサーチ、グリッドサーチ、確率的勾配降下法、最急降下法、バッチ学習、ミニバッチ学習、オンライン学習、 データリーケージ
機械学習の目標はモデルの予測値と実際の値との誤差を少なくすることである。これは誤差を誤差関数とすれば、関数の最小化問題と考えることができる。関数の最小化問題の一般的な手法として微分があるが、ニューラルネットワークにおいては高次元となるため、解析的に求めることが難しい。そこで、アルゴリズムを用いて最適解を探索するアプローチ手法として勾配降下法がある。
分類問題の誤差関数には主に交差エントロピー誤差が用いられる。
勾配降下法
勾配に沿って降りていくことで解を探索する方法。ここで言う勾配とは微分値にあたる。目的の解が得られるまで勾配に沿って降りていきながら、解を探索していく。これを解が見つかるまで繰り返し計算するのが勾配降下法。
このとき、何回繰り返し計算を行ったか(重みの更新を行った回数)を示す指標をイテレーション、訓練データを何度学習に用いたかをエポック、勾配に沿って一度にどれだけ降りていくかを決める割合をα(学習率)という。
ニューラルネットワークの「学習」とは、この勾配降下法を用いて繰り返し計算を行うことを指す。最適解が見つかるまで探索を継続するため、解が得られるまで時間がかかる。
訓練データが60000個、イテレーションを12000回、バッチサイズを100とした場合、エポック数は20回となる。
(60000/100 = 600、12000/600 = 20)
勾配降下法の問題と改善
| 局所最適解 | 最小に見えるが実際にそうではない見せかけの解 |
| 大域最適解 | 本当の解 |
| 停留点 | 解ではないが勾配が0になる点 |
勾配降下法は「見せかけの最適解」であるかどうかを見抜くことができないため、特に何も工夫をしないと局所最適解に陥ってしまう可能性が高くなる。
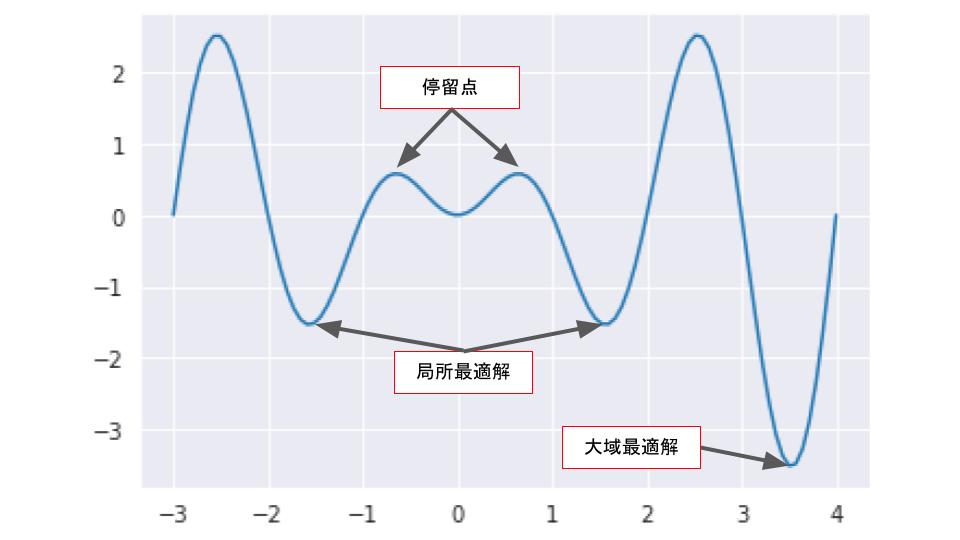
局所最適解を防ぐ方法として学習率の値を大きく設定する方法がある。山を越えるくらい学習率を大きくすれば、大域最適解に行き着くことができるが、最適解を飛び越えて探索し続けてしまうという問題が起こりやすくなってしまうので、適切なタイミングで学習率の値を小さくしていくことが必要になる。
鞍点
ある次元から見れば極小であるものの、別の次元から見ると極大となってしまっているものをいう。一度鞍点付近に陥ると、そこから抜け出すことは困難になる。鞍点で停留状態にあることをプラトーという。
鞍点問題への対処法として1990年代に提唱されたモーメンタムがある。最適化の進行方向に学習を加速させることで、学習の停滞を防ぐ。それぞれの特徴は登場順に以下の通り。
| Adagrad | 勾配に基づいて最適化するアルゴリズムであり、過去の観測データに関する情報を取り入れることで、学習率がベクトルの要素ごとのパラメータに適用する。パラメータごとに更新の進み具合を調整するため、過去の全て勾配の二乗和をパラメータごとに計算する。 |
| Adadelta | 2012年。Adagradの拡張版の最適化アルゴリズム。過去のすべての勾配を累積するのではなく、勾配更新の固定移動ウィンドウに基づいて、単調に減少する学習率を下げていく。学習率がない。 |
| RMSprop | Adagradの改善手法で、過去の情報を「忘れる」ことで精度向上を狙った |
| Adam | 2015年。RMSprop の改良版であり、勾配について以前の情報を指数的減衰させながら伝えることができる。移動平均で振動を抑制するモーメンタムと、学習率を調整して振動を抑制するRMSPropを組み合わせている。AdaGradとMomentumの利点を組み合わせた。 |
| AMSGrad | Adamの改良版で、パラメータを最適化するにため重要な特定のミニバッチの勾配情報を長期間保持するように設計された最適化手法。不必要な情報の学習率が大きくなる問題を防ぐように設計された手法だが、逆に学習率が小さくなりすぎて学習が停滞するケースもある。 |
| AdaBound | Adamの機能に学習率の上限と下限を動的に加えたもの。序盤はAdam、終盤はSGDのように振る舞うことで学習率の乱高下を抑える。 |
| AMSBound | AMSGradの機能に学習率の上限と下限を動的に加えたもの。序盤はAdam、終盤はSGDのように振る舞うことで学習率の乱高下を抑える。 |
ハイパーパラメータ
機械学習アルゴリズムの挙動を設定するパラメータをさす。この設定(ハイパーパラメータの値)に応じてモデルの精度やパフォーマンスが大きく変わることがある。誤差関数においては誤りをどの程度許容するかなど、人が事前に手動で設定する。
ランダムサーチ
ハイパーパラメータを自動調整するアルゴリズムのこと。パラメーターをランダムに選びモデルの訓練することで最適なハイパーパラメータを検討する。
グリッドサーチ
ハイパーパラメータを自動調整するアルゴリズムのこと。指定したハイパーパラメータの全ての組み合わせに対して学習を行い、もっとも良い精度を示したパラメータを採用する手法。
最急降下法
勾配降下法のアルゴリズムのひとつ。傾きの最も急な方向に降下することを意味し、最小二乗法とともに18世紀のドイツの数学者ガウスが発見した。最急降下法は最小二乗法をより一般化したもので、測定データとモデル関数の誤差による関数(誤差関数)の最小を求めるための最適化を行う方法。複雑な分類問題の場合、最適化問題を解くこと、すなわち誤差関数の最小を解析的に求めることは難しいため、反復学習によりパラメータを更新するアプローチをとる。誤差関数の導関数を求め、重みを更新して傾きである微分係数が0になる点を逐次的に探索する。最急降下法の問題点は、全てのデータを一度に扱うため計算量が多く遅いことであり、最急降下法をオンライン学習に改良したのが確率的勾配降下法。
確率的勾配降下法(SGD:Stochastic Gradient Descent)
勾配降下法の一種で、連続最適化問題に対する勾配法の乱択アルゴリズム。ランダムに選んだ1つのデータのみで勾配を計算してパラメータを逐次更新し、データの数だけ繰り返す。確率的勾配降下法の利点は局所最小に陥りにくいことだが、データ数が多い場合に計算量が膨大になる問題点がある。特定の次元が大きく、別の次元の傾きが緩やかであるような目的関数の場合には非効率な経路を辿ることから、目的関数の勾配の値が次元ごとに大きく異なる場合には用いない。
バッチ学習、ミニバッチ学習
重みの更新タイミングは学習方法によって異なる。
| 逐次学習 | 重みの更新タイミングは訓練データのサンプルごとに逐一重みを更新する | 確率的勾配降下法 |
| ミニバッチ学習 | 訓練データの一部分に対して重みを更新する | ミニバッチ勾配降下法 |
| バッチ学習 | 訓練データ全てに対して重みを更新する | 勾配降下法(バッチ降下法) |
オンライン学習
学習データが入ってくるたびにその都度、新たに入ってきたデータのみを使って学習を行う。学習を行う際に1からモデルを作り直すのではなく、そのデータによる学習で今あるモデルのパラメータを随時更新するというもの。
データリーケージ
機械学習で入っていはいけないデータが混入すること。
5.6 更なるテクニック
キーワード
ドロップアウト、早期終了、データの正規化・重みの初期化、バッチ正規化、過学習、アンサンブル学習、ノーフリーランチの定理、二重降下現象、正規化、標準化、白色化
ドロップアウト
過学習を防ぐ手法。学習の際にランダムにニューロンを「ドロップアウト」させるもの。もともとのネットワークから、学習の繰り返しごとにニューロンを除外することで、毎回形の異なるネットワークで学習を行う。一定割合のノードを不活性化することで過学習を抑制し、学習の精度を上げることができる。
早期終了(early stopping)
学習が進むにつれてテストデータに対する誤差関数の値は右肩上がりになる。上がり始めが過学習の始まりと考え、その時点が最適な解であるとして学習を止めることを早期終了という。ジェフリー・ヒントンは早期終了(early stopping)のことを“Beautiful FREE LUNCH”と表現。ノーフリーランチ定理という、「あらゆる問題で性能の良い汎用最適化戦略は理論上不可能」であることを示す定理を意識して発せられた言葉。最近の研究では一度テストデータに対する誤差が増えた後、再度誤差が減っていくという二重降下現象(double descentphenomenon)も確認されており、どのタイミングで学習を止めれば良いのかについては慎重に検討しなくてはならない。
データの正規化・重みの初期化
データの標準化は機械学習全般に対して効果的であるものの、活性化関数の影響により効果が薄くなってしまう。正規化しても層を伝播していくにつれ分布が徐々に崩れていくため、層の数が増えてもデータの分布が偏らないような方法が重みの初期値を工夫するというアプローチがある。
| 正規化 | データ全体を調整する処理のこと。最小値を0、最大値を1とするスケーリングするものがある。 |
| 標準化 | 平均を0、分散を1とするスケーリング手法 |
| 白色化 | 各特徴量を無相関化し、かつ、各特徴量を無相関化したうえで標準化(平均0・標準偏差1)するという手法。 白色化は計算コストが高いので、標準化を用いるのが一般的。 |
| 欠損値の処理 | 欠損しているデータを消去または補完する。 |
| 名寄せ | 表記の揺れを統一する。 |
乱数にネットワークの大きさに合わせて適当な係数をかけることで、シグモイド関数に対してはXavierの初期値(1/√n)を標準偏差とした分布を用いる)、ReLU関数に対してはHeの初期値がよいとされている。勾配降下法の探索は初期値に依存しているので、重みの初期値の設定は重要となる。
アンサンブル学習
複数の学習器を個別に学習し、それらの出力を平均することによって問題を解くこと。
基礎集計
データの傾向を事前に把握しておくこと。前処理よりもさらに前段階で行う。平均・分散・標準偏差などの算出や、散布図行列・相関行列によりデータの傾向を確認する。
特徴量エンジニアリング
カテゴリカル変数を変換するなど、与えられたデータからモデルが認識しやすい特徴を作ること。1つの成分を1、残りを0とすることをone-hot-encodingという。
6. ディープラーニングの手法
6.1 畳み込みニューラルネットワーク(CNN)
キーワード
CNN の基本形、畳み込み層、プーリング層、全結合層、データ拡張、CNN の発展形、転移学習とファインチューニング、ネオコグニトロン、LeNet、サブサンプリング層、畳み込み、フィルタ、最大値プーリング、平均値プーリング、グローバルアベレージプーリング(GAP)、Cutout、Random Erasing、Mixup、CutMix、MobileNet、Depthwise Separable Convolution、NAS (Neural ArchitectureSearch)、EfficientNet、NASNet、MnasNet、転移学習、局所結合構造、ストライド、カーネル幅,プーリング,スキップ結合、各種データ拡張、パディング
CNN(Convolutional Neural Network)
CNNは人間が持つ視覚野の神経細胞の2つの働きを模すという発想から生まれた順伝播型のニューラルネットワーク。
| 単純型細胞(S細胞) | 画像の濃淡パターン(特徴)を検出する |
| 複雑型細胞(C細胞) | 特徴の位置が変動しても同一の特徴であるとみなす |
LeNet
この2つの細胞の働きを最初に組み込んだモデルは福島邦彦らによって考案されており、ネオコグニトロンと呼ばれるもので多層構造をしている。その後1998年に、ヤン・ルカンによってLeNetと呼ばれる有名なCNNのモデルが考えられた。こちらは畳み込み層とサブサンプリング層(=プーリング層と同じ役割を持つ)の2種類の層を複数組み合わせた構造をしている。
ネオコグニトロンとLeNetは層の名前こそ違うものの、構造上は非常に似ている。ネオコグニトロンにおけるS細胞層がLeNetにおける畳み込み層、C細胞層がプーリング層にそれぞれ対応している。ただし、ネオコグニトロンは微分(勾配計算)を用いないadd-if silentと呼ばれる学習方法を用いるのに対し、LeNetでは誤差逆伝播法を用いる。
畳み込み層
畳み込み(convolution)処理を行う層のことで、フィルタ(またはカーネル)を用いて画像から特徴を抽出する。画像×カーネルの総和を求めて、新しい2次元データ(特徴マップ)を作る。フィルタの各値が通常のニューラルネットワークで言うところの重みになる。この畳み込み処理は局所受容野に対応しており、移動不変性の獲得に貢献する。畳み込み層によって、「位置のズレ」に強いモデルができる。
プーリング層
プーリング処理とは画像サイズを決められたルールに従って小さくすることをいい、ダウンサンプリングあるいはサブサンプリングとも呼ぶ。プーリングには、ある小領域ごとの最大値を抽出する最大値プーリング(max pooling)や平均値プーリング(average pooling)がある。畳み込み層と異なり、プーリング層には学習すべきパラメータは存在しない。
全結合層
出力用にデータを一次元にする層のこと。CNN(LeNet)では、畳み込み層・プーリング層を繰り返した後、全結合層という通常のニューラルネットワークと同じ構造を積層する。
最近のCNNの手法では、この全結合層の代わりに特徴マップの平均値を1つのユニット(ニューロン)の値にするGlobal Average Poolingと呼ばれる処理を行うことが多い。
データ拡張(data augmentation)
手元にある画像から擬似的に別の画像を生成するというアプローチ。データの「水増し」ともいわれる。手元にある画像に対して、ランダムにいくつかの処理を施して新しい画像を作り出す。データ拡張の効果は大きく画像認識の分野では必須の処理であるが、回転等により画像の意味が変わってしまう場合があるので注意すること。
| Cutout | 画像の一部分を遮蔽したようなデータを擬似的に生成 マスク処理を行う対象領域の大きさとアスペクト比を一定にする |
| Random Erasing | 画像にランダムな一部矩形領域をマスクする マスク処理を行う対象領域の大きさとそのアスペクト比をランダムに設定 |
| Mixup | 2枚の画像を合成して実在しない画像を擬似的に生成 |
| CutMix | CutoutとMixupを組み合わせたもの |
画像データの前処理
画像データに対しては、例えば「OpenCV」のライブラリを用いて前処理を施すことができる。
| グレースケール化 | カラー画像を濃淡画像に変換して計算量を削減する手法。 |
| 平滑化 | 細かいノイズの影響を除去する手法。ノイズは周辺の値とは無関係に発生し、高周波成分となると考えられる。 |
| ヒストグラム平坦化 | コントラスト(濃淡比)を調整する手法。 |
CNNの発展形
AlexNet以降、より深いネットワークモデルが続々と登場した。VGGやGoogLeNetは、10から20層程度の深さだが、さらに「超」深層になると識別精度が落ちるという問題に直面する。その後、更に深いネットワークを実現するためにSkip connectionと呼ばれる「層を飛び越えた結合」を加えたネットワークであるResNetが登場。層が深くなっても、層を飛び越える部分は伝播しやすくなり、様々な形のネットワークのアンサンブル学習になっているという特徴をもつ。現在では100層以上のネットワークが構築されることもある。
| VGG (2014年) | 畳み込み層→畳み込み層→プーリング層のセットを繰り返し、16層まで積層。VGGでは、深くなっても学習できるよういったん少ない層数で学習した後、途中に畳み込み層を追加して深くする学習方法を採用。 |
| GoogLeNet (2014年) | 層を深くするだけでなく、同時に異なるフィルタサイズの畳み込み処理を行うInceptionモジュールを導入。Inceptionモジュールを積層することで深いネットワークにしつつ、着目する範囲が異なる特徴を合わせて捉えることがでる。勾配消失問題回避のため補助的な損失にツンがる分岐機構が導入された、 |
| ResNet (2015年) | 更に深いネットワークを実現するためにSkip connectionと呼ばれる「層を飛び越えた結合」を加えたネットワーク。 層が深くなっても、層を飛び越える部分は伝播しやすくなり、様々な形のネットワークのアンサンブル学習になっている。 |
MobileNet
モバイル端末などの使用できるメモリ量が限られている環境でも利用できるよう、畳み込み層のパラメータ数を削減するモデル。畳み込み処理の代わりにDepthwise Separable Convolutionを用いることで通常の畳み込み処理と比べて計算量を1/8程度に削減している。
Depthwise Separable Convolution
空間方向とチャネル方向に対して独立に畳み込み処理を行う。空間方向はDepthwise Convolution、チャネル方向はPointwise Convolutionと呼ぶ。Depthwise Convolutionは、特徴マップのチャネル毎に畳み込み処理を行い、Pointwise Convolutionは、1×1の畳み込み処理を行う。
Depthwise Convolutionの計算量はO(H W N K2)、Pointwise Convolutionの計算量はO(H W N M)となります。通常の畳み込み処理をDepthwise Separable Convolutionに置き換えることで、計算量がO(H W N K2 M)からO(H W N K2 + H W N M)に削減できる。ただし、通常の畳み込み処理の近似計算なので、精度は一致しない。
Neural Architecture Search(NAS)
リカレントニューラルネットワーク(RNN)と深層強化学習を用いてネットワーク構造を探索。認識精度が高くなるよう深層強化学習によりネットワークを生成する部分を学習。生成する単位をResNetのResidual Blockようなセットにする工夫を導入したNASNetや、認識精度だけでなくモバイル端末での計算量も考慮する工夫を導入したMnasNetなどもある。
MnasNet
googleによって発表されたNASNetのモバイル版であり、AUTOMLを参考にしたモバイル用のCNNモデル設計。速度情報を探索アルゴリズムの報酬に組み込むことで、速度の制約に対処している。
EfficientNet〈実装はこちら〉
Google Brainが発表した、従来よりも少ない(1/8程度)パラメータ数で高い精度が出せるモデル。NASによる探索結果をベースに構築された。モデルがシンプルで理解しやすく、転移学習も非常に高い制度で行うことができる。互いに3つのハイパーパラメータ(深さ・広さ・解像度)を調整するCompound Coefficient(複合係数)を導入することで制度をあげている。
BiT(Big Transfer)
Google Brainが2019年に発表した画像認識モデル。10個にも及ぶ膨大なパラメータ数でバッチ正規化やドロップアウトなどの技術を使用せずにSoTAとなった。BiTハイパーパラメータと呼ばれる、「画像サイズ」「MixUp」「ステップ数」を調整して学習を行う。
転移学習
ImageNetで学習したモデルなどに新たに何層かを自分で追加して、その層だけを学習すること。転移学習では最終層の結合のみ学習し、下位層の重みは固定している場合が多い。
ファインチューニング
付け足した層だけではなく、ネットワーク全体(全層の結合)を学習する方法。
フィルタサイズ(カーネル幅)
入力データサイズ(W,H)、フィルタサイズ(FH,FW)、ストライドS、パッディング幅Pとする。
| Hout | Wout |
| 1 + (H + 2P - FH) / S | 1 + (W + 2P - FW) / S |
入力データサイズ(4,4)、フィルタサイズ(3,3)、ストライド1、パッディング幅1とすると、主力される行列サイズは4x4となる。
6.2 深層生成モデル
キーワード
生成モデルの考え方、変分オートエンコーダ (VAE)、敵対的生成ネットワーク (GAN)、ジェネレータ、ディスクリミネータ、DCGAN、Pix2Pix、CycleGAN
生成モデルの考え方
画像のデータセットがどのような分布になっているかを推測し、その分布に基づいて元の画像と似たような画像データを生成する(サンプリングする)ことを目的としたモデルを生成モデルという。このうちディープラーニングを取り入れた生成モデルを深層生成モデルという。
変分オートエンコーダ(Variational AutoEncoder)
通常のオートエンコーダと同様、エンコーダ部分とデコーダ部分を持つモデル。分布関数の変分パラメータϕを導入し、変分下限を求めることができる。
入力データを圧縮表現するのではなく統計分布に変換し、平均と分散で表現するように学習する。エンコーダが入力データを統計分布のある1点となる潜在変数に変換し、デコーダは統計分布からランダムにサンプリングした1点を復元することで、新しいデータを生成。
敵対的生成ネットワーク(GAN)
教師なし学習のネットワークであり、イアン・グッドフェローが考案した。2種類のネットワークで構成されており、それぞれをジェネレータ(generator)とディスクリミネータ(discriminator)という。
| ジェネレータ | ランダムなベクトルを入力とし、画像を生成して出力。 |
| ディスクリミネータ | 画像を入力とし、その画像が本物か(ジェネレータによって生成された)偽物かを予測して出力。 |
ディスクリミネータによる予測結果はジェネレータにフィードバックされる。GANは2種類のネットワークを競い合わせることで、最終的には本物と見分けがつかないような新しい画像をつくりだすことを実現。ヤンルカンはGANのことを「この10年で最も面白いアイディア」と褒めている。
DCGAN(Deep Convolutional GAN)
GANにCNNを適用し、ネットワークを深くした手法。GeneratorとDiscriminatorそれぞれのネットワークに全結合層ではなく、畳み込み層(と転置畳み込み層)を使用している。高解像度な画像の生成することができる。
Pix2Pix
GANを利用した画像生成アルゴリズムの一種で、2つのペアの画像から画像間の関係を学習し、画像を生成する予測モデルと生成された画像が偽画像かどうか判定する判定器を競わせあうことで、その関係を反映したペア画像を生成する技術であり、ベクトルの代わりにある画像データを入力し、別の画像に変換する処理を行う。あらかじめペアの画像を学習のために用意しておく必要がある。
Cycle GAN
スタイル変換による画像生成手法であり画像のペアが必要ない。1つ画像を与えると、その画像から一度似ている画像に変換し、そしてもう一度元の画像に戻るように変換する。GANのように、変換した画像が本物かどうかを予測するだけでなく、元の画像と再度変換した画像が一致するように学習する方法。馬の画像をシマウマに変換することができる。
Stack GAN
入力されたテキストに基づく画像生成ができる。
6.3 画像認識分野
キーワード
物体識別タスク、物体検出タスク、セグメンテーションタスク、姿勢推定タスク、マルチタスク学習、ILSVRC、AlexNet、Inception モジュール、GoogLeNet、VGG、スキップ結合、ResNet、Wide ResNet、DenseNet、SENet、R-CNN、FPN、YOLO、矩形領域、SSD、Fast R-CNN、Faster R-CNN、セマンティックセグメンテーション、インスタンスセグメンテーション、パノプティックセグメンテーション、FCN (Fully Convolutional Netwok)、SegNet、U-Net、PSPNet、Dilation convolution、Atrous convolution、DeepLab、Open Pose、Parts Affinity Fields、Mask R-CNN
物体(画像)識別タスク〈実装はこちら〉
画像に写る物体名称を出力するタスクであり、確信度が最も高い名称を結果として出力するクラス分類にあたる。CNNで活躍しているモデルがこの分野にあたる。
| ILSVRC | 識別タスクとして開催されている大会。 |
| 2012年 | アレックスネット(AlexNet)が従来手法の精度を圧倒し、ディープラーニングに基づくモデルとして初めて優勝。 |
| 2014年 | Inceptionモジュールというカーネルサイズの異なる複数の畳み込み層から構成される小さなネットワークを積層したGoogLeNetが優勝。 |
| 2015年 | 超多層でも学習がうまくいくように考えられたSkip connectionを導入したResNetが優勝。エラー率はおおよそ0.05。 |
| 2017年 | 畳み込み層が出力した特徴マップに重み付けするAttention機構を導入したSqueeze-and-Excitation Networks(SENet)が優勝 |
Inception (インセプション)モジュール
小さなネットワークを1つのモジュールとして定義している。複数のフィルタ群によるブロックから構成され、ネットワークを分岐させサイズの異なる畳み込みを行う。
物体検出タスク〈実装はこちら〉
入力画像に写る物体クラスの識別とその物体の位置を特定するタスク。バウンディングボックスと呼ばれる短形の領域で位置やクラスを認識する。画像内に含まれる関心対象の物体を自動的に背景から区別して位置特定することができる。物体の位置は、矩形領域(四角形)とし、その左上の座標と右下の座標を出力する。入力画像から物体領域候補を選択的検索という手法により抽出する。
| 2段階モデル | 一段階モデルと比べ、正確性は優れているが処理は低速 |
|---|---|
| R-CNN | 画像から物体候補領域をSelective Searchという方法で抽出。物体候補領域は一定のサイズにリザイズ後、CNNに入力する。最終判定はサポートベクターマシン(SVM)によるクラス識別をするが、この組み合わせは時間がかかる。 |
| Fast R-CNN | R-CNNの構造を簡略化して高速したモデル。物体候補領域をCNNに入力するのではなく、画像全体を入力して特徴マップを獲得することで高速化する。特徴マップ上で物体候補領域に相当する部分を切り出し、識別処理を行う。 |
| Faster R-CNN | Fast R-CNNまで使用していたSelective Searchという方法は処理時間がかかるため、この処理を領域提案ネットワーク(Region Proposal Network)というCNNモデルに変更して更なる高速化を図ったモデル。様々なサイズの特徴マップを固定サイズに変換するため、最大プーリングを行うROIプーリングを用いる。 |
| FPN(Feature Pyramid Network) | 前段のボトムアップなCNNの後段に、deepな層とshallowな層をトップダウンに接続した上で、更に各スケール階層同士をスキップ接続でつないで、砂時計型Encoder-Decoderを構成するの特徴集約のCNNバックボーンを拡張する構造である。 |
| 1段階モデル | 位置の特定とクラスの識別を同時に行う |
|---|---|
| YOLO | 出力層を工夫して入力画像の各位置における物体領域らしさと短径領域を直接出力。この各位置は入力画像の画素単位ではなく、グリッドに分割した領域単位。検出と識別を同時に行うことで、遅延時間の短縮を実現した一段階モデルの最初のモデル。バッチ正規化や入力画像サイズの高解像度化などを工夫した派生モデルがある。 |
| SSD | CNNの途中の特徴マップからYOLOのように領域単位で物体らしさと短径領域を出力。デフォルトボックスという短径領域のテンプレートのようなパターンに対するズレを出力する工夫も導入されている。YOLOよりもフィルタサイズを小さくしており、YOLOより高速で、Faster RCNNと同等の精度を実現。 |
セグメンテーションタスク〈実装はこちら〉
画像の画素ごとに識別を行うタスク。
| セグメンテーションタスク | 画像中の全ての画素に対して(画像全体を対象)、クラスラベルを予測することを目的とする。同一クラスの物体をひとまとめにするので、集団の歩行者などを一人一人分離することはできない。 |
| インスタンスセグメンテーション | 画像中の全ての物体に対して(物体検出をした領域を対象)クラスラベルを予測し、一意のIDを付与することを目的とする。重なりのある物体を別々に検出する点や、空や道路などの定まった形を持たない物体などはクラスラベルの予測を行わない点がある。各物体に対して一意のIDを付与するため、1つの画像に複数の車が写っている場合にはそれぞれの車を別々の物体と認識することが可能。 |
| パノプティックセグメンテーション | 上の2つのセグメンテーションを組み合わせたタスク。画像中の全ての画素に対して、クラスラベルを予測し、一意のIDを付与することを目的とする。個々の物体をそれぞれ分離しつつ、道路や建物などはひとまとめにすることができる。 |
FCN(Fully Convolutional network)
FCNは全結合層を用いず、畳み込み層だけで構成するモデルで、CNNをセマンティックセグメンテーションタスクに利用した方法。FCNには様々な方法が存在する。画像アップリングの際に逆畳み込み層を用いて特徴マップの画像サイズを大きくする。
| SegNet | 畳み込み層とプーリング層を繰り返し積層し、小さくなった特徴マップを徐々に拡大する構造を採用している。特徴マップを徐々に小さくしていく部分をエンコーダ、徐々に大きくしていく部分をデコーダという。エンコーダ部分は、CNNモデルであるVGG16の一部が採用されたシンプルな作りとなっている。デコーダ部分は、Up sampled層と呼ばれる層を通過させることで、インプットと同じ大きさに復元をする。エンコーダ側の最大値プーリングした位置を記憶しておき、デコーダ側の拡大時に記憶していた位置に特徴マップの値を配置して、それ以外の位置の値を0にすることで、境界付近のセグメンテーション結果をぼやけさせない工夫がされている。 |
U-Net | デコーダ側で特徴マップを拡大して畳み込み処理する際にエンコーダ側の特徴マップと同じサイズになるように切り出して利用するモデル。X線画像の医療画像新台位に用いられてる。U-Netでは、Skipconnectionと呼ばれるエンコーダー部で取得した画像の特徴マップを、デコーダー部で再活用することのできる構造が採用されているため、プーリングや畳み込みといった層を通過する際の情報削減に強い特徴を有したセマンティックセグメンテーションモデルである。 |
| PSPNet | エンコーダとデコーダの間にPyramid Pooling Moduleという、複数の解像度で特徴を捉えるモジュールを追加したもの。Pyramid Pooling Moduleは、エンコーダで得られた特徴マップを異なるサイズでプーリングし、それぞれの大きさで畳み込み処理を行う。画像全体や物体の大きさに応じた特徴をマルチスケールで捉える方法となっている。 |
| DeepLab | Atrous convolutionを導入したモデルで、これはカーネルサイズを大きくすると広い範囲の情報を集約できるが、計算量とパラメータ数が増えてしまうという問題に対するアプローチ。カーネルサイズ33、間隔を2とすると入力の77の範囲の情報を集約します。畳み込み演算をする位置を2画素ずつあけて行うことで、カーネルサイズは3*3のままなので計算量と学習するパラメータは増えない。処理が全く同じDilated convolutionも存在する。 |
| Dilated convolution | DeepLabと同じ。2018年にGoogle社が発表。 |
| Atrous convolution | カーネルサイズを大きくすると広い範囲の情報を集約できるが、計算量とパラメータ数が増えてしまうという問題に対するアプローチ。処理が全く同じDilated convolutionも存在する。 |
| DeepLab V3+ | SegNetやU-Netのようなエンコーダとデコーダ構造、PSPNetのような複数解像度の特徴を捉える機構(ASPP: Atrous Spatial Pyramid Pooling)を採用したモデル。 |
姿勢推定タスク〈実装はこちら〉
人の頭や足、手などの関節位置を推定するタスク。監視カメラで人の異常行動を認識したり、スポーツ映像から人の動作を解析したりすることができる。関節の位置は人の姿勢により大きく異なるため、信頼度マップによるアプローチが有効。
| Open Pose | 複数の人の骨格を同時に推定できるようにした手法。画像中に複数人いる場合、どの頭の位置とどの肩の位置が同じ人物に属するかわからないため、Parts Affinity Fieldsと呼ばれる骨格間の位置関係を考慮した処理を導入している。 |
マルチタスク学習
複数のタスクを1つのモデルで対応することをマルチタスクという。Faster R-CNNやYOLOなどの物体検出モデルは、物体クラスの識別と物体領域の位置検出を同時に行っているのでマルチタスクといえる。
| Mask R-CNN | Faster R-CNNによる物体検出だけでなく、セグメンテーションも同時に行うマルチタスクモデル。セグメンテーション部分は物体検出した領域ごとに行うので、インスタンスセグメンテーションにあたる。 |
6.4 音声処理と自然言語処理分野
キーワード
データの扱い方、リカレントニューラルネットワーク (RNN)、Transformer、自然言語処理における Pre-trained Models、LSTM、CEC、GRU、双方向 RNN (Bidirectional RNN)、RNN、Encoder-Decoder、BPTT、Attention、A-D 変換、パルス符号変調器(PCM)、高速フーリエ変換 (FFT)、スペクトル包絡、メル周波数ケプストラム係数 (MFCC)、フォルマント、フォルマント周波数、音韻、音素、音声認識エンジン、隠れマルコフモデル、WaveNet、メル尺度、N-gram、BoW (Bag-of-Words)、ワンホットベクトル、TF-IDF、単語埋め込み、局所表現、分散表現、word2vec、スキップグラム、CBOW、fastText、ELMo、言語モデル、CTCSeq2Seq、Source-Target Attention、Encoder-Decoder Attention、Self-Attention、位置エンコーディング、GPT、GPT-2、GPT-3、BERT、GLUE、Vision Transformer、構文解析、形態要素解析
6.4.1 音声認識
音声認識〈実装はこちら〉
人間の会話を機械に認識される技術全般をいう。Apple社のSiri、Amazon社のAlexaなどのスマートスピーカーが一般に普及している。これまでは隠れマルコフモデルによって行われていた推論が深層学習に置き換えられることで、音声認識の精度は精度は向上している。
音声合成
テキストから話している音声を作り出すこと。音声認識と同様にこれまでは隠れマルコフモデルによって行われていた推論が深層学習に置き換えられることで、音声認識の精度は精度は向上している。
A-D変換(Analog to Degital Conversion)
音声は時間とともに連続的に変化するアナログデータであり、コンピュータで扱うには離散的なデジタルデータに変化する必要がある。この音声を離散的なデジタルデータに変換する処理のことをA-D変換と呼ぶ。音声はパルス符号変調(PCM : Pulse Code Modulation)という方法で変換されるのが一般的であり、PCMでは連続的な音波を一定時間ごとに観測する標本化(サンプリング)、観測された波の強さを予め決められた値に近似する量子化、量子化された値をビット列で表現する符号化の3ステップを経てデジタルデータに変換します。パルス符号変調は、アナログ信号のデジタル化に用いられる変調方式であるが、自然界の現象のアナログ信号をデジタル信号に変換する際は標本化→量子化→符号化の順で処理を行う。
高速フーリエ変換(FFT : Fast Fourier Transform)
音声信号は刻々と変化するため、そこに含まれる周波数成分も変化する。そのため非常に短い時間ごとに周波数解析を行う必要がある。これを解決するために周波数解析をなるべく少ない計算量で、高速で行う手法がFFT。FFTにより音声信号を周波数スペクトルに変換できる。周波数スペクトルは周波数、色、音声や電磁波の信号などど関係の深い概念である。
メル周波数ケプストラム係数(MFCC : Mel-Frequency Cepstrum Coefficients)
音は「高さ」「長さ」「強さ」「音色」という属性を持ち、「音色」は音の違いを認識する上で重要な要素である。高さ、長さ、強さが全く同じ音であっても異なる音として認識できる場合は「音色」が違うといえる。音色の違いはスペクトル包絡(スペクトル上の緩やかな変動)の違いと解釈することが多く、このためスペクトル包絡を求める方法としてMFCC(メル周波数ケプストラム係数)がある。
フォルマント
MFCCを用いると入力された音のスペクトル包絡に相当する係数列が得られ、これが「音色」に関する特徴量となり、音声認識等で使用する。なおスペクトル包絡を求めるといくつかの周波数でピークを迎えるが、このピークをフォルマントと呼び、周波数の低いピークから第1フォルマント(F1)、第2フォルマント(F2)と表現する。音声の母音によって大きく異なる。
フォルマント周波数
フォルマントのある周波数をフォルマント周波数という。入力された音声の音韻が同じであればフォルマント周波数は近い値になるが、個人差による多少のズレは生じる。
HMM(隠れマルコフモデル)
HMMは音素ごとに学習するモデルで、観測されない隠れた状態をもつマルコフ過程モデルであり、音声合成や音声認識の世界では、このHMMの統計的手法により大量のデータを集め、多数のコーパスを用意するものが一般的で長い間用いられてきた。しかし、2016年にNNのアルゴリズムを使ったWaveNetと呼ばれる高性能モデルが登場した。
マルコフ性とは、確率論における確率過程の持つ特性の一種で、その過程の将来状態の条件付き確率分布が、現在状態のみに依存し過去のいかなる状態にも依存しない特性を持つことをいう。過去の状態が与えられたとき、現在の状態(過程の経路)は条件付き独立となる。
WaveNet
2016 年にDeepMind社により発表されたCNNで使われている畳み込み処理を行なっているモデル音声合成と音声認識ができて、従来に比べて圧倒的に高い質での音声合成に成功している。AIやスピーカーが人間に近い自然な言語を話すことなどに大きく寄与している。
メル尺度
人間の耳に聞こえる音の高さを表すように改良した尺度。通常の音の周波数とメル尺度とで互いに変換を行うことができ、通常の周波数と比較して緩やかに増加することが知られている。
メル周波数ケプトラム係数(MFCC)
メル尺度に様々な処理を施した結果得られる係数のことであり、音声認識に特徴量として用いられる。音色に対応した値であり、MFCCを用いることで音の高さの影響を受けずに音の類似度を測定することができる。
6.4.2 自然言語処理(Natural Language Processing)
自然言語処理(Natural Language Processing)
人間の言語(自然言語)を機械で処理し内容を抽出する技術全般をいう。言葉や文章といった日常のコミュニケーションで使う「話し言葉」や書籍や論文のような「書き言葉」までの自然言語を対象として、言葉が持つ意味をさまざまな方法で解析する。
日本語の自然言語処理では形態素分解を行い文章を最小単位に切り分けデータクレンジングにより不要な単語を取り除いた後、Bowなどにより形態素解析を行ったデータをベクトルに変換し、TF-IDなどを用いて各単語の重要度を評価する。
形態素解析
言語を意味を持つ最小単位である「形態素」に分割し、その形態素の品詞の判定をすること。日本語や東アジアの諸言語における形態素解析の処理では、平文を分かち書きにした各要素を入力表現に使用することが行われる。
構文分析
形態素解析からその形態素間の構文的関係を解析すること。
含意関係解析
2つの文の間に含意関係が成立するかを判定すること。
意味解析
構文解析から意味を持つまとまりを判定をすること。
文脈解析
文単位で構造や意味を判定すること。
照応解析
照応詞の指示対象や省略された名詞、代名詞などが指す対象を推定または補完すること。
談話解析
文章中の文と文の意味的な関係や話題の推移を判定すること。
n-gram
文字列は複数個の単語を並べたものと表現することができるが、これを単語n-gram(nは並べる個数)と呼ぶ。n-gramは単位となるものを複数個並べたものという意味なので、単位が文字なら文字n-gram、音声なら音素n-gramなどが使われる。n=1の場合をuni-gram、n=2の場合をbi-gram、n=3の場合をtri-gramと呼ぶ。
Bag-of-Words(BoW)
単語を単位として文書を表現するため文や文書をそこに出現する単語の集合として表現する際に、どの単語が含まれるかに注目をして単語をベクトル化(数値化)する方法をBag-of-Words(BoW)と呼ぶ。
具体的には文書の数をk、出現しうる単語の数をnとしたとき、その文書内の出現回数をk*nのテーブルを作ってベクトル表現する方法。
Bag-of-n-grams
BoWでは単語がバラバラに保存されているため出現順序の情報は失われてしまうが、局所的な出現順序が意味を持つ場合がある。そこでn-gramとBowを組み合わせたBag-of-n-gramsを利用することもある。
ワンホットベクトル(one-hot vector)
単語をコンピュータで扱う際は文字列としてではなく数値に変換して扱うのが一般的で、単語もベクトルとして入力する必要がある。各単語に異なる整数値を順に割り当ててID化を行い、このIDに相当するベクトルの次元の値だけが1で他全てを0となっているワンホットベクトルに変換するという方法がある。BoWで表現された文書も、各次元の値がその次元に相当する単語の文書中の出現頻度である1つのベクトルとして表現できる。
TF-IDF(Term Frequency-Inverse Document frequency)
TFとIDFという2つの値を掛け合わせたもので、文書中に含まれる単語の重要度を評価する手法。TFは1つの文書内での単語の出現頻度、IDFはある単語が出現する文書の割合の逆数の対数を取ったもの。出現する文書の数が少ない単語ほど大きな値となるため、TF-IDF値の大きさがある程度のその単語の重要度を示す。
TF-IDF値は文章中の単語数の違いが影響してくるという欠点がある。改良手法にOkapi BM25があり、TF値とIDF値に加えて文書中の総単語数であるDL(Document Length)値を用いて単語の重要度を測定する。
局所表現
ワンホットベクトルは値が0か1しかなく離散的で、1をとる次元が1つしかないため情報が疎かであり、次元数が単語の種類数と等しいため非常に高次元であるという特徴がある。このような単語の表現を局所表現という。
分散表現 ⇨
局所表現を連続的で情報が密であり、次元数の低いベクトルに変換する単語の表現を分散表現または単語埋め込みと呼ぶ。単語を分散表現で表すことで、ベクトル間の距離や位置関係から単語の意味を表現することができる。この分散表現学習は自然言語処理の分野における成功の1つで、これはある種の意味的な演算が行えることを示した。
word2vec ⇨
単語をベクトルとして表現する手法で、2013年にgoogle 社のミコロフが枠組みを提案。分散表現を得る代表的な手法で、「単語の意味は、その周辺の単語によって決まる」という分布仮説をNNを用いて推論ベースで実現した手法であり、word2vecにはスキップグラムとCBOWという2つの手法がある。このようなモデルを「ベクトル空間モデル」や「単語埋め込みモデル」とも呼ぶ。単語の互いの意味の近さの計算や加減のような演算ができる。
word2vecの演算事例としてV(Prince) - V(Male) + V(Female) ≒ V(Princess)
スキップグラム
「ある単語が与えられたときに、その周辺に現れる単語を予測する」問題と捉え、精度よく答えられるように、各単語の分散表現ベクトルを学習するモデル。
CBOW
スキップグラムとは逆に、周辺の単語からある特定の単語を予測するモデル。
fastText
(2013年にトマス・ミコロフが開発した)word2vecの延長線上にあるライブラリであり、個々の単語を高速でベクトルに変換しテキスト分類を行う。word2vecと比較した場合の変更点は、単語埋め込みを学習する際に単語を構成する部分文字列の情報を含めることであり、部分文字列の情報を併用することで訓練データには存在しない単語であっても単語埋め込み計算をすることが可能。さらに学習に要する時間が短いという特徴もある。Wikipediaとコモンクロールを用いて訓練した世界中の157言語によるそれぞれの訓練済みデータを提供している。
ELMo
word2vecやfastTextで得られる分散表現は各単語1つだけだが、これだと多様性をもつ単語や他の特定の単語と結びついてしまい、特別な意味をもつ単語などを正しく扱うことができない。そこで文脈を考慮した分散表現を得る手法としてELMoが提案された。2層のLSTMによって構成され、順方向のLSTMと逆方向のLSTMの出力の和を求める構造。
ELMoを用いると複数の意味を持つ単語であっても、その単語が出現した文の他の単語の情報からその文において適切な意味を表した分散表現を得ることができる。
RNN(リカレントニューラルネットワーク)
再帰構造(内部に閉路)をもち、時系列データを扱うために開発された再帰型ニューラルネットワークモデル。再帰構造によって、隠れ層に情報を一時的に記憶できるようになった。自然言語処理でよく用いられる。過去の入力による隠れ層(中間層)の状態を保持し、現在の入力に対する出力を求めるのに使用する。過去に入力された単語列から次に来る単語を予測するもので、音声処理でも自然言語処理でも使用される。
リザバーコンピューティング
リカレントニューラルネットワークの特殊なモデルを一般化した概念で、時系列情報処理に適した機械学習の枠組みのひとつ。他のリカレントニューラルネットワークモデルに比べて、学習が極めて高速である特徴を持つ。大自由度力学系が示す多様な時空間パターンを活用したモデルであり、RNNの学習方法の1つとして考案された。時系列パターン認識への応用が期待されるとともに、エネルギー効率が高い機械学習デバイスを実現するための基礎技術としても注目されている。
教師強制
RNNの学習において、各タイムステップでの入力に教師データを用いる方法。訓練時に入力として、前の時間の正解値(目標値)を利用する。教師データがあることで学習の収束が早くなる可能性があるが、教師データが使えない状況では出力に誤差が生じる可能性がある。
LSTM(Long Short-Team Memory)
RNNが抱えている課題である勾配消失問題、入力重み衝突(重みは大きくすべきであり、同時に小さくすべきであるという矛盾)、出力重み衝突を解決するために考えられた内部にゲート構造をもつRNNの改良モデル。「CECという情報を記憶する構造」と「データの伝搬量を調整する3つのゲートを持つ構造」で構成されている。CECは誤差を内部に留まらせて勾配消失を防ぎ、3つの入力・出力・忘却ゲートは各重み衝突に対応、誤差過剰を防止する忘却も持つ。LSTMにおける忘却ゲートはシグモイド関数で、入力信号を0から1の間で調整する。画像キャプション生成にも利用されている。
BPTT(BackPropagation Through-Time)
RNNの学習方法で時間軸に沿って誤差を反映していく(誤差が時間をさかのぼって逆伝播する)。RNNではBPTT(Back Propagation Through Time)を用いた学習が有効である場合がある。
CTC(Connectionist Temporal Classification)
LSTMネットワーク等のRNNをトレーニングして、タイミングが可変であるシーケンス問題に取り組むためのニューラルネットワーク出力と関連するスコアリング関数。RNNに音声データを時間軸に沿って入力していき、入力された音声の音素を出力として得ることで音声認識を実現できるが、入力された音声データ数と認識すべき音素の数は必ずしも一致しない。この矛盾を解決した方法が、CTC(Connectionist Temporal Classification)。CTCでは出力候補として音素に加えて空文字を追加し、さらに連続して同じ音素を出力した場合には1度だけ出力したものと縮約する処理を行い、出力長と正解長の違いに対処している。
GRU(Gated Recurrent Unit)
ゲート付き回帰型ユニット。LSTMは計算量が多いため、LSTMをやや簡略化した手法。GRUでは入力・出力・忘却の代わりにリセットゲートと更新ゲートという2つのゲートが同じ役割を果たす。画像キャプション生成にも利用されることがある。
双方向RNN(Bidirectional RNN)
双方向性回帰型ニューラルネットワークでBiRNNともいう。過去の情報だけでなく、過去と未来の両方の情報を使って予測した方が効果的と考えられ生まれたRNNの応用モデル。RNNを2つ組み合わせることで、過去と未来の両方の情報を踏まえた出力ができる。文章の推敲、機械翻訳、フレーム間の補完などのタスクに使用される場合がある。
seq2seq(sequence-to sequence)
これまで入力は時系列で出力が1つだったが、これを入力が時系列なら出力も時系列で予測に対応したモデル。自然言語分野で活発に研究され、機械翻訳で注目されている。RNNで構成される。
RNN エンコーダ-デコーダ
seq2seqを用いて、エンコーダとデコーダで出力も時系列にする手法。エンコーダでは入力される時系列データから固定長のベクトル、デコーダでは固定長のベクトルから時系列データを生成する。
Attention
RNNの応用により様々な時系列タスクで高い精度を達成するようになったが、RNNは1つ前の状態と新たな入力から次の状態を計算するだけであり、どの時点の情報がどれだけ影響力を持っているかまではわからないという問題がある。そこで「時間の重み」をネットワークに組み込んだのがAttentionと呼ばれる機構。Attentionは「過去の入力のどの時点がどのくらいの影響を持っているか」を直接計算して求める手法であり、時系列タスクで精度の向上に多大に貢献している。
トランスフォーマー(Transformer)
RNNの欠点として「並列計算ができず、処理速度が遅いこと」と、「先頭に読み込んだデータの影響が時間ともに薄れていくため、入力データの長さが長くなると遠く離れた単語間の関係が捉えきれない」がある。これらの問題を解決した新たなNN構造として、2017年に提案されたのがトランスフォーマー。
RNNの構成はエンコーダとデコーダをAttention機構により橋渡ししてもらうような構造で、この橋渡しに使うAttention機構はSource-Target AttentionもしくはEncoder-Decoder Attentionと呼ばれる。トランスフォーマーはエンコーダとデコーダをRNNから排除し、代わりにSelf-Attentionを採用しているのが最大の特徴。Self-AttentionとSource-Target Attentionの2種類のみの構成により並列計算が高速に行えるようになり、Self-Attentionにより遠い位置の単語関係も上手く捉えるようになった。
Source-Target Attention
入力(Query)と索引(Memory)が別物の場合のAttention。
Encoder-Decoder Attention
ソース系列をEncoderと呼ばれるLSTMを用いて固定長のベクトルに変換(Encode)し、Decoderと呼ばれる別のLSTMを用いて、ターゲット系列に近くなるように系列を生成するモデル。
Self-Attention
データの流れ方自体を学習して決定するモデル。入力分内の単語間または出力文内の単語間の関連度を計算したもので、入力文内の全ての単語間の関係を1ステップで直接計算することが可能。位置エンコーディング(positional encoding)と呼ばれる単語の出現位置に固有の情報を入力に付加し、ニューラルネットワークは間接的に単語の位置情報や単語間の位置関係を考慮することができる。他の単語との分散表現とSelf-Attentionの値との考慮をして自身の分散表現を更新することで、その文における文脈を考慮したより適切な分散表現を得られる。
トランスフォーマーではエンコーダもデコーダもSelf-Attentionも用いているが、「デコーダがSource-Target Attentionにより入力文の情報を利用する」、「エンコーダでは入力文の全ての単語を見ながら計算を行うが、デコーダでは先頭から順に出力を生成するためまだ出力していない未来の情報は使えない」という点で仕組みの違いがある。
自然言語処理におけるPre-trained Models
自然言語処理分野においても事前学習+転移学習という枠組みで様々な応用タスクを高精度に解くことができるモデルが2018年に提案されており、その先駆者としてGPTとBERTがある。これらは事前学習と同じモデルを使って応用タスクを解けるという特徴がある。
一方で、word2vecやELMoも事前に大規模なデータを使って学習しているという点では共通しているが、単体では応用タスクは解くことができず別のNNが必要になる。そのため、事前学習モデルと言ったらword2vecやELMoは含まず、GRTやBERTのことを指すのが一般的。
GPT(Generative Pre-Training)
2018年にOpenAIが提案した事前学習モデル。大規模なコーパスを用いた言語モデルの学習を行い、トランスフォーマーのデコーダに似た構造をもったネットワークを用いている。言語モデルという性質上、将来の単語の情報を使うことができないのでデコーダの構造のみを用いている。エンコーダがないのでSource-Target Attentionはない。以下のようなタスクを解くができる。
| 自然言語推論 (Natural Language Inference:NLI) | 与えられた2つの文書の内容に矛盾があるか、一方が他方を含意するかなどを判定するタスク。含意関係認識(Recognizing Textual Entailment、RTE)ともいう。 |
| 質問応答 (question answering) | 文書とこれに関する質問が与えられ、適切な回答を選ぶタスク。しばしば常識推論(commonsensereasoning)が必要となる。〈実装〉 |
| 意味的類似度 (semantic similarity) | 判定と2つの文が与えられ、これが同じ意味であるか否かを判定するタスク。 |
| 文書分類 (document classification) | 与えられた文書がどのクラスに属するかを予測するタスク。評価分析も文書分類の一種である。〈実装〉 |
GLUE(General Language Understanding Evaluation)
上の4つのようなタスクは文書の内容や背景まで正確に理解していないと高精度に解けないため、一般的に言語理解タスクと呼ばれる。言語理解タスクをまとめた汎用的な言語処理理解評価(ベンチマーク)のためのデータセット。
BERT(Bidirectional Encoder Representations from Transformers)
Google社が開発した双方向Transformerを使ったモデルで、性能が高く様々な言語処理で使用されており、2019年にGoogle検索に導入されている。ラベルなしのデータを大量に事前学習させて、処理させたデータに少量のラベルありデータを使用することで課題に対応させる。
BERTではMasked Language Model(MLM)とNext Sentence Prediction(NSP)という2つのタスクにより事前学習を行う。未来から現在までも合わせて両方向(Bidirectional)の情報を同時に使うことができるため、各単語の最終状態を使い品詞タグ付けや固有表現解析を行ったり、SQuADのような回答の範囲を予測するタイプの質問応答タスクを解いたりすることも可能。
BERTの進化版としてERNIE、XLNet、RoBERTa、ALBERTなどある。
MLM(Masked Language Model)〈実装〉
文中の単語の一部をマスクして見えないようにした状態で入力し、マスクされている単語を予測させるタスク。
NSP(Next Sentence Prediction)
2つの文を繋げて入力し、2つの文が連続した文かどうかを判定するタスク。
事前学習モデルの最近の発展
GPTとBERTが登場してからまだ数年だが、次々と高精度なモデルが登場している。
パラメータ数は年々増加しており、GPTのパラメータ数は約1億、BERTは約3億にもなる。
| ALBERTとDistiBERT | この2つのモデルはタスクの精度を落とさずにパラメータ数を削減する工夫をしたモデル。 |
| GPT-2 | GPTの後継にあたり、2019年2月に登場。パラメータ数を増やして精度を向上させたモデルで約15億パラメータをもつ。GPTでは行えなかった機械翻訳や言語生成タスクもおこなるようになった。 |
| Megatron-LM | 2019年9月にNVIDIAから提案されたモデルで約83億のパラメータ数をもつモデル。 |
| Turing-NLG | 2020年2月にMicrosoftから提案されたモデルで約170億のパラメータ数をもつモデル。 |
| GPT-3 | 2020年5月にはGPTの最新モデルであり、パラメータ数は約1750億にまで巨大化した。GPT-3を使うと言語生成タスクで非常に高精度に行えると話題になっている。 |
| ViT(VisionTransformer) | トランスフォーマーが画像処理分野に持ち込まれ、CNNを使わない新たな事前学習モデルViTも提案されている。〈実装はこちら〉 |
Vision Transformer〈実装はこちら〉
2021年はVision Transformerが話題となった。これは自然言語用に設計されたTransformerを画像分野に応用するという試み。自然言語処理では穴埋め問題で学習するが、これを画像に応用することでジグゾーパズルを組み立てるかのように画像の穴埋めを行う。
LDA(Latent Dirichlet Allocation)
文中の単語から、トピックを推定する教師なし機械学習の手法。ディレクトリ分布という確率分布を用いて、各単語から」隠れたあるトピックから生成されているものとしてそのトピックを推定する。
LSI(Latent Semantic Indexing)
文章ベクトルにおいて複数の文章に共通に現れる単語を解析することによって、低次元の次元の潜在意味空間を構成する方法。ある行列を複数の行列の積で表現する行列分解の一つである特異値分解が用いられれる。
6.5 深層強化学習分野
キーワード
深層強化学習の基本的な手法と発展、深層強化学習とゲーム AI、実システム制御への応用、DQN、ダブル DQN、デュエリングネットワーク、ノイジーネットワーク、Rainbow、モンテカルロ木探索、アルファ碁 (AlphaGo)、アルファ碁ゼロ(AlphaGo Zero)、アルファゼロ (Alpha Zero)、マルチエージェント強化学習、OpenAI Five、アルファスター (AlphaStar)、状態表現学習、連続値制御、報酬成形、オフライン強化学習、sim2real、ドメインランダマイゼーション、残差強化学習
深層強化学習の基本的な手法と発展
強化学習では環境と学習目的を設定する。環境は状態、行動、報酬、遷移確率を内包する。エージェント(学習主体)は
「状態」に対する最適な「行動選択」を学習し、行動選択の結果、エージェントは「報酬」を得る。学習目的に近づく
「行動選択」であったのかを「報酬」に基づき改善する。エージェントがもつ行動選択のルールのことを「方策」という。
強化学習では「一連の行動」に対する報酬の最大化を目指す。
Q学習 (Q値=価値関数)
TD学習の1つでQ値(価値関数)ベースの強化学習法。ある特定の状態に対して1つの行動価値(Q値)を割り当てて、その行動価値に対する学習を行う。実行するルールに対しそのルールの有効性を示すQ値という値を持たせ、エージェントが行動するたびにその値を更新する。ここでいうルールとはある状態とその状態下においてエージェントが可能な行動を対にしたものである。
ε-greedy方策
Q学習などで用いられる方法。「探索:ランダムに行動を選ぶ」・「活用:報酬平均が最高な行動を選ぶ」の繰り返しで探索と活用のバランスを取りながら累積報酬の最大化を目指す(探索と活用のトレードオフ)。εがハイパーパラメータなのでこれをうまく調節するのが難点。探索が行われる確率が固定されているのでいつまで経っても探索がランダムに起きる問題がある。
SARASA
TD学習の1つで状態S'のQ関数のうち、最大の値をもつQ関数Q(S',a^*)が用いられる。
| モデルベース | 環境に対する情報が完全(即知)である場合に適応できる方法。 |
| モデルフリーの方策ベース | パラメトリックな関数で表現する。 |
| モデルフリーの価値関数ベース | 報酬の期待値を状態や行動の価値計算に反映する。 |
状態遷移や報酬を予測する関数を環境モデルと呼ぶことがある。
| モデルベース | 環境モデルを利用できる場合 | Alpha Zero、世界モデル |
| モデルフリー | 環境モデルを利用しない場合 | Q学習と方策勾配法 |
深層強化学習
強化学習にディープラーニングを組み合わせた手法は深層強化学習と呼ばれる。深層強化学習はニューラルネットワークを用いて、状態の重要な情報のみを縮約表現することで、状態や行動の組み合わせが多い学習を可能にした。DQNを使用したAtari2600は様々なゲームで人間を超えるスコアを出した。
DQN(Deep Q-Network)
DeepMind社が開発した深層強化学習で、Atari社が開発した家庭用ゲーム機Atari2600の多様他種なゲームを人間並み、または人間以上のスコアで攻略できることが示され深層強化学習が注目を浴びるきっかけになった。従来のQ学習では、ある特定の状態に対して1つのQ値を割り当てて、その行動価値に対する学習を行なっていたが、ゲームや実世界の画像をそのままディープニューラルネットワークの入力とし、行動候補の価値関数や方策を出力として学習するというアプローチをとる。DNNをCNNにすることで、入力の画像から価値推定に必要な情報を上手く処理できる。DQNでは、経験再生とターゲットネットワークという新しい学習方法が導入されている。
| 経験再生 (expreience replay) | 経験再生は、環境を探索する過程で得た経験(データ)をリプレイバッファに保存し、あるタイミングでこれらの保存データをランダムに複数抜き出してDNNの学習に使う手法。学習に使うデータの時間的偏りを失くし、学習の安定化を図っている |
| ターゲットネットワーク | 現在学習しているネットワークと学習の時間的差分がある過去のネットワークに教師のような役割をさせる手法で、価値推定を安定させる。 |
DQNの拡張手法
| DDQN (ダブルDQN)(double deep q-network) | DQNにおけるTargetデータを改良した手法で。DDQNでは、行動価値関数(Q値)に対して、価値と行動を選択するニューラルネットワークと、その行動を評価するニューラルネットワークの 2 つに役割を分ける。これによって、通常のDQNの計算では行動価値の推定が過大評価されてしまうという問題に対して対応することが出来る。DDQNの計算では過大評価な推定を抑えて、より正確に推定することが可能になる。DQNはたまたまQ値が高いところを学習してしまう場合があり、それを防ぐ手段にDQNを二重化したダブルDQNがある。 |
| PER (優先度付き経験再生) (prioritized experience replay) | 経験再生の使い方を工夫したモデル。オリジナルのDQNではReplayBufferに蓄積した遷移情報からのランダム選択によってミニバッチを作成する。遷移情報をランダムに選択するのでは思いがけず上手くいったような貴重なイベント(遷移)を学習する効率が悪いのでPER(優先度つき経験再生)では、意外性の高い遷移を優先してReplayBufferからサンプリングする。 |
| デュエリングネットワーク(dueling network) | 普通のQ-networkは、状態を入力として受け取り、SeaquentialなNetworkを通して行動価値関数Q(s,a)を予測する。それに対しDueling-networkでは、状態を入力として受け取り、途中で状態価値関数V(s)とAdvantage( A(s,a) = Q(s,a) - V(s) )の二つの流れに別れた後、最後に足し合わせることで行動価値関数Q(s,a)を予測する。 |
| カテゴリカルDQN(categorical deep q-network) | カテゴリカルDQNでは行動価値の期待値(平均値)ではなく、分布を計算する。行動価値の分布の分散が大きい場合には平均値以外の値を受けるリスクが高くなる。ターゲットネットワークQとQネットワークの両方とも分布を出力するので、交差エントロピーを計算し誤差逆伝播をする。それ以外は他のDQNと仕組みは同じで、基本的に行動価値の期待値が最大になるように行動を選択する。 |
| ノイジーネットワーク (noisy network) | DQNを含むQ学習ではε-greedy法によってランダムに行動選択する探索の要素を取り入れている。これは初めから行動価値が高いものだけを選ぶと別の行動を取る可能性がなくなり十分な探索が行えないためであり、ノイジーネットワークでは探索を行うためにネットワークの重さ自体に正規分布からくる乱数を与えている。学習可能なパラメータによってネットワークは必要に応じて乱数の大きさをコントロールできる。よって、DQNやその他の派生DQNに適用すればε-greedy法を使う必要がなくなり、常に最高価値の行動を選ぶことで必要に応じて探索行動を取れるようになる。 |
| Rainbow | Rainbowは上述したDQNとその派生の全て(7種類あるのでレインボー)を組み合わせたもので、性能が飛躍的に上がっている。Rainbow以降も複数のCPUやGPUを使い学習を行う分散強化学習によって学習の収束速度が飛躍的に向上している。内発的報酬(intrinsic reward)と呼ばれる報酬の工夫により、極めて難易度の高いゲームにおいても人を超えるパフォーマンスを発揮する手法が発表されている。内発的報酬は赤ん坊の好奇心の自発的に生じる報酬を強化学習に取り入れたもの。 |
Agent57
DQNを開発したDeepMindの強化学習の研究はさらに進み、内発的報酬や記憶能力を加えてさらに発展した。2020年に発表されたAgent57はDeepMindにおける強化学習の成果を集結したもので、Atari2600の全てのゲーム(57個)で人間のスコアを初めて上回ることができた深層強化学習モデル。
深層強化学習とゲームAI
| ゼロ和性 | 一方が勝てば他方が負ける。 |
| 2人完全情報確定ゼロ和ゲーム | 偶然の要素がない確定性という性質を満たすゲームはゲーム木を全て展開することで必勝法を見つけられる。これを現実的な時間で行うのは不可能であるため、効率化する手法が必要。 |
| モンテカルロ木探索 | 複数回のゲーム木の展開によるランダムシミュレーション(プレイアウト)をもとに近似的に良い打ち手を決定する手法。 |
AlphaGo Fan
AlphaGoの初代バージョン。2015年10月、コンピュータ囲碁として初めてプロ棋士に勝利を収めた。
AlphaGo
2016年DeepMind社が開発した囲碁AIで、世界的なトップ囲碁棋士であるイ・セドル九段に囲碁で勝利。モンテカルロ木探索と深層強化学習を組み合わせている。人間の棋譜データを使った教師あり学習や、複製したAlphaGoとの自己対戦で得た経験を使い深層強化学習を行なっている。
打ち手の評価:盤面から勝率を計算するバリューネットワークや、ポリシーネットワークと呼ばれるディープニューラルネットワーク
AlphaGo Zero
2017年10月に発表されたAlphaGoの発展系。人間の棋譜による教師あり学習は一切行わず自己対戦によるデータのみで深層強化学習を行なっている。プロの棋譜を使わず、ゼロからの自己対戦のみにも関わらず、AlpaGoを上回る強さ。5000台のTPUを使用している。
Alpha Zero
2018年に発表されたAlpha Goの完成形のゲームAI。自己対戦のみで囲碁だけでなく、将棋やチェスでもトッププレイヤーを圧倒する性能に到達している。
AlphaStar
2019年1月に公開されたビデオゲームStarCraftIIをプレイするコンピュータープログラム。人工知能の重要なマイルストーンとして、AlphaStarは2019年8月にグランドマスターのステータスを獲得。
マルチエージェント強化学習(Multi-Agent Reinforcement Learning : MARL)
単一エージェントではなく、複数のエージェントによる強化学習。
マルチエージェント強化学習を用いた代表的なゲームAIに以下の2つがある。
| OpenAI Five | 2018年。OpenAIは、MOBA(Multiplayer Online Battle Arena)と呼ばれる多人数対戦型ゲームDota2において、世界トップレベルのプレイヤーで構成されるチームを打倒できるゲームAI。ディープニューラルネットワークに、系列情報を処理するLSTMを使い、PPOと呼ばれる強化学習のアルゴリズムを使って極めて大規模な計算資源で学習した5つのエージェントのチームによって、世界トップレベルのプレイヤーに勝利を収めた。5万個以上のCPUと1000個以上のGPUを使用して10ヶ月に及ぶ強化学習を行った。 |
| AlphaStar | 2019年。DeepMind社は、RTS(Real-Time Strategy)と呼ばれるゲームジャンルに属する対戦型ゲーム、スタークラフト2において、グランドマスターという称号を持つトッププレイヤーを打倒できるゲームAI。 AlphaStarは、ResNet、LSTM、Pointer Network、トランスフォーマーなど画像処理や自然言語処理の手法も多く取り入れたネットワークを使って学習。強化学習時にはゲーム理論や、自己対戦の発展系の手法を使うなど、様々な人工知能技術が巧みに組み合わされて構成されており人工知能技術の集大成的なアルゴリズム。 |
次元の呪い(curse of dimensionality)
状態や行動の数が指数的に増大するため学習が困難になること。
状態表現学習(state representation learning)
問題に対して適切な方策を学習できるように、エージェントは入力となるセンサデータから「状態」に関する良い特徴表現を学習する手法。
連続値制御(continuous control)
連続値の行動を直接出力する問題設定。
事前知識(ドメイン知識、domain knowledge)
オンラインのアルゴリズムであり、エージェントが学習過程で環境内で実際に試行錯誤して方策を獲得する枠組み。
模倣学習(imitation learning)
人間が期待する動作をロボットに対して教示することで、ロボットが方策を学習する問題設定。教示データはデモンストレーションと呼ばれる。
sim2real
シミュレータで学習した方策を現実世界に転移して利用する設定。リアリティギャップ(reality gap)と呼ばれる現実世界とシミュレータで再現された世界の間の差異が生まれるため、学習した方策を実世界に転移した際、性能を低下させる大きな原因になることがある。
ドメインランダマイゼーション(domain randomization)
ランダムに設定した複数のシミュレータを用いて生成したデータから学習することでsim2realの課題解決に貢献。
残差強化学習(residual reinforcement learning)
従来のロボット制御で用いられてきたような基本的な制御モジュールの出力と、実際にロボットがタスクを行う環境における最適な方策との差分を強化学習によって学習することを目指す。与えられたタスクに対して不完全な制御方策が得られている場合を想定し、与えられた初期方策を改善していくことで、少ない試行回数で適切な方策を獲得することを実現する。
モデルベース(model-based)強化学習
環境に関する予測モデルを明示的に活用しながら方策の学習を行う強化学習アルゴリズム。
世界モデル(world model)
エージェントが得られる情報を元に自身の周りの世界に関する予測モデルを学習して、方策の学習に活用する枠組み。
6.6 モデルの解釈性とその対応
キーワード
ディープラーニングのモデルの解釈性問題、Grad-CAM、モデルの解釈、CAM
ディープラーニングモデルの解釈性問題
ディープラーニングのモデルは予測の判断根拠を説明するのが苦手。
Grad-CAM
Attentionは予測精度向上のための手法がそのまま可視化に応用できるというものだが、可視化自体を目的としたGrad-CAMという手法も存在する。これは画像認識系のタスクを対象に、モデルの予測判断根拠を示すために、「画像のどこを見ているか」を可視化する。勾配情報を用いて勾配が大きい箇所が出力値への影響が大きいピクセルが重要だと判断して重み付けをする。この過程でGrad-CAMは画像が低解像度になってしまうという問題がある。
Guided Grad-CAM
その問題を解決するために、入力値の勾配情報を用いたGuided Grad-CAMという手法も存在する。
6.7 モデルの軽量化
キーワード
エッジ AI、モデル圧縮の手法 蒸留、モデル圧縮、量子化、プルーニング
エッジAI
利用者端末と物理的に近い場所に処理装置を分散配置して、ネットワークの端点でデータ処理を行う技術の総称であるエッジコンピューティングから派生した用語。AIの学習モデルを用いてエッジデバイスで推論することをいう。
モデル圧縮
学習や予測に要する時間を減らすことで、効率的な検証ができるようにすること。
メモリの使用量の削減やパラメータを削減することで計算量を減らす方法がある。
蒸留(distillation)
軽量化の手法の一つ。大きいモデルやアンサンブルモデルを教師モデルとして、その知識を小さいモデル(生徒モデル)の学習に利用する方法。
量子化
近似的にデータを扱うことをいい、情報量を少なくして計算を効率化する方法。
プルーニング
精度の低下をできるだけ低く抑えながら、過剰な重みを排除するプロセス。
7. ディープラーニングの社会実装に向けて
7.1 AIと社会
キーワード
AI のビジネス活用と法・倫理 AI による経営課題の解決と利益の創出、法の順守、ビッグデータ、IoT、RPA、ブロックチェーン
AI利活用の本質はAIによって経営課題を解決し、利益を創出する点にある。ビジネス的成功と技術的成功は車の両輪であり、一方だけを論点とすることはできない。
AIを進めるにあたってはビッグデータが必須であり、人がアナログで行うプロセスを一足跳びにAIに置き換えようとするのは間違った方法論といえる。AI化を進めていくにはIoTやRPAを活用し、アナログ空間で発生している状況をデジタル空間に送る状況を作る必要がある。デジタル空間では簡単に編集できるので、それを保護するブロックチェーンもあわせて必要となる場合もある。
| 順序 | AIシステム利活用のサイクル |
|---|---|
| ① | AIプロジェクトを計画する |
| ② | データを集める |
| ③ | データを加工、分析、学習させる |
| ④ | 実装、運用、評価する |
| ⑤ | クライシスマネジメントをする |
IoT(Internet of Things)
様々なモノがインターネットに接続されて相互に制御する仕組みのこと。
RPA(Robotic Process Automation)
人間が繰り返し行う定常作業を自動化する技術。
ブロックチェーン
分散型ネットワークを構成する複数のコンピューターに暗号技術を組み合わせ、取引情報などのデータを同期して記録する手法。

7.2 AIプロジェクトの進め方
キーワード
AI プロジェクト進行の全体像、AI プロジェクトの進め方、AI を運営すべきかの検討、AI を運用した場合のプロセスの再設計、AI システムの提供方法、開発計画の策定、プロジェクト体制の構築、CRISP-DM、MLOps、BPR、クラウド、WebAPI、データサイエンティスト、プライバシー・バイ・デザイン
CRISP-DM(Cross-Industry Standard Process for Data Mining)
6つのフェーズから構成されるデータマイニングのための業界横断型標準プロセスのこと。効率よく試行錯誤できるよう、6つのステップを臨機応変に行ったり来たりする。2015年に、IBMは新しいプロセスとしてCRISP-DMを拡張したASUM-Dを発表した。
| 要素 | CRISP-DM |
|---|---|
| Business Understanding | ビジネス理解 |
| Data Understanding | データの理解 |
| Data Preparation | (データの準備) |
| Modeling | モデリング手法の選択、モデルの作成 |
| Evaluation | 結果の評価、プロセスの見直し、次のステップの計画 |
| Deployment | 本番環境への展開 |
MLOps(Machine Learning Operations)
機械学習オペレーションの略で2017年頃に登場した概念。AIの課題の1つに「モデルを開発する側」と「それを運用する側」とが必ずしも円滑に連携できるとは限らないことがあることから誕生した概念。機械学習の開発担当と運用担当が連携しながらモデルの開発から運用までの一連を管理する体制を目指しており、MLOpsの概念は開発(Development)と運用(Operation)の両チームの協業を目指すDevOpsという概念を、機械学習(ML)の分野に適用したことから発祥した。
AIを適用すべきかの検討
AIは目的ではなく手段であることから特性を理解した上でAIを運用する必要性を検討する。利活用による利益予測を立て投資判断を行う。最初はルールベースでも良く、データのフィードバックによって継続的にAIが学習できるようにビジネス上も技術上も準備する。運用を継続しながら推論精度を上げていくという現実的な進め方をする必要がある。
推論精度を100%を前提としたビジネスモデルを構築すると、多くの場合うまくいかないが多い。実務上期待できる推論精度を前提として、どう活かすかを検討するのが大切。
BPR(Business Process Re-engineering)
業務・組織・戦略を根本的に見直し再構築すること。現在の社内の業務内容やフロー、組織の構造などを根本的に見直し再設計すること。
AIシステムの提供方法
AIシステムは「納品」よりも「サービス」の提供として運用するのが向いている。クラウド上でWebAPIとしてサービス提供する方式や、エッジデバイスにモデルをダウンロードし、常に最新の状態となるように更新を続けるという方式がある。
| メリット | デメリット | |
| クラウド | ・モデルの更新が簡単 ・装置の故障がない ・ハードウェアの保守・運用が不要 | ・通信遅延、サーバーの故障が全てに影響(通信影響が大きい) ・ネットワークがダウンしたら動かない(ダウン時の影響が大きい) ・データのプライバシー |
| エッジ | ・スピードが速い(リアルタイム性が高い) ・通信量が少ない ・故障の影響範囲が小さい | ・モデルの更新が難しい(手間がかかる) ・ハードウェアの保守・運用が必要(機器を長期間保守運用するひち右葉がある) |
Web API
ネットワーク越しにシステム間で情報を受け渡す仕組み。クラウドをはじめとしたコンピューティングリソース上にモデルを置いて利用できるようにすることをデプロイという。
開発計画の策定
教師データを作るには欲しい出力を定量化する必要があるが、熟練工の技などは定量化が難しい可場合が多い。AIのプロジェクト管理は細かくフェーズ(データを確認する段階、モデルを試作する段階、運用に向けた開発をする段階)を分け、モデルの精度に応じて柔軟に方針を修正できる体制が望ましい。
プロジェクト体制の構築
AIシステムの開発段階から様々なステークホルダーを含めた体制作りが重要であり、ビジネス観点のあるマネージャー・UIやUXを担当するデザイナー・AIモデルを開発するデータサイエンティスト・法的・倫理的な課題を検討するために開発段階から経営者・法務・経営企画・広報間との連携も重要となる。
開発段階から以下のようなことを念頭に入れて体制を整える。
| Privacy by Design (プライバシー・バイ・デザイン) | 開発段階からプライバシー保護、プライバシー侵害を予防する考え方。 |
| Security by Design (セキュリティ・バイ・デザイン) | 開発段階からセキュリティを考慮する考え方。 |
| VAlue Sensitive Design (バリュー・センシティブ・デザイン) | 開発段階から価値全般に拝領する考え方。 |
民間企業のAI開発時に用いられる契約の1つに準委任契約があり、特にシステム開発における一部の開発を委任する場合はSES契約という。
アジャイル開発
従来のソフトウェア開発では演繹的な工程であり、AIのソフトウェアは帰納的に開発される。汎化性能の保証が原理的に難しく、不具合の原因の特定や切り分けが難しいため、クライアントに要求を満たすモデルを開発できるかどうか事前に判断することは難しい。そのため従来のソフトウェア開発のようなウォーターフォール開発ではなく、アジャイル開発を用いることが一般的となっている。
| ウォーターフォール開発 | 最初に全体の機能設計・計画を決定し、この計画に従って開発・実装していく手法 |
| アジャイル開発 | おおよその仕様と要求を決定後に「計画」・「設計」・「実装」・「テスト」といった開発工程を機能単位の小さいサイクルで繰り返す |
SES契約(システムエンジニアリング契約)
SES契約とは、準委任契約、業務委託、タイマテとも呼ばれる契約形態で、エンジニアの能力を契約の対象とした手法。エンジニアを雇用する時間に対して報酬を支払う形態になる。「作業時間についてのみ報酬が発生し、成果物に対しての責任は一切発生しない」という点がSES契約の最大のポイントであり、エンジニアが作り上げた成果物に対して報酬を支払う請負契約とは大きく異なる。民間企業でAIを開発する際に用いられる契約の1つに準委任契約がある。
7.3 データの収集
キーワード
データの収集方法および利用条件の確認、法令に基づくデータ利用条件、学習可能なデータの収集、データセットの偏りによる注意、外部の役割と責任を明確にした連携オープンデータセット、個人情報保護法、不正競争防止法、著作権法、特許法、個別の契約、データの網羅性、転移学習、サンプリング・バイアス、他企業や他業種との連携、産学連携、オープン・イノベーション、AI・データの利用に関する契約ガイドライン
データの収集方法および利用条件を確認
AIシステムの開発にはデータの量と質が重要となる。データの収集方法には以下のようなものがある。
| オープン データセット | 企業や研究者が公開しているデータセット。利用条件が決められている場合もあるが、本来高いコストで集めないといけないような大量のデータが利用可能で、適切に使えばプロジェクトを早く進められる。 画像分野 : ImageNet, PasaIVOC, MS COCO 自然言語 : WordNet、SQuAD、DBPedia 音声分野 : LibriSpeech |
| 自分で集める | カメラなどのイメージセンサ、マイクロフォン、3DセンサなどプロジェクトのROIを考慮してのデータ収集・蓄積が必要。人間の知覚とセンサは違うので、知覚をセンサで置き換える場合はよく検討する。また、センサには人間の知覚にない特性もある。3Dセンサ、X線センサ、赤外線センサ、 電波計測器、超音波計測機、 重量計、 聴力センサなどがある。 |
| 購入 | 販売されているデータセットを購入。 |
法令に基づくデータ利用条件
データの利用条件に気をつける必要がある。
| 著作権法 | 論文や写真などの著作物を利用するには、著作権者から許諾を得るのが原則だが、学習用データ作成については一定要件のもと自由に使える例外規定がある。「情報解析の用に供える場合」に著作物を利用することが、営利・非営利を問わず適法とされており、世界的に見ても先進的と言われている。ただし、「著作権物の利益を不当に害する」場合はその限りではない。 |
| 不正競争防止法 | 平成30年の改正で、一定の価値あるデータの不正な取得行為や不正な使用行為等、悪質性の高い行為に対する民事措置(差止請求権、損害賠償額の推定等)が規定された。営業機密にあたるデータや限定提供データ。 |
| 個人情報保護法等 | ・購買履歴や位置情報などのパーソナルデータ。 ・生存する個人の情報が対象となり、すでに死亡した方の個人情報は含まれない ・個人を識別できないように加工し、復元不可能にした匿名加工情報は本人の同意がなくても第三者に提供できる。 ・指紋や声紋は個人情報として扱われる。 ・個人情報取扱事業者は営利企業の他にNPO法人や町内会なども対象となる。 |
| 個別の契約 | ライセンス契約で利用条件が指定されているデータ。 |
| そのほかの理由 | Eメールの内容など。 |
| 特許法 | AIが発明をした場合の取り扱いについては現状は規定がない。 |
「金融分野における個別情報保護に関するガイドライン」では、機微情報について取得・利用・第三者提供のいずれも原則禁止とされており、個人情報保護法における要配慮個人情報の取扱い原則よりも厳しい規律となっている。
不正競争防止法
営業秘密データの保護、限定提供データて押しての保護が必要となる。不正競争防止法における営業秘密とは①秘密管理性(社内で秘密データとして管理されているもの)、②有用性(事業のために有用な情報であること)、③非公知性(一般に知られている情報でないこと)の3つ。
不正競争防止法等の改正によって、データの利活用を促進するための環境が整備される。主要な措置事項として、IDやパスワードなどにより管理しつつ相手方を限定して提供するデータを不正取得するなどの行為を新たに不正競争行為に位置づけている。
著作権法
著作権保護法の対象となる著作物として思想または感情を創作的に表現したものであって、文芸、学術、美術または音楽の範囲に属するものがある(著作権法2条1項1号)
特許法
発明は「自然法則を利用した技術的思考の創作のうち高度なもの」と定義されている。29条1項では特に産業上利用することができるものであり、新規制、進歩性などの要件を満たしたものに特許が付与されると規定されている。次世代知財システム検討委員会報告書(2016年 4月)では現行の法制度上では人工知能が自律的に生成した発明については特許の対象ではないと解釈している。特許の要件には新規性・進歩性が必要要件。
例外規定
学習用データの作成については一定の要件のもと自由に行える(著作権法30条の4)
著作権法がOKでも他の規定の制約
営業秘密にあたるデータ(不正競争防止法2条6項)、限定提供データ(不正競争防止法2条7項)、購買履歴や位置情報などのパーソナルデータ、ライセンス契約で利用条件が指定されているデータ、「通信の秘密」にあたるEメールの内容、憲法21条2項・電気通信事業法4条)など
学習可能なデータの収集
訓練データを収集する際の留意点。
| データの偏りをなくす | オープンデータセットのように大量のデータなら多少偏りがあろうともある程度の精度が上がるかもしれないが、自身でデータを集める場合など、十分な量のデータを集めるのが難しい場合など、その偏りはクリティカルなものになる。 |
| データの網羅性 | 転移学習などを利用したら、ある程度はデータの数が少ない状況に対する精度が保証はされるが、十分な制度の確保は難しい。可能な限り広い状況を網羅できるようにデータを準備しておく必要がある。 |
| データの質 | データ内に認識に必要となる情報がノイズで殆ど消えていたり、そもそも含まれていなかったりすると、そこからの学習は難しくなる。 |
サンプリングバイアス
選択バイアスとも呼ばれ、不適切な標本抽出によって母集団を代表しない特定の性質のデータがまぎれこんでいることで、現実世界の偏見をそのまま反映してしまうこという。データやアルゴリズムのバイアスに関して検証するためにもシステムの透明性(transparency)や説明責任・答責性(accountability)が開発側に求めれれている。
| データがそもそもデータベースに登録されていない事による偏り | レイプや強盗、膀胱などの6割が警察に通報されていないため、データベースに登録されていないと言われている。その状態で犯罪予測を作ったとしても、その信頼性は疑問視されてしまう。 |
| 欧米主導の共有データセットが学習に使われる | 画像認識において「baby」や「family」と検索するとアングロサクソン系の画像ばかりが表示され、アジア系やアフリカ系が表示されないと指摘されたことも。 |
| 人種・性別・学歴などへ偏見 | 優秀な社員を判断するAIを人事評価に用いて、学歴や性別などの偏見(バイアス)が潜在したまま継承されてしまう恐れや、犯罪者の再販リスクを予測するAIではアフリカ系の人をより高く再販すると予測する例がある。 |
オープン・イノベーション
他企業や他業種と連携、産学連携が増えてきた理由はデータを保有する組織、データ分析やアルゴリズム開発に優れた組織、分析結果やアルゴリズムを利用してビジネス展開する組織がそれぞれ一致しないためである。そこで、オープン・イノベーションにより企業間のコンソーシアムや、産学連携、企業の共同開発を通じて、社会的なインパクトを生むことを指す。留意点として、「学習や推論の結果、生成される学習済みモデルの性質、効果が契約時に不明瞭な事が多い」、「学習済みモデルの性質や効果が学習用データセットによって左右されること」、「ノウハウの重要性が高いこと」、「生成物について再利用の需要が存在すること」がある。
AI・データの利用に関する契約ガイドライン 詳細リンク
経済産業省は、AI・データ契約ガイドライン検討会を設置し、2018年に「AI・データの利用に関する契約ガイドライン」を策定、2019年に改訂版(ver.1.1)を公表。開発プロセスを①アセスメント段階、②PoC段階、③開発段階、④追加学習段階に分けて、それぞれの段階で必要な契約を結んで行くと、試行錯誤を繰り返しながら納得できるモデルを生成するアプローチがしやすくなるとしている。
| アセスメント段階 | モデルの生成可能性を検証(目的)、レポート等(成果物)、秘密保持契約所等(契約) |
| PoC段階 | ユーザが求める精度のモデルが生成できるか検証(目的)、レポートやモデル(成果物)、導入検証契約書(契約) |
| 開発段階 | 学習済みモデルの生成(目的)、学習済みモデル(成果物)、ソフトウェア開発契約書(契約) |
| 追加学習段階 | 追加の学習データで学習をする(目的)、再利用モデル(成果物)、保守運用契約書や学習支援契約書(契約) |
契約類型は「データ提供型」「データ創出型」「データ共有型」の3つで、それぞれ利用権限や範囲が異なる。
| データ提供型 | データを譲渡し利用を許諾する。契約で利用権限などを取り決める。 |
| データ創出型 | データの創出に関与した複数当事者間で利用権限を取り決める。 |
| データ共有型 | プラットフォームを利用したデータの共有。 |
AI・データの利用に関する契約ガイドラインは①データの利用等に関する契約、及び②AI技術を利用するソフトウェアの開発・利用に関する契約の主な課題や論点、契約条項例、条項作成時の考慮要素等を整理したガイドライン。
AI の作成・利活用促進のための知財制度の在り方
日本政府は2017年に新たな情報財検討委員会報告書を公表しており、報告書の中で「AI の作成・利活用促進のための知的財産権の在り方」として様々な議論を行っている。そこでは『機械学習に関する「学習用データ」、「AI のプログラム」、「学習済みモデル」、「AI 生成物」を具体的な検討対象として、これらの作成・利活用促進のための知財制度の在り方について、検討することが必要である』と報告されている。
7.4 データの加工・分析・学習
キーワード
データの加工、プライバシーの配慮、開発・学習環境の準備、アルゴリズムの設計・調整、アセスメントによる次フェーズ以降の実施の可否検討、アノテーション、匿名加工情報、カメラ画像利活用ガイドブック、ELSI、ライブラリ、Python、Docker、Jupyter Notebook、 説明可能、AI (XAI)、フィルターバブル、FAT、PoC
アノテーション
アノテーションとはあるデータに対する正解データ(メタデータ)を付与すること。教師あり学習では、アノテーションを作成する必要があり、①アノテーション定義が曖昧、②アノテーションを人間が行う場合の個人差・感性の違い、③専門的な知識が必要な場合の人材確保、④認知容量を超える規模(手作業・人間の能力や人的コストの限界)、⑤不注意によるミスといった課題がある。
アノテーションの要件をできるだけ明確にし、適切な人材に作業を分配し、レビューをプロセスに組み込むことが重要となるため、要件などはマニュアルを作ってサンプルを提示するなど、作業をできる限り明確化しておくと良い。大量のデータを扱う際は外部に委託するのも選択肢に入れておく。
匿名加工情報
特定の個人を識別することができないように個人情報を加工し、当該個人情報を復元できないようにした情報のこと。個人識別符号の削除、匿名加工情報の加工方法等情報の漏えい防止、特定の個人を識別することができる記述等の全部又は一部の削除などがある。
匿名加工情報であれば、一定の条件下で本人同意なく事業者間でやりとりが可能となる(個人情報の保護に関する法律第2条)。匿名加工情報として扱うには「特定の個人を識別すること及びその作成に用いる個人情報を復元することができないようにするため」加工を行う義務がある(個人情報の保護に関する法律第36条)。
匿名加工情報を事業者が作成する際に実施する例として、「個人識別符号の全てを削除」、「匿名加工情報の加工方法等情報の漏えい防止」、「特定の個人を識別することができる記述等の全部又は一部の削除」がある。
ELSI(Ethical, Legal and Social Implications)
科学技術が及ぼす論理的・法律的・社会的な影響を一体化して検討する試みで、特にゲノミクスとナノテクノロジーなど、新興科学の倫理的、法的、社会的影響または側面を予測して対処する研究活動を指す。ELSIで議論される代表的な課題は、AIシステムにおける責任体制。情報セキュリティ、そしてデータ扱いの不正行為の防止にも関わっていく。
カメラ画像利活用ガイドブック
経済産業省・総務省・lot推進コンソーシアムは、カメラ画像を利活用する企業が配慮すべきことなどをまとめた「カメラ画像利活用ガイドブック」を公開。2019年には「事前告知・通知に関する参考事例集」を公表した。2019年には「事前告知・通知に関する参考事例集」を公表し、ベストプラクティスが模索されている。
開発・学習環境の準備
AI開発ではライブラリが豊富なPythonが一番多く使われている。Pythonには多種のライブラリ(様々な機能を簡単に使えるツール群:Numpy、Scipy、Pandas、Scikit-learn、LightGBM、XGBoost、TensorFlow、PyTorchなど)が揃っており、機械学習だけではなく、データの分析やWebアプリケーション開発など様々な事が可能。実装済みのコードがオープンソースとして多数公開されている。
環境を切り替えるツールとして、pyenvやvirtualenv、pipenv、Docker(コンテナ仮想化を用いてアプリケーションを開発・配置・実行するためのオープンソースソフトウェア)などの仮想環境でOSのレベルから環境の一貫性を保つ。
アルゴリズムの設計・調整
AIでは大量のパラメータが自動的に設定されるため、中身がよくわからないブラックボックス化(複雑になりすぎて、どの変数が重要であるかなどシステム全体の説明が困難になる)が問題になることがある。できるだけモデルの判断根拠や解釈が説明できるXAI(explainable AI、説明可能AI)の開発が望まれる。現在は結果の出力だけでなく、そうなった根拠やモデルの解釈まで説明できる説明可能AIであるXAIの開発が進んでいる。XAIは一般に説明可能性とモデルの性能トレードオフの関係にある。
DARPA(the Defense Advanced Research Projects Agency)
2017年7月にカリフォルニア・パロアルトにあるXerox PARC研究所は米国国防先端研究計画局DARPA(the Defense Advanced Research Projects Agency)における説明可能なAI、XAI(Explainable Artificial Intelligence)プログラムに選ばれた。
フィルターバブル現象
おすすめ機能などでも個人の嗜好に偏りすぎるとユーザの視野を狭くしてしまうフィルターバブル現象が生じる。様々な価値を考慮に入れすぎるとチューニングが難しくなるので、技術的な側面と社会的対応などでバランスを取る多面的な手法を検討する。
FAT(fairness, accountability, and transparency)
プライバシーや公平性の問題について取り組む研究領域やコミュニティ。計算機科学の国際学会であるACMが主催するACM FATでは機械学習、法学、社会学、哲学の専門家を交えて様々な研究発表や議論が行われている。
「人間中心のAI社会原則」の基本原則に「AIを利用しているという事実の説明」、「AIに利用されるデータの取得方法や使用方法」、「AIの動作結果の適切性を担保する仕組み」が記載されている。
アセスメントによる次フェーズ以降の実施の可否検討
対象データをいつ・どのように取得するか、同様の問題に関する事例・文献を調査する、運用での推論時間を考慮してモデルを選択するなどのフェーズを経て、最終的にAIを適用すべきか、適用箇所はどこかビジネスインパクトはどうかなどをイメージ・シミュレーションし、当初の目標(精度など)を達成できるか見極める。
PoC(Proof of Concept)
データの加工とアルゴリズムの設計・調整を中心に進め、実際にAIモデルを作成。もしアセスメントフェーズで十分にデータが蓄積されていないようであれば、実験に使う大量のデータの蓄積を行う。次に、ディープラーニングで利用できる形にデータを加工。学習可能なデータが準備できたら、モデルを学習するための学習コードを開発し、パラメータを調整して精度を検証。ここで、データの網羅性の見積もりが不十分であった場合には、一度のデータ蓄積で十分なデータが得られないこともある。精度を検証する中で、どの種の問題に対する精度が低いかを調査し、改めてデータを収集の上で再実験をするといったプロセスを何度か回すことで実用的な精度に近づけていく。精度の向上が難しいなど場合によっては、AIでの認識と人による判断を組み合わせるなどといった工夫を取り入れる。
ライブラリ
機械学習で使用する代表的なライブラリは以下の通り。
| TensorFlow | Googleが開発したpythonのディープラーニング用のライブラリ。 |
| CNTK | Microsoft 社が提供するpythonのディープラーニング用のライブラリ。 |
| Caffe | Berkeley Vision And Learning Center が提供するオープンソースのディープラーニング用ライブラリ。 |
| Chainer | 日本のPFN社(Preferred Networks)が開発したディープラーニング用のライブラリである。特徴であるDefine by Runは高く評価されている。Define by Runの特徴は、計算グラフの構築と同時にデータを流して処理を並行して実行する方式でデータ構造によってモデルを変えやすい。2019年12月、開発元のPFN社はChainerから、Facebookが主導開発しているPytorchに移行すると発表した。 |
| Pytorch | pythonのディープラーニング用のライブラリである。最初はFacebookの人工知能研究グループAI Research lab(FAIR)により開発された。PyTorchはフリーでオープンソースのソフトウェアであり、修正BSDライセンスで公開されている。 |
| scikit-learn | 機械学習全般に強いライブラリ。 機械学習のライブラリの1つで複数のトイデータセットが入っている。 ・アヤメの品種データセット ・ボストン市の地区別住宅価格データセット ・数字の手書き文字データセット ・糖尿病患者の診断データセット ・生理学的特徴と運動能力の関係のデータセット |
| scipy | scipyライブラリは、Pythonで配列や行列の演算などを扱うときに用いられるnumpyライブラリを内包しているため、統計などの高度な数学的計算を簡単に実行することができる。 |
| seaborn | データの可視化(グラフ作成)を行うライブラリ。 |
| Numpy | 線形代数の計算に強いライブラリ |
| OpenCV | 当初Intelが開発した画像認識ライブラリであり、2006年に1.0がリリースされ、2015年には3.0がリリースされている。 |
Colaboratory
Googleが提供する、ブラウザからPythonを記述し実行できるサービス。
PyCharm
JetBrainsが提供している、Pythonに特化した統合開発環境。
Jupyter Notebook
コードを1行ずつ実行しデータと結果を確認できるため、データを分析する用途で広く使われており、AI開発において多くの場面で利用できる。
7.5 実装・運用・評価
キーワード
本番環境での実装・運用、成果物を知的財産として守る、利用者・データ保持者の保護、悪用へのセキュリティ対策、予期しない振る舞いへの対
処、インセンティブの設計と多様な人の巻き込み著作物、データベースの著作物、営業秘密、限定利用データ、オープンデータに関する運用除外、秘密管理、個人情報、GDPR、十分性制定、敵対的な攻撃(Adversarial attacks)、ディープフェイク、フェイクニュース、アルゴリズムバイアス、ステークホルダーのニーズ
本番環境での実装・運用
PoC検証が終え十分に価値を生み出せる見積もりが取れたら本番環境での実装と運用になる。クラウドを使う場合はサービスをAPI化するなどで共有化したり、サーバの数を増やして負荷の分散などを計画。エッジの場合は遠隔でモデルを更新する仕組みを考える。故障した場合の運用体制などを考慮する。
成果物を知的財産として守る
収集・生成したデータや学習済みモデルは、一定の条件を満たせば著作権法での保護は難しいが、営業秘密や限定提供データ、知的財産として保護される余地がある。日本の知的財産制度上の取扱いとしては学習済みモデルの利用者に創作意図があり、かつ創作的寄与がある場合において著作物性が認められる。
データベースの著作物
著作物は「思想・感情」を「創作的」に「表現」したもの(著作権法2条1項1号)なので数値データは該当しないが、データの集合全体としてデータベースの著作物として保護される可能性がある(同法12条の2第1項)。学習用データセットは保護の対象になり得るが、ビッグデータなどはデータ選択の「創作性」が認められる可能性は低い。
営業秘密
営業秘密(不正競争防止法2条6項)は非公知性、有用性、秘密管理性の要件を満たせば保護されるが、気温のデータなどは公知なので非公知性を満たさない場合もある。オープンなコンソーシアムによる共同管理されたデータも秘密管理性を満たしにくい。ただし、2018年の法改正で限定利用データ(同法2条7項)が追加され、コンソーシアムによるデータ共有も保護の対象にはなった。
不正競争防止法等の改正により、データの利活用等を推進する環境整備が進んでいる。主要な措置事項として、ID・パスワードなどにより管理しつつ、相手方を限定して提供するデータを不正取得するなどの行為を新たに不正競争行為に位置付けている。
不正競争防止法における営業秘密とは①秘密管理性(社内で秘密データとして管理されているもの)、②有用性(事業のために有用な情報であること)、③非公知性(一般に知られている情報でないこと)の3つ。
限定提供データ
2018年に一部を改正し、2019年7月に施行された。この改正によって、「業として特定の者に提供する情報として電磁的方法により相当量蓄積され、及び管理されている技術上または営業上」が保護されるようになった。このような情報を「限定提供データ」という。限定提供データとし保護されるための要件は①限定提供性(特定の者に提供する情報であること)、②相当蓄積性(電磁的方法により相当量蓄積されていること)、③電磁的管理性(IDやパスワードなどの電磁的方法により管理されている)の3つ。
オープンデータに関する運用除外
不正競争防止法で「その相当量蓄積されている情報が無償で公衆に利用可能となっている情報と同一の限定提供データを取得し、又はその取得した限定提供データを使用し、若しくは開示する行為」と定義されている。
オープンデータに関する保護と利用のバランスが図られている。学習済みモデルをデータの組み込まれたプログラムとしてプログラムの著作物として保護できる余地があるが、ディープラーニングで自動的に生成されるパラメータ値だけを取り出した場合は(創作性などの観点から)著作物になるかどうかは議論が分かれる。学習モデルをデバイスに組み込むならば、暗号化や難読化の処理を施してリバースエンジニアリングを難しくするなどの秘密管理をすることも考慮できる。これによって営業秘密としての保護を受けるのと同様の効果が得られる。学習モデルをデバイスに組み込むのであれば、暗号化や難読化などの処理を施して、リバースエンジニアリングを困難にすることが多い。
オープンデータへの取り組み義務
学習用のデータ等は大量のデータを効率よく収集する必要がある。官民データ活用推進基本法により、国及び地方公共団体はオープンデータに取り組むことが義務づけされた。官民データ活用推進基本法(平成28年法律第103号)で、オープンデータへの取り組みが義務付けられ、オープンデータへの取り組み組により、国民参加・官民協働の推進を通じた諸課題の解決、経済活性化、行政の高度化・効率化等が期待されている。
AI・データの利用に関する契約ガイドライン
「蒸留」に対しては教師役のプログラムをコピーしているわけではないため従来の知財の保護は及ばない可能性があり、パラメータを盗んでいるわけでもないので不正競争防止法にも触れない可能性があるため、法制度上では判断が難しいのが知的財産権の保護である。実務では関係者間で契約を結び、権利の帰属、利用範囲、禁止行為を明示して一定の解決を図る、「AI・データの利用に関する契約ガイドライン」が重要となる。
利用者・データ保持者の保護
| 個人情報保護法15条1項 | 個人情報を扱う場合、利用目的をできる限り特定する必要がある。 |
| 個人情報保護法18条1項 | 実装段階でデータ利用目的が変わるなどしたら原則本人による事前の同意が必要(同法16条1項)で、 利用目的を本人に通知か公表しなければならない。 |
| 個人情報保護法20条 | 個人データの漏洩防止など安全管理措置を講じなければならない。 |
| 個人情報保護法21条 | 従業員の監督義務。 |
| 個人情報保護法22条 | 委託先の監督義務。 |
| 個人情報保護法19条 | データ内容の正確性の確保などに関する努力義務。 |
GDPR(EU一般データ保護規則)(General Data Protection Regulation) :
2018年5月にGDPRの運用が開始された、データ保持者の権利・利益を強化した規則。GDPRは日本に対しても適用されるため、EU向けにサービスを提供する日本企業も法的規制を受ける場合がある。
GDPRの特色として、あるサービスが特定のユーザに関して収集・蓄積した利用履歴などのデータを他のサービスでも再利用できるデータポータビリティの権利を認めている。2019年1月に日本とEUは相互に「個人データの移転を行うことができるだけの十分なデータ保護の水準をもつ」と合意した(十分性認定)。
故人のデータ利用
実演家や著作者の死後における人格的利益の保護(著作権法60条・同法101条の3)、パブリシティ権(名前、肖像、画像、音声の商業的な利用)、死後のプライバシー(post-mortem privacy)のほか、死者に対する宗教的崇敬感情にも配慮する。
「悪用」へのセキュリティ対策
システムを運用する際に様々な攻撃や想定外の振る舞いを考慮する。データ入力システムへの妨害、AIモデルの認識を混乱させる敵対的な攻撃(adversarial attacks)、システムに侵入しデータ・モデルの改竄・盗取や不正な実行、なりすまし、脆弱性を利用した不正アクセスなどがある。
対策としてシステム稼働を監視、通信相手の認証、アクセス制限、データの暗号化、データ改変の検知などがある。
ディープフェイク
ディープフェイクはディープラーニングとフェイク(偽物)を組み合わせた造語で、2018年に話題になったニュースでオバマ大統領がトランプは馬鹿だと発言する映像が話題となった。主にGANを用いて画像生成を行う。ポルノ生成や詐欺、偽物のスピーチ動画など技術の悪用したことによる逮捕者も出ており、社会的影響が懸念されている。
Snapchatに搭載されているFace Swap機能など。
予期しない振る舞いへの対処
AIはデータセットのバイアスを受けたりアルゴリズムの限界があるため、アルゴリズムバイアスよって画像分類で誤認識を生じたり、履歴書審査で性別による差別が起こるなどの解決が難しい課題もある。さらに名誉毀損の発言を取り除いたり、フェイクニュースなど偽りの情報が流れないようにチェックするのはAIには難しいケースもあるため、AIと人を組み合わせたプロセスの検討も必要。
過去にはインターネット上で意見交換をするフォーラムを運営・管理する側が、「フォーラムに他者の名誉を毀損する発言があることを知りながら措置を取らなかった」として不作為による不法行為の成立が認められた裁判例がある(東京高判平成13年9月5日。いわゆる「ニフティサーブ事件」)。
インセンティブの設計と多様な人の巻き込み
現場の利用者やプロダクトの影響・恩恵を受けるステークホルダーのニーズを把握することが重要であり、最先端の技術にとらわれず既存業務と調和したデザインを考える必要もある。
7.6 クライシス・マネジメント
キーワード
体制の整備、有事への対応、社会と対話・対応のアピール、指針の作成、議論の継続、プロジェクトの計画への反映、コーポレートガバナンス、内部統制の更新、シリアス・ゲーム、炎上対策とダイバーシティ、AI と安全保障・軍事技術、実施状況の公開、透明性レポート、よりどころとする原則や指針、Partnership on AI、運用の改善やシステムの改修、次への開発と循環
クライシス・マネジメント(危機管理)
危機を最小限に抑えて拡大を防ぐ「火消し」と、速やかに平常化と再発防止を目指す「復旧」が主眼。コーポレート・ガバナンス(corporate governance)や内部統制の更新を行い体制整備(外部有識者などで構成される委員会を設置したり監査体制を強化するなど)を行っている。
有事への対応
ソーシャルメディア等の口コミによるクライシスの発生しており、初動対応の前に憶測や風評被害が生じるたり、マスメディアが不安を煽るケースもある。その後の企業や研究機関の発信を受けても不満を感じやすく炎上しやすいため、クライシスの段階・規模に応じて機動的に対応することがより重要。
AIと安全保障・軍事技術に関する議論は日本や海外で行われており、特にAIを軍事利用した自律型致死兵器(Autonomous Weapons Systems、AWS)は人間の介入なしに対象を選定して攻撃を行うので大惨事を招きかねない。
| 2015年 | 人工知能国際合同会議(IJCAI)で非営利団体The Future of Life InstituteはAWS開発の禁止を求める公式書簡を公開した |
| 2017年 | 国連において自律型致死兵器システム(Lethal Autonomous Weapons Systems、LAWS)の研究開発を禁止すべきだとの議論が特定通常兵器使用禁止制限条約(CCW)の枠組みで開始された。 |
| 2019年1月 | 日本は人間の関与しない自律兵器を開発しないという立場を表明 |
人間中心のAI社会原則 詳細リンク
2019年に日本の内閣府が公開したAI戦略に関する指針。3つの基本理念は「人間の尊厳が尊重される社会(Dignity)」、「多様な背景を持つ人々が多様な幸せを追求できる社会(Diversity&Inclusion)」、「持続性ある社会(Sustainability)」と7つのAI社会原則からなる。
| 人間中心の原則 | AIは人間の能力を拡張であり、AI利用に関わる最終判断は人が行う |
| 教育・リテラシーの原則 | リテラシーを育む教育環境を全ての人々に平等に提供 |
| プライバシー確保の原則 | パーソナルデータの利用において、個人の自由・尊厳・平等が侵害されないこと |
| セキュリティ確保の原則 | 利便性とリスクのバランス、社会の安全性と持続可能性の確保 |
| 公正競争確保の原則 | 支配的な地位を利用した不当なデータの収集や主権の侵害があってはならない |
| 公平性、説明責任及び透明性の原則 | 不当な差別をされない、適切な説明の提供、AI利用等について、開かれた対話の場を持つ |
| イノベーションの原則 | データ利用環境の整備、阻害となる規制の改革 |
AI戦略2019(日本)詳細リンク
「人間尊重」「多様性」「持続可能」の3つの理念を掲げ、Society5.0を実現し、SDGsに貢献3つの理念を実装する4つの戦略目標を設定 。
| 戦略目標Ⅰ | 人材 | 人口比において最もAI時代に対応した人材を育成・吸引する国となり、持続的に実現する仕組みを構築。2025年には、エキスパート人材を年に2,000人育成する目標を掲げている。 |
| 戦略目標Ⅱ | 産業競争力 | 実世界産業においてAI化を促進し、世界のトップランナーの地位を確保。 |
| 戦略目標Ⅲ | 技術体系 | 理念を実現するための一連の技術体系を確立し、運用するための仕組みを実現。 高校過程で2022年から「情報Ⅰ」を必修とすることを掲げている。 |
| 戦略目標Ⅳ | 国際 | 国際的AI研究・教育・社会基盤ネットワークの構築。 |
社会と対話・対応のアピール
プライバシーやセキュリティの実施状況を公開を通して社会に対して対策のアピールし責任説明を果たすことが重要となるため、個人情報を扱う企業は透明性レポートなどをウェブ上などに公開し透明性を担保している。例えばTwitter社やGoogle社を始めとするいくつかの個別企業などは透明性レポート(ユーザーからの情報開示請求や削除請求、政府からのコンテンツの削除要求など)をwebで公開している。
日本では、業界として自治を行う一般社団法人セーファーインターネット協会(safer internet association、SIA)が透明性レポートの公開やサイトパトロールを行なっていおり、削除要請のあった違法・有害情報の9割以上が削除された実績を持つ。
透明性レポート
ユーザーの個人情報をどのように収集、利用、保護するかについて企業の基本的な方針を示すレポート。
指針の作成
個人、企業、政府などが拠り所とする原則や指針が必要となる。
| 2015年 | 米国政府は「A Strategy for American Innovation」を策定した。 |
| 2016年 | AI の研究や検証、実動におけるベストプラクティスを開発したり共有したりすることを目的として、Amazon、Google、Facebook、IBM、MicrosoftなどアメリカIT企業を中心として、PAI(Partnership on AI)が組織された。 |
| 2017年 | 中国は「次世代人工知能発展計画」を発表した。 |
| 2017年2月 | NPO法人Future of Life Instituteが安全性の検証や透明性の確保など23項目からなる「アシロマAI原則」を公開。 |
| 2018年 | EU一般データ保護規則であるGeneral Data Protection Regulation運用開始された。 |
| 2018年 | 欧州委員会は「Coordinated Plan on Artificial Intelligence」を発行した。 |
| 2019年4月 | 学術団体IEEEが「倫理的に調和された設計」を公開。 |
| 2019年4月 | 欧州委員会が「信頼性を備えたAIのための倫理ガイドライン」を公開。 |
| 2019年5月 | 中国が「北京AI原則」を公開。 |
| 2019年5月 | 日本内閣府が「人間中心のAI社会原則」を公開。 |
| 2020年2月 | 欧州委員会が「AI白書」(AIの規制の枠組みの方向性)を公開。 |
| 2020年1月 | アメリカ政府が「民間部門におけるAI技術の10項目の原則」を公開。 |
このほか、シンガポールやドバイなどは具体的なセルフチェック項目やベストプラクティスを含んだ報告書を公開している。
プロジェクトの計画への反映
AIシステムは作ったら終わりではなく、得た教訓を運用の改善やシステムの改修や次の開発へと循環させていくサイクルが重要となる。想定外の事故を起こさなためにも、「このAIシステムで支援や影響を受けるのは誰か」、「想定外のユーザーはいないか」、「判断や最適化を行う時の基準は何か」、「判断や最適化などを機械で行うことの正当性はどんな根拠に基づいているのか」、「AIシステムやサービスを、現在の文脈以外に悪用される危険性はあるか、それを防ぐ対策は取られているか」といった点に留意する。
8. 数理・統計
キーワード
統計検定3級程度の基礎的な知識、統計検定3級程度の基礎的キーワードと計算問題
統計学
統計学は次の2つに大別できる。機械学習では「推計統計学」と密接に関わっている。
| 記述統計学 | 手元のデータの分析を行う |
| 推計統計学 | データの背後にある母集団の性質を予測する |
ヒストグラム
ヒストグラムはある幅にどれくらいのデータ数があるかを可視化したい場合に使用する。おおよそ、だいたい、といった正確でなく大まかな傾向を知るために使う。
散布図
散布図は縦軸と横軸の二つの特徴量によりデータの点を打つ図表である。散布図を使用すると2変数の相関を確認することができる。
決定係数
重回帰分析には決定係数というものがあり、決定係数とはモデルの予測値と実際の値のズレによって決まる。ズレが小さいほど決定係数は1に近づき良いモデルと考えられる。
転置行列
ある行列Aに対して Aの(i, j)要素と(j, i)要素を入れ替える行列をいう。転置後も行列式の値は変わらず、転置の逆行列と逆行列の転置は同じ行列となる。
t分布
t分布は連続確率分布の一つであり、正規分布する母集団の平均と分散が未知で標本サイズが小さい場合に平均を推定する問題や、2つの平均値の差の統計的有意性を検討するt検定でも利用され、スチューデントのt分布とも呼ばれる。自由度によって分布の形が変化する。
尺度
| 尺度 | 使用事例 | 特徴 |
|---|---|---|
| 名義尺度 | 郵便番号 | 個々のデータを識別するための名称や固有番号で、数値としては意味は持たないため数値計算はできない |
| 順序尺度 | 順位 | 大小関係や順序には意味があるが、感覚や比率としては意味は持たないため数値計算はできない |
| 間隔尺度 | 気温 | 目盛が等間隔になっておりその間隔に意味がある尺度。 |
| 比例尺度 | 身長 | 間隔に加えて比率にも意味がある尺度。 |
箱ひげ図
データのばらつきを示すグラフ。一般には四分位数(第一四分位数・中央値・第三四分位数)、最大値、最小値などを用いて箱ひげ図を作成する。
編相関係数
疑似相関を測る時に使用する。2つの変数の相関が第3の変数によって高められるまたは低めれらる場合に、第3の変数の影響を取り除いて求めた相関係数である。
ベイズの定理
P(B|A)=P(A|B)P(B)/P(A)
ベイズ推定
ベイズ確率の考え方に基づき、観測事象から推定したい事柄を確率的な意味で推論すること。
9. 関連情報(シラバス外・時事ネタ等)
単語集
Googleの猫
Google社が2012年に大量の画像データから「猫」を抽出し、その隠れ層では猫の概念と思われる画像が抽出された。これにより、当時はコンピュータがディープラーニングにより意味を理解できたと考えられた。
みにくいアヒルの子の定理
何らかの「仮定(事前知識や偏向、帰納バイアス)」がないと「分類(類似性の判断)」は不可能であるということを主張する定理である。つまり分類やパターン認識において、あらゆる特徴量を客観的に同等に扱うことはできず、何らかの仮定に基づいて主観的に特徴量選択を行うことが本質的に必要であることを示す。
モラベックのパラドックス
人間にとって簡単なことほど機械がやるのは難しいと呼ばれる考え。「明日の利益を予測する」「ゲームをクリアする」といった大人が行うような高度な知性に基づく推論よりも、例えば「おもちゃで遊ぶ」「興味深いものに注意を払う」といった1歳児が行うような本能に基づく運動スキルや知覚を身に付ける方がはるかに難しいというパラドックスをいう。
End-to-End Learning
ディープラーニングはロボット学習への応用も盛んに行われており、大きな影響をもたらせた。これはある一連の動作を学習する際に従来は一つ一つの動作をステップバイステップで学習していたものを、一つのネットワークとして表現することで全動作を一気に学習することが可能になったのが非常に大きいとされている。
常識推論
自然言語処理においては学際的な研究が進められている。その一つとして、機械が知能を持っているか否かを判断することを目的とした知能テストが多数考案されており、常識推論タスクとして注目を浴びている。
スパースモデリング
あるデータにおいてほとんど0であり、稀に1が現れる形になっているデータをスパースなデータと呼ぶ。この性質を用いて計算量の削減を行うモデルをスパースモデルという。
デジタルトランスフォーメーション(DX)
2004年にエリック・ストルターマンが「ITの浸透が、人々の生活をあらゆる面でより良い方向に変化させる」をデジタルトランスフォーメーションと定義した。日本おいても経済産業省がデジタルトランスフォーメーションを推進するためのガイドラインなどを整備している。
Society5.0
日本政府はSociety5.0と呼ばれる仮想空間と現実空間を高度に融合させたシステムにより、経済発展と社会的課題の解決を両立する人間中心の社会を提唱した。
COPA
南カリフォルニア大学のAndrew Gordonの研究グループが提案したのが COPA (Choice of Plausible Alternatives)。これは「知能を持つ」ことが事象間の因果関係を理解することだと捉え、これを計測しようとしたものである。
WAC
Hector Levesqueの研究グループが定式化した 「統語的手がかりだけでは解けないような照応解析の問題が解けること」が知能を持つこととしてこれをテストの形にした。現在このテストはAIのトップ会議でコンペティションが開かれるなどしており、まだまだ精度は低いものの注目を浴びつつある。
ボルツマンマシン
1985年、ジェフリー・ヒントンらによって確率的に動作するニューラルネットワークの一種。各変数間の依存関係をグラフとして表現したモデルで、ボルツマン分布を用いる確率的回帰結合型ニューラルネットワークのこと。ホップフィールドネットワークとも呼ばれるネットワークの一種である。学習の際に最尤推定をおこなってデータに当てはめる確率分布を推定する。
回帰のモデルの汎化誤差
誤差関数を二乗誤差としたとき、回帰のモデルの汎化誤差はの三つの要素に分解できる。
| バリアンス(variance) | モデルが複雑になりすぎて過学習の状態にある時に高くなる。 |
| バイアス(bias) | 逆に単純すぎて未学習の状態にある時に高くなる。 |
| ノイズ(noise) | データ自体に混入しておりモデルの種類や学習方法を工夫しても取り除くことは困難。 |
Ponanza
深層学習を用いた将棋AI。
DeepFace
Facebookの研究グループらが2014年に公表したディープラーニングを用いた顔認識システム。
GNMT
Googleは2016年からディープラーニングを用いたGNMTを用いて、Google翻訳の精度を向上させた。現在機械翻訳の精度が高いとして評価が高く、従来のモデルに比べて言葉の流麗さが増したと言われている。
AlphaFold
Alphabet傘下のDeepMindは、AIを使ってタンパク質の構造を見出し新薬開発に活かすAlphaFoldを開発しCASP13コンテストで優勝した。
イルダ
女性をイメージしたチャットボットAIであるイルダは2020年末に韓国で公開されたが、利用者によるセクハラの会話が問題となった。性的少数者に対して差別的な発言を行うとして公開からわずか3週間で停止に至った。
Tay
Microsoft社が開発したチャットボットAI。特定の政党の賞賛を行うなど政治的な発言をしたため、停止に至った。
KLダイバージェンス
2つの確率分布がどの程度似ているかを表す尺度。非負の値をとり、2つの確率分布が同じ場合に値は0となる。
WER
音声認識技術の一般的な評価尺度として用いられる。この値をいかに下げるかということを目標に研究開発競争が繰り広げられており、ィープラーニング技術の向上により飛躍的な精度向上を果たしている。
MAML
メタ学習のアルゴリズムの1つ。更新後の目的関数の値の和が小さくなるように初期パラメータを決定する、最適化処理において、勾配の勾配を求める、回帰、分類、強化学習等のタスクに適用可能であるという特徴がある。
コサイン類似度
2つのベクトル間の類似度の指標で、-1~1の範囲をとる。
ニューラル常微分方程式
ResNetの課題にあった多くのメモリと時間を要する課題にを解決するため、中間層を微分方程式で捉える手法であり、NIPS2018のベストペーパーに選ばれた。
データクレンジング
データベースなどに保存されているデータの中から、重複や誤記、表記の揺れなどを探し出し、削除や修正、正規化などを行ってデータの品質を高めること。
敵対的攻撃(Adversarial attack)
微弱なノイズをデータに混入させ、それにより人工知能の判断を誤らせる攻撃のことを敵対的攻撃といい、敵対的攻撃において用いられるデータを敵対的事例という。パンダとして正しく認識されていた画像に微弱なノイズを混ぜることでテナガザルと認識させてしまう事例が有名。
敵対的攻撃の防御策として学習データにあらかじめ敵対的事例を混ぜて学習させる敵対的学習や入力が敵対的事例かどうかを判別するニューラルネットワークをあらかじめ作っておくADN(Adversary Detector Network)がある。ネットワークの活性化関数にk-WTA(k-Winners-Take-All)を用いると敵対的攻撃に強いモデルが得られることがわかっている。
ARIMA(autoregressive integrated moving average)
時系列データの解析手法で非定常過程のデータに対して適用できるのが大きな特徴。自己回帰モデル(ARモデル)、移動平均モデル(MAモデル)、和分モデル(Iモデル)の3モデルを組み合わせたモデルで、自己回帰和分移動平均モデルとも呼ばれる。
SARIMA(Seasonal AutoRegressive Integrated Moving Average)
時系列データの解析手法でARIMAモデルに「季節的な周期パターン」を加えたモデル。
CIFAR〈詳細〉
主に画像認識を目的としたディープラーニングのチュートリアルで使われているデータセット。CIFAR-10は10クラス(種類)の5万枚の訓練データ用(画像とラベル)1万枚のテストデータ用(画像とラベル)からなる。100クラスのCIFAR-100もある。
Fashion-MNIST
学習用に6万枚、テスト用に1万枚用意された10種類に分類できる衣類品画像のデータセット。
SI接頭語
| 接頭語 | 記号 | 10^n |
| ヨタ | Y | 24 |
| ゼタ | Z | 21 |
| エクサ | E | 18 |
| ペタ | P | 15 |
| テラ | T | 12 |
| ギガ | G | 9 |
| メガ | M | 6 |
| キロ | k | 3 |
| ヘクト | h | 2 |
| デカ | da | 1 |
| デシ | d | -1 |
| センチ | c | -2 |
| ミリ | m | -3 |
| マイクロ | μ | -6 |
| ナノ | n | -9 |
| ピコ | p | -12 |
| フェムト | f | -15 |
| アト | a | -18 |
| ゼプト | z | -21 |
| ヨクト | y | -24 |
技術同行・時事ネタ
Google Scholar(グーグルスカラー)
学術論文の検索エンジン。
Kaggle(カグル)
データ解析のコンペティションやデータサイエンスによるディスカッションが行われるプラットフォーム。
Coursera(コーセラ)
世界中の大学の講義を受講できるオンライン講座。
arXiv(アーカイブ)
研究論文の公開・閲覧ができるWebサイト。
OpenAI
2015年に設立された人工知能を研究する非営利団体。イーロン・マスクらアメリカの起業家や投資家などが参加し、2016年にOpenAIGymの提供をはじめた。
OpenAI Gym
自分で製作した強化学習用アルゴリズを試験できるAIシミュレーションプラットフォーム。
中国の主要IT3社「BAT」
「Baidu」・「Alibaba」・「Tencent」
中国製造2025
2015年5月に中国政府から発表された2025年までの中国国内の製造業発展のロードマップで2049年までの発展計画が3段階で表されている。ドイツの産業プロジェクトであるインダストリー4.0の中国版と言われている。
LOD
LODは、ウェブ上でコンピュータ処理に適したデータを公開・共有する方法であり、wikipediaをLOD化したDBpediaも作られている。
MAAS
「ICTを活用してマイカー以外の移動をシームレスにつなぐ」という概念。
Define-by-Run
ニューラル設計を動的に行うことができる。計算グラフの構築と順伝播処理の実行が同時に行える。
トロッコ問題
「ある人を助けるために他の人を犠牲にするのは許されるか?」という形で功利主義と義務論の対立を扱った倫理学上の課題。自動運転などのAIに関する倫理観の議論となる問題の1つである。
Adversarial Examples
人間では認識しづらいが、AIが認識を誤るような情報を加えたデータのこと。
API化
自然言語処理に関わるAIタスクは毎回一からシステムを作り上げる必要がある。たとえば少しのタスク追加、もしくは削減を行う場合でも一から再設計する必要がある。これに対して、自然言語処理で使用するタスクに対応するAPIを作成することで、事実上すべての自然言語処理関係のタスクをAPIの呼び出し・組み合わせで構築することが可能になった。たとえばOpenAIでは自然言語処理系AIの汎化の例としてGPT-3(1,750億のパラメータを調整した自然言語処理系)にアクセス可能となっている。さらにGPT-3を使用する/予定のある商用アプリケーションのショーケースも公開されている。
AutoML(Automated Machine Learning)
AutoMLでは機械学習の各プロセスを自動化してエンジニアの生産性を向上させ、誰でも機械学習を使えるようになることを目指した技術のこと。企業内のデータサイエンティストの不足を補ったり、AIの知識がない人材でも機械学習による成果をえたりすることが可能となる。具体的にはAutoMLでは大きく「ハイパーパラメータチューニング」「モデル選択」「特徴エンジニアリング」の3点を行う。
データサイエンティストに求められるスキルセット
データサイエンススキル、データエンジニアリングスキル、ビジネススキルの3つ。
| データサイエンススキル | 情報処理、人工知能、統計学などの情報科学系の知識を理解し活用する力。 |
| データエンジニアリングスキル | データサイエンスを意味のある形に使えるようにし、実装、運用できるようにする力。 |
| ビジネススキル | 顧客企業が抱えるビジネス課題を整理し解決に導くためのスキル「マネジメントスキル」「コミュニケーションスキル」「ドキュメンテーションおよびプレゼンテーションスキル」などがある。 |
AI関連の国際会議・学会
AAAI(Association for the Advancement of Artificial Intelligence)
1979年に「American Association for Artificial Intelligence"」として設立され、2007年に 「Association for the Advancement of Artificial Intelligence」 と改称された。世界中に6,000人以上の会員がいる。アレン・ニューウェル、エドワード・ファイゲンバウム、マービン・ミンスキー、ジョン・マッカーシーといった著名な計算機科学者が初期の会長を歴任した。AAAI は人工知能分野全体をカバーする AAAI Conference と IJCAI の他に、数々の分野にわかれた国際会議を開催している。
CVPR(Conference on Computer Vision and Pattern Recognition)
コンピュータビジョンとパターン認識に関する会議(CVPR)はコンピュータビジョンとパターン認識に関する年次会議のことで画像認識を主にテーマとしている学会。
NeurIPS(Conference and Workshop on Neural Information Processing Systems)
毎年12月に開催される機械学習と計算論的神経科学の会議。ニューラルネットワーク技術を主にテーマとしている学会であるが、近年は機械学習をテーマにした発表が増加している。
ICML(International Conference on Machine Learning)
機械学習における主要な国際学術会議で、 NeurIPSやICLRと並んで機械学習と人工知能の研究に大きな影響を与える3つの主要な会議の1つ。
自動運転
自動運転に関する法律(SAE J 3016)
自動運転にはその度合いに応じてレベルが定義されており、アメリカのSAEインターナショナルによって定義された「SAE J 3016(2016)」が世界共通基準となっている。
| レベル0 | 運転自動化なし | 運転者が全ての運転操作を実行する |
| レベル1 | 運転支援 | システムがアクセル・ブレーキまたはハンドル操作のいずれかを条件下で部分的に実行。 |
| レベル2 | 部分運転自動化 | システムがアクセル・ブレーキまたはハンドル操作の両方を条件下で部分的に実行。 |
| レベル3 | 条件付運転自動化 | システムがすべての運転操作を一定の条件下で実行。作動継続が困難な場合は、システムの介入要求等に運転者が適切に対応。2021年3月にレベル3相当の車が市販されている。 |
| レベル4 | 高度運転自動化 | システムがすべての運転操作及び作動継続が困難な場合への対応を一定の条件下で実行。 |
| レベル5 | 完全運転自動化 | システムがすべての運転操作及び作動継続が困難な場合への対応を条件なしで実行。 |
日本の自動運転の法律現状
日本では2020年4月に道路交通法と道路運送車両法が改正され、レベル3の自動運転で公道の走行が可能となった。高速道路など一定の条件の下であれば、システムからの運転引き継ぎを要請されている時などを除き、運転者がハンドルから手を離してシステムに運転を任せれるようになった。2025年を目処にレベル4の完全自動運転システムの実用化が見込まれている。なお、アメリカのカリフォルニア州ではすでに無人自動運転車の走行が認められている。
自動運転と道路交通法
自動運転の自動車が公道を安全に走行できるように改正された主なポイントは「1.自動運転装置による走行も「運転」と定義」、「2.自動運転装置を使う運転者の義務」、「3.作動状態記録装置による記録を義務付け」の3つ。
| (1)自動運転装置による走行も「運転」と定義 |
| 自動運行装置とは自動運転システムのことで、これまで運転者が担っていた認知・予測・判断・操作の全てを代替できる機能を持ち、その作動状態を記録する装置を備えたもので、この自動運行装置を使い公道を走行することも「運転」と決められた。この定義が追加されたことで、レベル3の自動運転ができるようになった。 |
| (2)自動運行装置を使う運転者の義務 |
| 自動運転中に車種ごとに定められている条件から外れてシステムから警報が鳴るなどした場合は、直ちに運転者は通常の運転に戻らなければならないため、直ちに通常の運転に戻れないと考えられる飲酒や居眠りは認められていない。自動運転中に事故・違反があったとしても、必ずしも運転者が免責されるとはかぎらない。 |
| (3)作動状態記録装置による記録を義務付け |
| 車両の保有者等は自動運行装置の作動状態を記録し保存することが義務付けられる。道路交通法令に反する動きをしたことなどを現場の警察官が認めた場合に自動運行装置が作動中か否かを確認することで、交通の危険の防止などに役立てられる。警察官から記録の提示を求められた場合には、この記録を提示する必要がある。 |
ドローン
ドローンに関する法律
ドローン規制単独の法律は存在せず、最も重要な法令は航空法(国土交通省)と小型無人機等飛行禁止法(警察庁)。
航空法の規制空域
(A)空港等の周辺の上空の空域、(B)緊急用務空域、(C)150m以上の高さの空域、(D)人口集中地区の上空を規制対象としこれらの空域でドローンを飛行させる場合には国土交通大臣の許可を要すると定めている。
航空法により禁止・遵守が求められる規制
| 飲酒時の操縦禁止 | アルコールまたは薬物の影響により正常な飛行ができないおそれがある間は、ドローンの飛行は禁止される(飲酒時の操縦禁止) |
| 飛行前点検の遵守 | 飛行に支障がないこと、その他飛行に必要な準備が整っていることを確認した後でなければ無人航空機を飛行させることはできない(飛行前点検の遵守)。 |
| 衝突予防の遵守 | 無人航空機を飛行させるに当たっては、航空機・他の無人航空機との衝突を予防する措置を採ることが求めらる(衝突予防の遵守)。 |
| 危険な飛行の禁止 | 飛行上の必要がないのに高調音を発し、急降下するなど他人に迷惑を及ぼすような飛行方法は禁止(危険な飛行の禁止)。 |
国土交通大臣の承認を要する規制
| ⑤夜間飛行の禁止(日中での飛行) | ドローンを安全に飛行させるためには、見通しのきかない夜間よりも日中の飛行が望ましい。国土交通大臣の承認がない限りドローンの夜間飛行を禁止している(夜間飛行)。 |
| ⑥目視外飛行の禁止(目視の範囲内) | ドローンの位置と周囲の状況を把握する上で、自分の目で把握することが望ましい。国土交通大臣の承認がない限り、目視できない状況下でのドローン飛行を禁止している(目視外飛行)。 |
| ⑦30m未満の飛行の禁止(距離の確保) | ドローンと人・物件との距離が近くなればなるほど、衝突の危険性は高まるため、国土交通大臣の承認がない限り、人又は物との距離が30m未満に接近するドローンの飛行を禁止しています(30m未満の飛行)。 |
| ⑧催し場所での飛行禁止 | 多数の人が集まる催しが開かれている場所でのドローンの飛行は、人との接触の危険性も、落下により人に危害を及ぼす危険性も高まる。国土交通大臣の承認がない限り、多数の人が集まる催しの上空でのドローンの飛行についても禁止している(イベント上空飛行)。 |
| ⑨危険物輸送の禁止 | ドローンが危険物を輸送する場合、危険物の漏出や危険物の爆発によるドローンの墜落という危険を伴う。国土交通大臣の承認がない限り、ドローンで危険物を輸送することを禁止している(危険物輸送)。 |
| ⑩物件投下の禁止 | ドローンから物件を投下する場合、下にいる人へぶつけたり、ドローン自体がバランスを崩して墜落したりする恐れがある。国土交通大臣の承認がない限り、ドローンから物件を投下する行為についても禁止している(物件投下)。 |
| レベル1 | 無人、有人地帯を目視内での操縦による飛行可能 | 見える範囲で手動操作する一般的なドローン利用の形態を指す。農薬散布や映像コンテンツのための空撮、橋梁や送電線といったインフラ点検などがこのレベルに該当する |
| レベル2 | 無人、有人地帯を目視内での自律飛行可能 | 見える範囲で自動運転機能を活用した飛行を行うものを指す。例としては、空中写真測量やソーラーパネルの設備点検などが挙げられる |
| レベル3 | 無人地帯を目視外での操縦による飛行と自律飛行可能(補助者の配置なし) | 住民や歩行者らがいないエリアにおいて目の届かない範囲まで飛行する形態を指す。離島や山間部への荷物配送、被災状況の調査、行方不明者の捜索、長大なインフラの点検、河川測量などがこれに該当する。 |
| レベル4 | 有人地帯を目視外での操縦による飛行と自律飛行可能(補助者の配置なし) | 有人地帯(第三者上空)、市街地などを含めたエリアにおいて目の届かない範囲まで飛行する形態を指す。都市の物流や警備、発災直後の救助、避難誘導、消火活動の支援、都市部におけるインフラ点検などがレベル4として考えられる。 |
ロボティクス
ロボティクス
ロボティクスとは「制御などのロボットに関する一連の研究分野」の総称で、機械学習技術の導入が進んでいる。
ロボットの動作制御ではモンテカルロ法やQ学習などの強化学習が利用されている。
一気通貫学習
ロボットの一連動作を1つのDNNで実現させるための学習方法。
マルチモーダル
人間の五感や平衡感覚、空間感覚などの複数の感覚情報を組み合わせて処理することをマルチモーダル情報処理という。
ロボットの不法行為責任
AIを搭載したロボットが危害を加えてしまった場合、AIそれ自体に不法行為責任を負わせることは難しく、責任はAIの所有者になると考えられる。所有者に民法上の不法行為責任が認められるたには所有者に故意または過失という要件が必要。
製造物責任法第3条に基づく法的責任が認められるための要件として「欠陥」がある。
完全自律型兵器(LAWS)
2018年に、KAISTらがAI を活用した自律型兵器の開発などを推進していると発表している。2019年、ジュネーブにおいてLAWSに関する特定通常兵器使用禁止制限条約(CCW)の政府専門家会合(GGE)が開催され、今後の議論の進め方を含む報告書案がコンセンサスでまとまった。2021年には特定通常兵器使用禁止制限条約(CCW)の枠組みにおけるLAWSに関する政府専門家会合(GGE)が開催されることに加え、11項目からなるLAWSに関する指針について一致した。日本でもLAWS は軍事分野で銃の発明、核兵器の開発に続く第三の革命になるとして「国際人道法や倫理上の観点から到底看過できない」 と政府に対して警鐘を鳴らす学者などの意見が発表されている。
完全自律型兵器とは①HUman on the Loop weapons(ロボットが標的を選択し攻撃できるが、人間がロボットの動作を無効にできる)、②Human out of the Loop Weapons(ロボットが人間の命令や関与なしに標的を選択し攻撃できる)と定義されている。

